



 本文介绍了POSTGRESQL数据库中几乎引发的冻结炸弹情况,分析了冻结炸弹的原理,强调了回收事务ID的重要性。讨论了autovacuum参数如vacuum_freeze_min_age和autovacuum_freeze_max_age的调整,以及针对大表的特殊设定、手动VACUUM操作、DDL操作的影响和长时间运行SQL的监控。建议包括定期检查frozen_xid_age和consumed_txid_pct,以及监控autovacuum进程,以防止冻结炸弹的发生。
本文介绍了POSTGRESQL数据库中几乎引发的冻结炸弹情况,分析了冻结炸弹的原理,强调了回收事务ID的重要性。讨论了autovacuum参数如vacuum_freeze_min_age和autovacuum_freeze_max_age的调整,以及针对大表的特殊设定、手动VACUUM操作、DDL操作的影响和长时间运行SQL的监控。建议包括定期检查frozen_xid_age和consumed_txid_pct,以及监控autovacuum进程,以防止冻结炸弹的发生。

POSTGRESQL 的冻结炸弹💣,大多是只听说过,没有遇到过,实际上想遇到冻结炸弹也是不容易。最近差点发生一次冻结炸弹,惊险之余的总结一下怎么不在差点发生这个问题。
关于冻结炸弹的原理,文章很多,这里不进行赘述,先说说事情发生的情况,收到报警,发现数据库最大age xid 的告警,随即通过pg_stat_activity查询发现有大量的查询语句运行时间过长,并且一直未停止,随即进行查杀,将这些语句查杀后,报警停止。
随即开始反思到底有哪里没有做到位
在梳理之前我们需要在简单的重复一下,PG 这部分的原理。
1 PG MVCC 寄生与行中,行中有每个行属于哪个事务的标记,以及行在后期经过delete 或 update 后的事务标记, xmin, xmax 字段。事务ID 本身是 2的 31次方,大约可以使用的事务ID 是 42亿, 而事务ID 是有数据量的,不能一直使用下去,所以必须进行回收,回收与AUTVACUUM 和 VACUUM 有关。

其中通过参数vaccum_freeze_min_age 来设置回收的工作点,凡是死行,同时死行中的事务ID对于 vacuum_freeze_min_age 设置的参数对比后老于这个值,则这个事务ID 进入了 FrozenXID.
另一个问题是什么时候触发这个工作的进行,也就是将老的XID 进行 Frozenxid 的操作,我们还有一个参数autovacuum_freeze_max_age
触发操作 举例如果我们的 autovacuum_freeze_max_age 设置的为2亿
而我们的vacuum_freeze_min_age 为 5000万,那么每次当两个值相减后与当前的事务ID 比较超过 1.5亿就要开始进行 Frozen 的工作了。
实际上对于动态表,经常进行Autovacuum 这个事情并不重要,而对于静态表来说,这才是重要的问题,基于autovacuum永远不会扫到这样的表。
1 从参数看,是否有改进的地方
1.1 vacuum_freeze_min_age
这个 vacuum_freeze_min_age 的功能可以通过一个图来进行表述,整体我们有42亿的txid, 我们有一半的TXID 是被隐藏的,一半是使用的,在这样的状态下,我们需要不断的回收 TXID,在这样的情况下我们不断回收的标准是什么,这是一个问题。每张表都需要回收TXID ,那么距离上次回收多长时间会进行下一次的TXID 的回收。如图,一个圆里面的开口的那段就是这一次和上一次之间的距离,而 vacuum_freeze_min_age 就是开口的可以承受的最大的距离。
提高这个值,保证预留的TXID 会更多,避免发生FREEZMING BOOM 的风险。
同时用FROZENXID 替换记录中的xmin

#vacuum_freeze_min_age = 50000000
默认值为 5000万,这个值设置的越小,针对I/O 和 CPU的影响会越大,但对于系统来说更积极的回收有利于尽快回收事务ID
2 老生长谈的 autovacuum 触发机制的参数,说这方面的文字很多,这里不赘述简单的几条来概括
2.1 必须对系统中的大表有认识,并且针对大表的autovacuum 的每个参数进行特殊的设定,必须及时的进行 autovacuum 的操作,而不是使用系统默认的设置。

3 在系统不繁忙的情况下,一定要定期的针对系统进行VACUUM 的手动操作,尤其针对分析出的系统中的大表进行操作。
4 针对超级大表,可以进行分区的操作,这样有利于autovacuum 的运行和效率。
5 针对大表的DDL 操作对于AUTOVACUUM 的影响的问题,这点也是需要重视的,DDL 操作会导致autvacuum 操作被推迟,所以针对大表的DDL 尽量在业务不繁忙时间进行,并且在针对某些大表操作后,需要尽快进行VACUUM 的操作。
6 积极发现系统中存在的长时间无法工作完的语句,举例发现长达5分钟还未完毕的语句,针对超过10分钟的没有完成的语句进行记录和展示
SELECT datname, pid, client_addr,
now() - xact_start AS duration,
now() - state_change AS time_idle,
query
FROM pg_stat_activity
WHERE now() - state_change > INTERVAL '10 minutes'
AND now() - xact_start > INTERVAL '10 minutes';
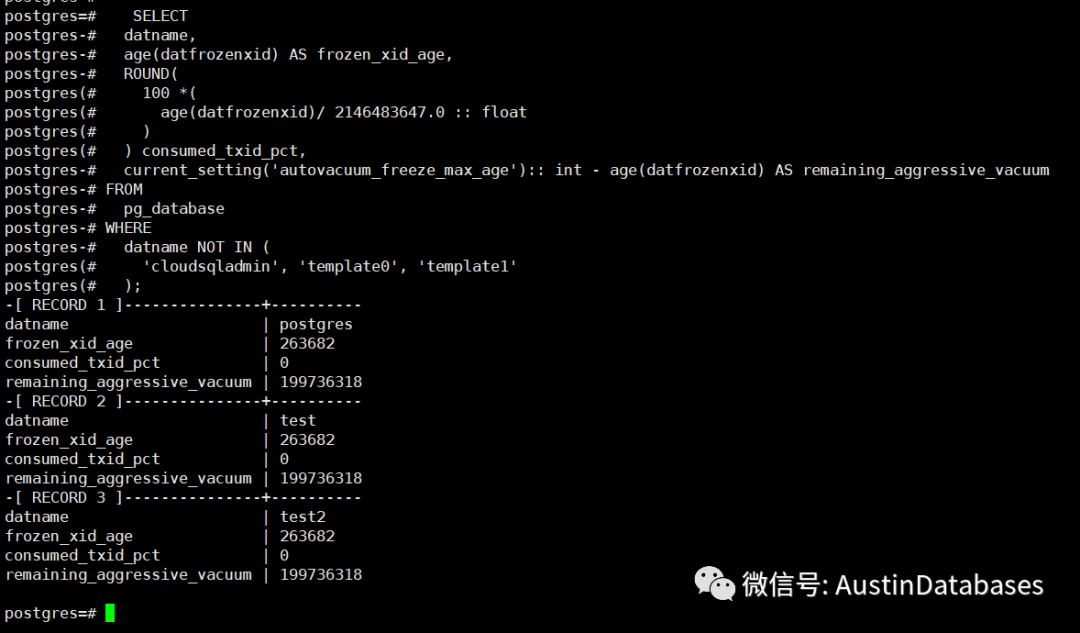
7 检测库中的 frozen_xid_age ,以及consumed_txid_pct 的消耗的情况,和将要发生 aggressive_vacuum的 情况等
SELECT
datname,
age(datfrozenxid) AS frozen_xid_age,
ROUND(
100 *(
age(datfrozenxid)/ 2146483647.0 :: float
)
) consumed_txid_pct,
current_setting('autovacuum_freeze_max_age'):: int - age(datfrozenxid) AS remaining_aggressive_vacuum
FROM
pg_database
WHERE
datname NOT IN (
'cloudsqladmin', 'template0', 'template1'
);
同时也可以监控当前那些表正在进行autovacuum
SELECT p.pid,
p.datname,
p.query,
p.backend_type,
a.phase,
a.heap_blks_scanned / a.heap_blks_total::float * 100 AS "% scanned",
a.heap_blks_vacuumed / a.heap_blks_total::float * 100 AS "% vacuumed",
pg_size_pretty(pg_table_size(a.relid)) AS "table size",
pg_size_pretty(pg_indexes_size(a.relid)) AS "indexes size",
pg_get_userbyid(c.relowner) AS owner
FROM pg_stat_activity p
JOIN pg_stat_progress_vacuum a ON a.pid = p.pid
JOIN pg_class c ON c.oid = a.relid
WHERE p.query LIKE 'autovacuum%';最后简单总结一下,POSTGRESQL 冻结炸弹如果发生是一件很可怕的事情,实际上如果对运行的SQL 进行时间的检测和控制,尤其不要在一个系统中进行大量,频繁的OLAP 操作,POSTGRESQL 本身也不容易发生冻结炸弹。


















 2215
2215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









