



 POSTGRESQL通过TUPLE结构实现事务处理和并发控制,不依赖UNDO/REDO日志。t_xmin和t_xmax字段记录事务ID,用于多版本控制(MVCC),避免数据读写冲突。当事务ID达到32位限制时,需要清理DEAD TUPLES以防止数据库FREEZE。这种机制使数据始终存于数据表,简化了事务管理和空间占用。
POSTGRESQL通过TUPLE结构实现事务处理和并发控制,不依赖UNDO/REDO日志。t_xmin和t_xmax字段记录事务ID,用于多版本控制(MVCC),避免数据读写冲突。当事务ID达到32位限制时,需要清理DEAD TUPLES以防止数据库FREEZE。这种机制使数据始终存于数据表,简化了事务管理和空间占用。

其实这篇的的起因是源于一个问题,为什么POSTGRESQL 没有UNDO REDO,没有这样的表空间到底他怎么进行事务与相关的并发机制的。所以这篇可能会伴随着枯燥乏味。
这个问题的从POSTGRESQL的TUPLE 来说起,也就是行的结构,这个结构可以解释为HOT, heap only tuple 这个结构起源于POSTGRESQL 8.3
| Field | Type | Length | Description |
|---|---|---|---|
| t_xmin | TransactionId | 4 bytes | insert XID stamp |
| t_xmax | TransactionId | 4 bytes | delete XID stamp |
| t_cid | CommandId | 4 bytes | insert and/or delete CID stamp (overlays with t_xvac) |
| t_xvac | TransactionId | 4 bytes | XID for VACUUM operation moving a row version |
| t_ctid | ItemPointerData | 6 bytes | current TID of this or newer row version |
| t_infomask2 | uint16 | 2 bytes | number of attributes, plus various flag bits |
| t_infomask | uint16 | 2 bytes | various flag bits |
| t_hoff | uint8 | 1 byte | offset to user data |

上面图的结构在PG12 实际上变成了
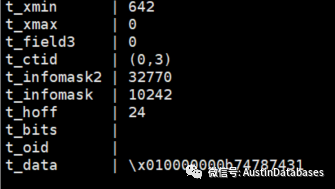
这里t_min 存储的信息为行建立时的txid 事务号,t_max 存储的是行更新后的事务号, 如果行没有被更新则存储的值为0
POSTGRESQL 的事务的处理和并发就依靠了t_min 和 t_max 两个字段,而不去使用类似ORACLE MYSQL 的 UNDO REDO 的方式来进行数据的操作和回滚。优点是不会有类似UNDO 的表空间,以及需要清理UNDO表空间的工作。数据也一直是在数据表中,事务失败也可以以最快速的方式来进行数据的“回滚”。
我们可以做一个实验看看POSTGRESQL 是怎么来对待数据的 I D U 的操作,
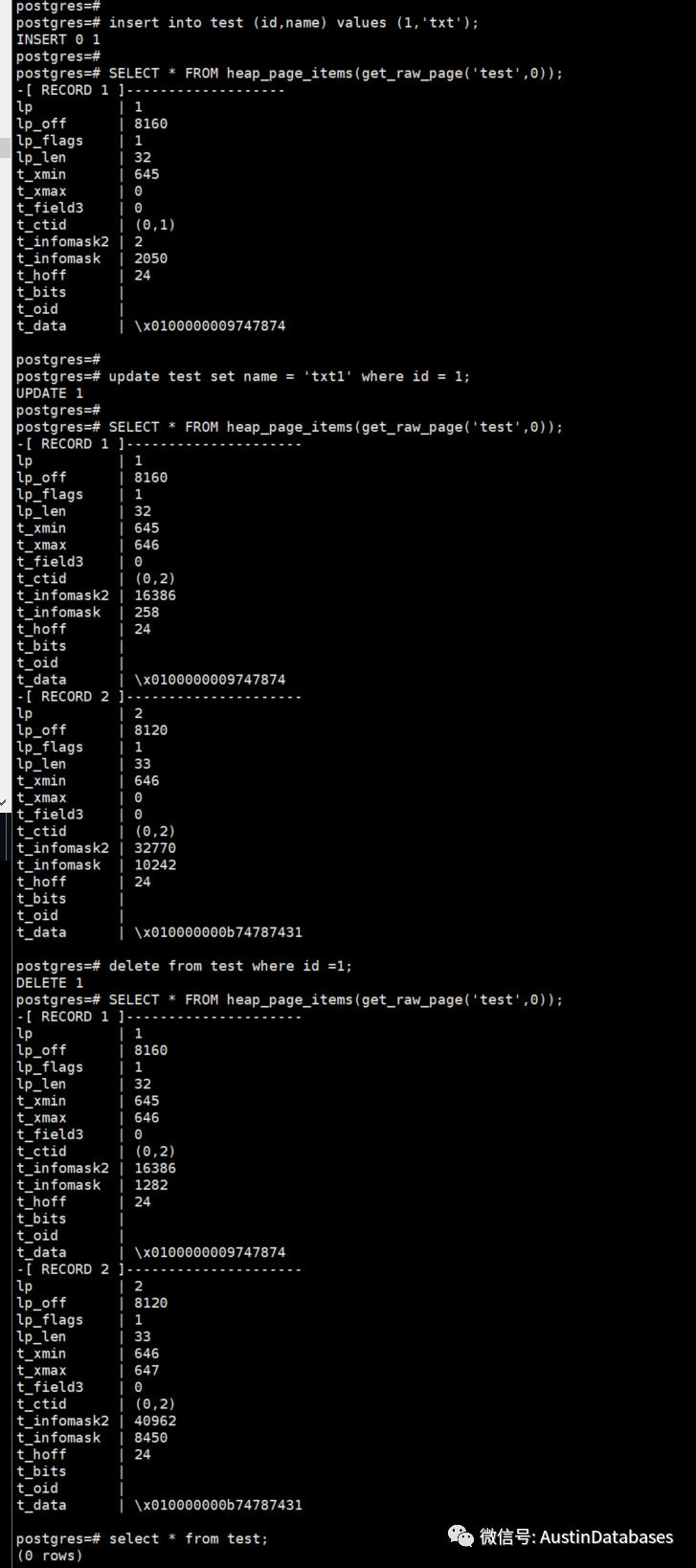
上图中,在插入了一条数据后, t_xmin 初始了一个数值, t_xmax 值为0 , t_ctid = 0 , 在我们更新了数据后, 产生了两条记录,一条是原有的记录,另一条是新的记录。并且在原有的记录上xmax 上记录了新的记录的事务号。
在我们删除了记录后,会在产生一条新的记录,并更新t_xmin 和 t_xmax 的记录的事务号。

通过这样的手段,POSTGRESQL 实现了MVCC 多版本的控制,在多个事务访问和更改数据的时候会存在多个版本的数据行。
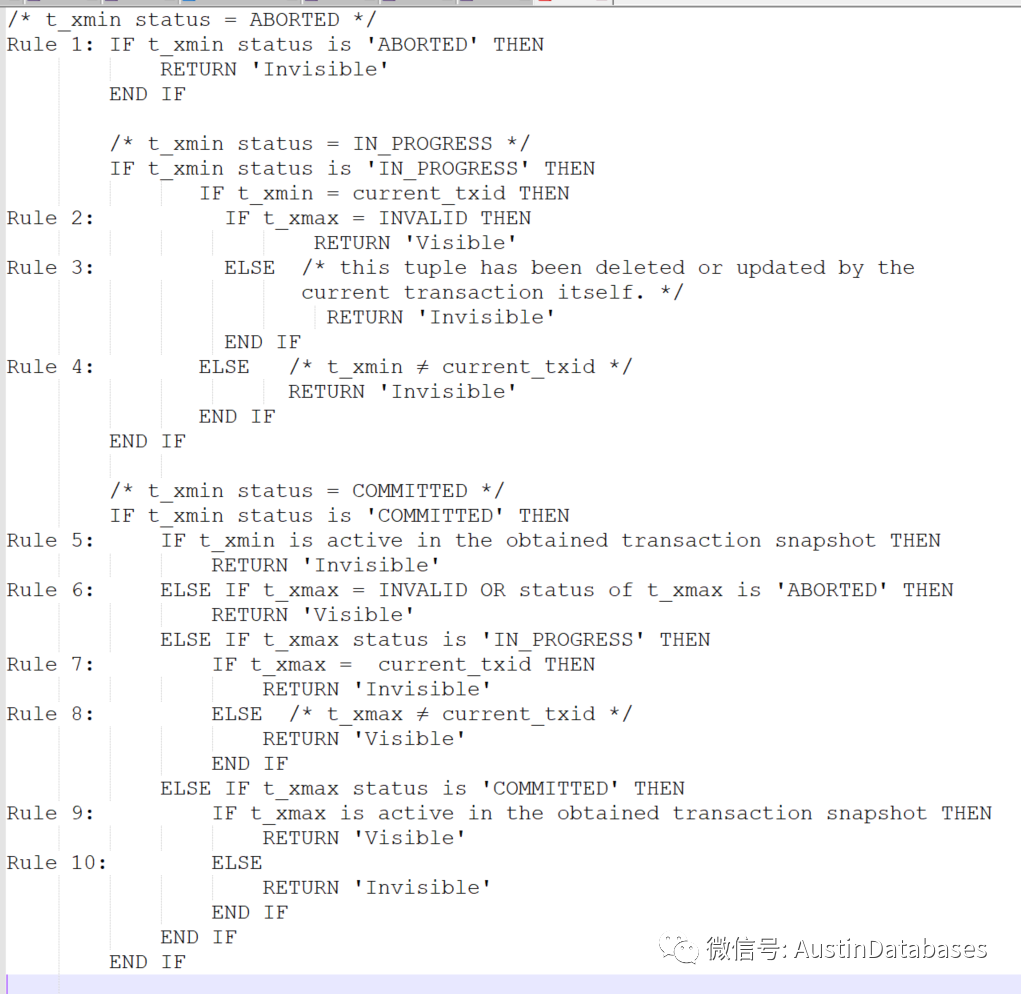
通过上面的程序我们可以来分析x_xmin x_xmax 对于数据库多版本和并发的作用。


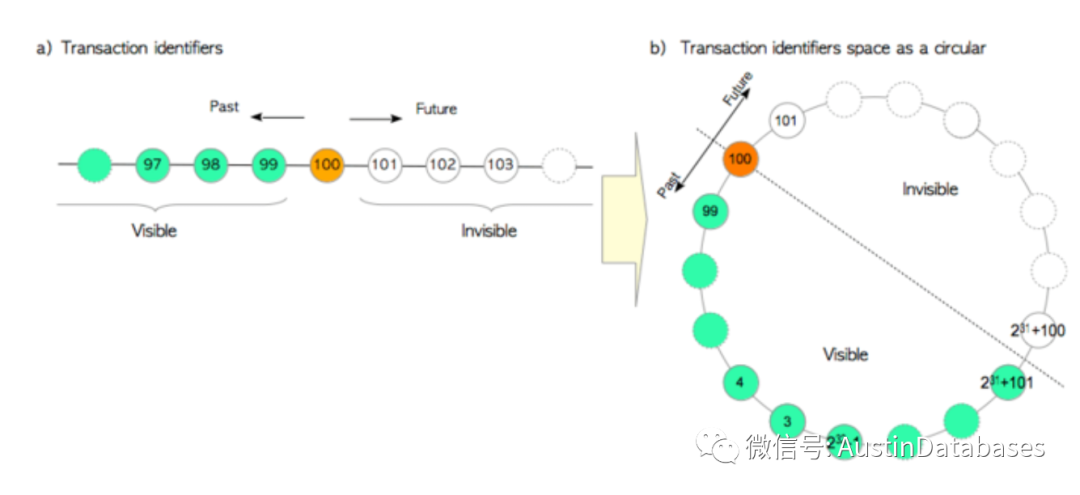
MVCC 多版本控制在POSTGRESQL 上最终想实现的目的是,数据读不堵塞写,但这样的实现的方式有以下注意的事项
1 不同的事务会看到不同版本的记录,所以POSTGRESQL 会保留较多的同一数据的多个版本。
2 事务的ID 为32BIT, POSTGRESQL 必须不断的进行清理DEAD TUMPLE,防止数据库出现FREEZE的情况。上面的彩色图右侧是这部分问题的原理解释。


















 3158
3158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









