



 本文详细介绍了Repmgr的配置文件参数及其含义,包括node_id、node_name、conninfo等,同时提供了手动切换主从节点、提升从库为主库、查看节点状态等基本命令的使用方法。
本文详细介绍了Repmgr的配置文件参数及其含义,包括node_id、node_name、conninfo等,同时提供了手动切换主从节点、提升从库为主库、查看节点状态等基本命令的使用方法。

应该是第三个关于PostgreSQL 高可用的文字了,Repmgr 在使用中的一些通用的命令和一些配置文件的含义,今天需要明确。
我们先从配置文件来入手,如果你的配置文件不知道怎么写,或者根本不知道配置文件中有哪些内容,请从
https://repmgr.org/docs/4.4/repmgr-administration-manual.html 网站中获得。
部分配置文件内容:
node_id=1 node_id 是标识数据库的节点的序号,在使用其他命令时,是需要指定相关序号的,并且相关的序号在一个集群中是不能重复的。
node_name = ‘XXX’ node name 是标识这台机器在集群中的名字,需要注意的是名字不能超过63个字符并且,最好是小写,明确标识机器的文字
conninfo='host=192.168.198.112 user=repmgr dbname=repmgr connect_timeout=2' 这是标识每台集群中到PG 的连接的信息,connect_timeout 是配置当你使用 repmgrd时,忽略某些因为网络延迟或故障中可能会导致误切换的等待时间的长度
data_directory='/pgdata/data' 这是指定当前机器的PG的数据目录,因为有的集群中每个机器的数据目录可能因为某些原因,不一致,所以这里会告知repmgr 具体的数据目录在哪里
config_directory='' 这是配置标识,PG的配置文件的所在地,一般可以不配置,如果你的配置文件并未和数据目录放置在一起,则你需要配置
replication_user='repmgr' 配置PG中复制的账户,这里使用了repmgr作为复制的账户,当然你可以使用别的账户进行复制的配置,而不必须非要使用repmgr 来作为复制的账户。
replication_type=physical 这里需要告知REPMGR PG 的复制方式,是那个,一般建议physical 如果没有特殊的需求。
location=default 这个配置是为多数据中心来进行服务的,如果有多数据中心,一般会假设如果网络不稳定的状态下,是否进行切换或者不做任何事情,location就是标识你的机器所在的位置
witness_sync_interval 这是标识出第三方的见证服务器获取信息到见证服务器的时间
log_level =INFO 这里指定了log的level 有相关八个等级
log_file='' 重定向LOG file的写入的位置否则只能写入到系统的STDERR
pg_bindir= 指定PG 的执行文件的目录
repmgr_bindir = 指定 PG 的 repmgr 执行文件的目录
failover=manual 指定当发生主节点failover时节点的处理方式是自动还是手动方式
priority = 100 当你有多个PG的从节点,怎么人为的来判断哪个更适合来做下一个主节点的候选。
reconnect_attempts = 当主节点无法连接时,重进进行连接的次数
当然上面的介绍是比较基本的信息,有一些更有深层次含义和设置的项目并不包含在里面,例如MYSQL MHA 中如果主节点进行切换,则MHA 会让用户填写下一步会执行的外部脚本,在 REPMGR 中也有相关的设置。
大致说完了相关的配置文件后,下面是一些基本的REPMGR 的基本命令的介绍
1 手动进行主从节点的切换
一般来说,如果要对主库的服务器进行硬件升级,或者操作会需要将主库进行关闭,而类似这样的行为是有准备的和计划的
下面我们就通过手动的命令来将主库切换为从库
请到从库服务器中执行如下命令, 下面就会开始模拟进行切换的过程或者告诉你一些信息或错误信息,如果你去掉 --dry-run 则就实际的执行了,如果使用过 pt-osc的同学对--dry-run会有深刻的影响
repmgr -f /etc/repmgr.conf standby switchover --dry-run
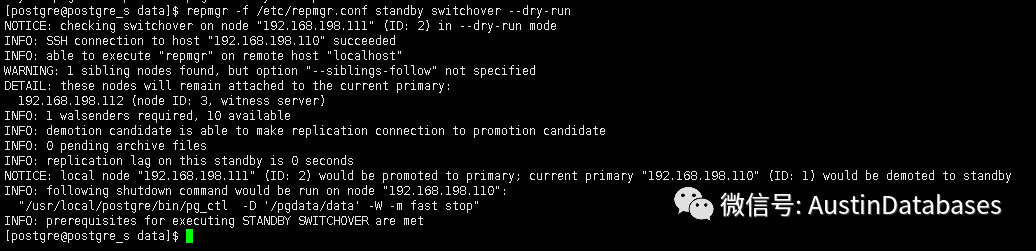

切换后,在查看当前的集群信息,也会进行相应的修改
这是比较有用的一个功能
2 提升从库成为主库
在你选择了FAILOVER 中手动进行从库到主库的提升,你需要手动进行主库的提升
repmgr -f /etc/repmgr.conf standby promote
3 查看当前节点的状态
repmgr -f /etc/repmgr.conf node status
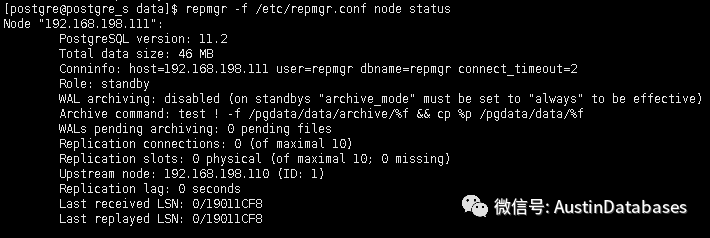
4 在主节点失败后,其他的从节点如果还连接着失败的主节点或者已经失去的连接,则是不妥当的,需要有相关的命令来将这些连接错误的节点重新连接到新的主节点中。在错误连接主节点的
repmgr -f /etc/repmgr.conf standby follow
5 查看当前的节点与其他节点的连接情况
repmgr -f /etc/repmgr.conf cluster matrix
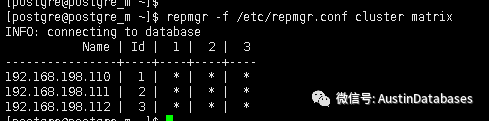
总结:其实在repmgr 的使用中,可以感觉到,即使不需要自动failover ,repmgr 在快速建立流复制从库和检查节点之间的状态也是很好的工具。


















 1482
1482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









