




 本文探讨了一种方法,通过训练参数预测器从神经网络激活值预测全连接层参数,以适应少样本图像识别任务。研究发现激活值和参数在空间分布上有相似性,模型能在大量和少量样本中保持良好性能。实验在ImageNet和MiniImageNet上展示了该方法的有效性。
本文探讨了一种方法,通过训练参数预测器从神经网络激活值预测全连接层参数,以适应少样本图像识别任务。研究发现激活值和参数在空间分布上有相似性,模型能在大量和少量样本中保持良好性能。实验在ImageNet和MiniImageNet上展示了该方法的有效性。
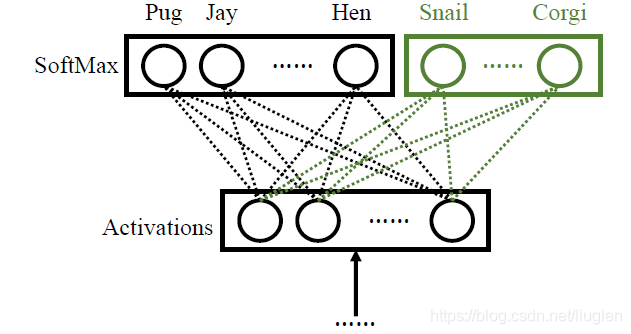
本文基于神经网络中同一类别倒数层的激活值和最后的全连接softmax层的参数有密切的关系,通过训练一个参数预测器,使得在大量数据集中预训练过的网络可以通过直接从激活值预测参数的方式将模型映射到只有少量样本的测试数据集中。作者希望模型可以在少样本和大量样本的情况下均有良好的表现。

作者通过使用t-SNE对激活值的期望aˉy\bar{a}_yaˉy(左)和全连接层的参数wyw_ywy(右)进行了可视化,同一颜色和形状的点表示同一种类别,形状相同的属于同一大类,可以发现同一类别的激活值在空间分布上是聚集在一起的。在最后的全连接层中,对应类别的 wy⋅ay\ w_y\cdot a_y wy⋅ay, for all ay∈Ayfor\ all\ a_y \in A_yfor all ay∈Ay , Ay={ a(x)∣x∈Dlarge∪Dfew,Y(x)=y}A_y = \{a(x) | x\in D_{large} \cup D_{few}, Y(x) = y\}Ay={ a(x)∣x∈Dlarge∪Dfew,Y(x)=y}(a(x)表示样本x的激活值)越大,分类的效果越好。所以wyw_ywy的分布应该与aˉy\bar{a}_yaˉy的分布越接近越好,以便使內积最大。这个结果说明在一个好的特征提取的情况下是存在一个类别无关的从激活值到参数的映射,也就是要训练的参数预测器ϕ\phiϕ
模型
模型在大量的数据集中进行训练,由于激活值和参数在各自的空间中具有相似相似的局部和全局结构,所以在CfewC_{few}Cfew的类别上应该有比较好的泛化能力。
1. 预测器
通过在大量数据集上最小化分类损失学习预测器ϕ\phiϕ
L=∑(y,x)∈Dlarge[−ϕ(aˉy)a(x)+log∑y′∈Clargeeϕ(aˉy′)a(x)]+λ∣∣ϕ∣∣ \mathcal{L} = \sum_{(y,x)\in D_{large}}[-\phi(\bar{a}_y)a(x)+log{\sum_{y\prime\in C_{large}}e^{\phi(\bar{a}_{y\prime})a(x)}}]+\lambda||\phi|| L=(y,x)∈Dlarge∑[−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









