



一、节点类型
二、结构体
三、监听器原理
四、选举机制
4.1 重要的参数。
4.2 选举状态:
4.3 服务器启动时的 leader 选举
4.4 运行过程中的 leader 选举
作 者: 雨中散步撒哈拉
来 源:https://liudongdong.top
公众号:雨中散步撒哈拉
备 注: 欢迎关注公众号,学习技术,一起成长!
一、节点类型
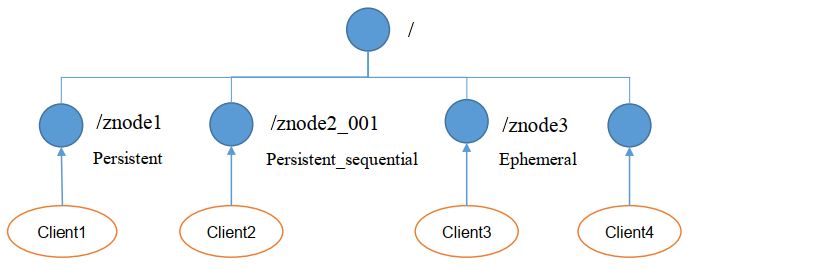
image.png
-
持久(Persistent):客户端和服务器端断开连接后, 创建的节点不删除
1.1. 持久化目录节点:客户端与Zookeeper断开连接后,该节点依旧存在
1.2. 持久化顺序编号目录节点:客户端与Zookeeper断开连接后, 该节点依旧存在, 只是Zookeeper给该节点名称进行顺序编号 -
短暂(Ephemeral):客户端和服务器端断开连接后, 创建的节点自己删除
2.1. 临时目录节点:客户端与Zookeeper断开连接后, 该节点被删除
2.2. 临时顺序编号目录节点:客户端与Zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号。
说明:创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
注意:在分布式系统中,顺序号可以被用于为所有的事件进行全局排序, 这样客户端可以通过顺序号推断事件的顺序
二、结构体
使用stat命令,查看节点详细信息
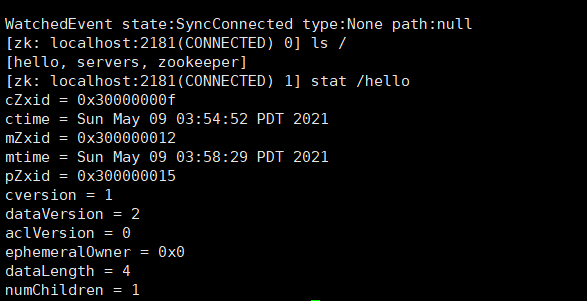
image.png
| cZxid | 创建节点时的事务ID |
|---|---|
| ctime | 创建节点时的时间 |
| mZxid | 最后修改节点时的事务ID |
| mtime | 最后修改节点时的时间 |
| pZxid | 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID**(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid)** |
| cversion | 子节点版本号,子节点每次修改版本号加1 |
| dataversion | 数据版本号,数据每次修改该版本号加1 |
| aclversion | 权限版本号,权限每次修改该版本号加1 |
| ephemeralOwner | 创建该临时节点的会话的sessionID。(*如果该节点是持久节点,那么这个属性值为0)* |
| dataLength | 该节点的数据长度 |
| numChildren | 该节点拥有子节点的数量**(只统计直接子节点的数量)** |
三、监听器原理
-
首先要有一个main()线程
-
在main线程中创建Zookeeper客户端, 这时就会创建两个线程, 一个负责网络连接通信( connet), 一个负责监听( listener )。
-
通过connect线程将注册的监听事件发送给Zookeeper。
-
在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中。
-
Zookeeper监听到有数据或路径变化, 就会将这个消息发送给listener线程。
-
listener线程内部调用了process()方法。

image.png
常见的监听:
-
监听节点数据的变化 get path [watch]
-
监听子节点增减的变化 ls path [watch]
四、选举机制
zookeeper 的 leader 选举存在两个阶段,一个是服务器启动时 leader 选举,另一个是运行过程中 leader 服务器宕机。
4.1 重要的参数。
-
服务器 ID(myid):编号越大在选举算法中权重越大
-
事务 ID(zxid):值越大说明数据越新,权重越大
-
逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加
4.2 选举状态:
LOOKING: 竞选状态
FOLLOWING: 随从状态,同步 leader 状态,参与投票
OBSERVING: 观察状态,同步 leader 状态,不参与投票
LEADING: 领导者状态
4.3 服务器启动时的 leader 选举
每个节点启动的时候都 LOOKING 观望状态,接下来就开始进行选举主流程。这里选取三台机器组成的集群为例。第一台服务器 server1启动时,无法进行 leader 选举,当第二台服务器 server2 启动时,两台机器可以相互通信,进入 leader 选举过程。
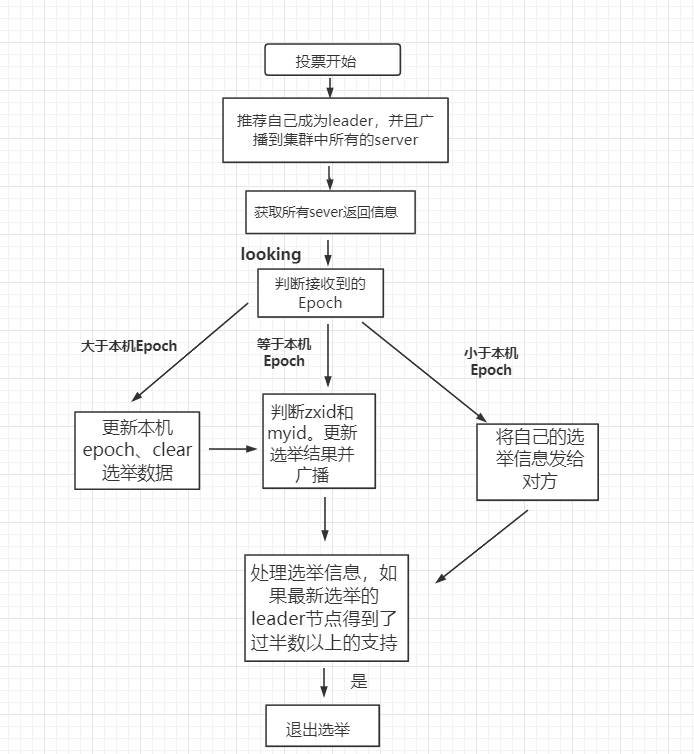
image.png
-
每台 server 发出一个投票,由于是初始情况,server1 和 server2 都将自己作为 leader 服务器进行投票,每次投票包含所推举的服务器myid、zxid、epoch,使用(myid,zxid)表示,此时 server1 投票为(1,0),server2 投票为(2,0),然后将各自投票发送给集群中其他机器。
-
接收来自各个服务器的投票。集群中的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自 LOOKING 状态的服务器。
-
分别处理投票。针对每一次投票,服务器都需要将其他服务器的投票和自己的投票进行对比,对比规则如下:
3.1. 优先比较 epoch
3.2. 检查 zxid,zxid 比较大的服务器优先作为 leader
3.3. 如果 zxid 相同,那么就比较 myid,myid 较大的服务器作为 leader 服务器 -
统计投票。每次投票后,服务器统计投票信息,判断是否有过半机器接收到相同的投票信息。server1、server2 都统计出集群中有两台机器接受了(2,0)的投票信息,此时已经选出了 server2 为 leader 节点。
-
改变服务器状态。一旦确定了 leader,每个服务器响应更新自己的状态,如果是 follower,那么就变更为 FOLLOWING,如果是 Leader,变更为 LEADING。此时 server3继续启动,直接加入变更自己为 FOLLOWING。
4.4 运行过程中的 leader 选举
当集群中 leader 服务器出现宕机或者不可用情况时,整个集群无法对外提供服务,进入新一轮的 leader 选举。
-
变更状态。leader 挂后,其他非 Oberver服务器将自身服务器状态变更为 LOOKING。
-
每个 server 发出一个投票。在运行期间,每个服务器上 zxid 可能不同。
-
处理投票。规则同启动过程。
-
统计投票。与启动过程相同。
-
改变服务器状态。与启动过程相同。

















 2482
2482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









