




 本文详细介绍了Zookeeper集群从3个节点扩容到5个节点的具体步骤,并总结了扩容过程中可能出现的问题及解决办法,如数据丢失的原因及预防措施。
本文详细介绍了Zookeeper集群从3个节点扩容到5个节点的具体步骤,并总结了扩容过程中可能出现的问题及解决办法,如数据丢失的原因及预防措施。
前言
最近笔者做了ZK集群的扩容,总结了一些经验,分享一下,其实其中还是有些问题的。
1. 扩容架构设计
设计图如下:
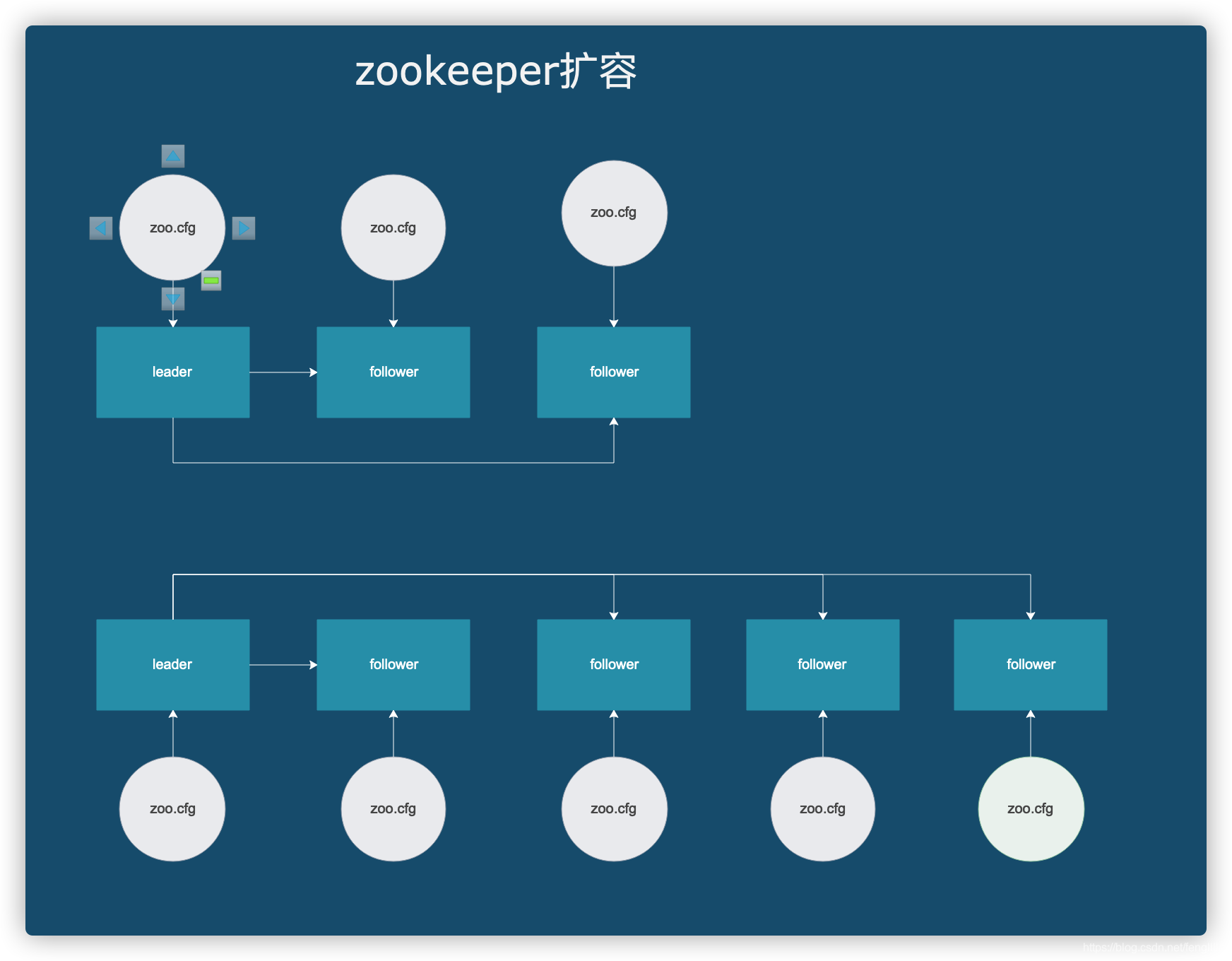
本质是zookeeper的3个节点扩容至5节点,实现2个节点的容错,提高稳定性。
由于允许短时间停机,所以采用比较保守的方式扩容,没有采用不停集群扩展。总结为改配置,重启。
至于不停机扩容,这个其实需要严格测试,根据停机扩容的情况,过程中出现的问题不少。
2. 扩容过程的问题
2.1 选主的过程
zookeeper选举的原理是比较,当前服务器的epoch、lastLoggedZxid和myid,zookeeper会根据这几个数据比对,然后根据这3个值选举leader。保证数据的准确性。
epoch
选举的次数,即参与了几次选举,表示取参与选举次数最大的选举节点,越大越优先。
lastLoggedZxid
最后的事务日志ID,我们知道zookeeper有快照与事务日志,快照是内存的瞬时态,配合事务日志才能还原最新内存的数据,越大越优先。
myid
节点ID,越大越优先。
2.2 zookeeper集群复制机制
DIFF同步、TRUNC+DIFF同步、TRUNC同步、SNAP同步
DIFF同步
直接差异化同步,在leader与follower差异不大的情况,数据影响较小,或者没有影响。
TRUNC+DIFF同步
回滚同步,再差异比较,可能造成数据丢失
TRUNC同步
回滚同步,可能造成数据丢失
SNAP同步
内存复制,针对新增的节点。
2.3 扩容问题
扩容后数据丢失部分,造成监听器监听,对应用造成严重后果。
问题出现情况:
3个节点集群停机,马上启动5个节点集群。
问题出现原因,老集群3个节点在加载快照与事务的过程中有先后顺序,新增的2个节点启动极快,造成老节点与新增的2个节点开始选主,由于加载快的老节点数据一般就会比较旧,执行TRUNC+DIFF同步。造成数据丢失
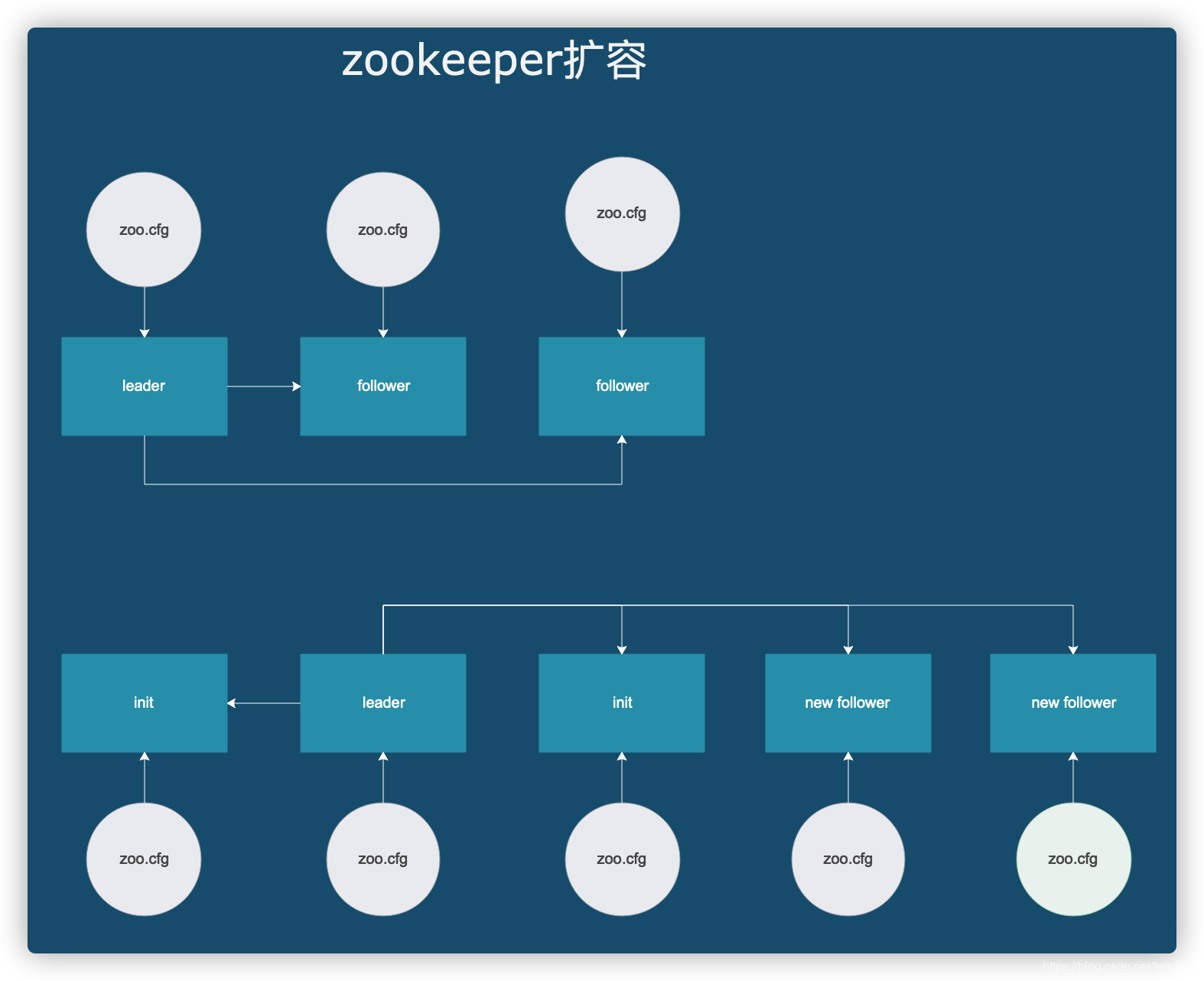
即使后面老集群的其他2个节点启动OK,也被迫接受TRUNC+DIFF同步。数据丢失了,所以在zookeeper扩容之前需要严格备份zoo.cfg 快照日志 事务日志,还要有方案,zookeeper完全挂掉如何恢复。
3. 解决方案
先启动旧集群的3个节点,待选举复制OK(即可以提供zk集群能力)后,再启动新增的2个节点,直接作为follower参与SNAP复制,即可保证数据的准确性。
总结
zookeeper集群扩容需要非常慎重,数据是保存在快照与事务日志中的,每个节点的数据不是绝对对等的,不是强一致性,一半以上的节点复制OK即可提供服务。扩容前需要反复演练,否则很难发现问题。

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









