







 本文深入探讨了字符串的概念,包括其基本表示方式、布尔值、字符编码(如ASCII、Unicode、UTF-8)及其应用场景,同时介绍了ord()和chr()函数的使用,以及字符串的格式化方法。
本文深入探讨了字符串的概念,包括其基本表示方式、布尔值、字符编码(如ASCII、Unicode、UTF-8)及其应用场景,同时介绍了ord()和chr()函数的使用,以及字符串的格式化方法。
- 字符串是以''或""括起来的任意文本
-
>>>'I\'m \"OK\"!'表示的字符串内容是:I'm "OK"!
-
布尔值有:True、False
-
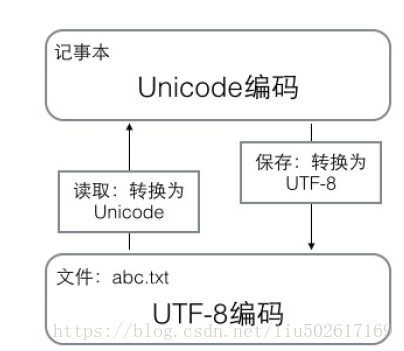
字符编码:分为ASCI码,Unicode,UTF-8
ASCII编码:127个字母,即大小写英文字母、数字和一些符号。Unicode:把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
UTF-8编码:把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间
-
ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:>>> ord('A') 65 >>> ord('中') 20013 >>> chr(66) 'B' >>> chr(25991) '文'- 对
bytes类型的数据用带b前缀的单引号或双引号表示: - 以Unicode表示的字符串用u'...'表示,r'...'
- 代码
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125) 'Hello, 小明, 成绩提升了 17.1%' >>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you have $1000000.' - list[],tuple() tuple指向的元素不能变
-
再议 input
birth = input('birth: ') if birth < 2000: print('00前') else: print('00后') -
循环小议
break语句可以在循环过程中直接退出循环,而continue语句可以提前结束本轮循环,并直接开始下一轮循环。这两个语句通常都必须配合if语句使用。 -
dict,set
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} s = set([1, 2, 3])

















 2875
2875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









