 梯度提升树详解
梯度提升树详解





 本文深入探讨了梯度提升树的原理与实现过程,详细介绍了目标函数、损失函数及正则化项的概念,并通过数学推导说明如何通过梯度提升方法优化模型。此外,还讲解了如何使用XGBoost进行手写数字识别。
本文深入探讨了梯度提升树的原理与实现过程,详细介绍了目标函数、损失函数及正则化项的概念,并通过数学推导说明如何通过梯度提升方法优化模型。此外,还讲解了如何使用XGBoost进行手写数字识别。
点击下方图片查看HappyChart专业绘图软件

目标函数
O
b
j
(
θ
)
=
L
(
θ
)
+
Ω
(
θ
)
Obj(\theta)=L(\theta)+\Omega(\theta)
Obj(θ)=L(θ)+Ω(θ)
其中,
L
(
θ
)
L(\theta)
L(θ)表示模型拟合训练数据的程度,
Ω
(
θ
)
\Omega(\theta)
Ω(θ)是正则化项,用来表示模型的复杂程度。
一般,训练集的损失函数记为: L = Σ i = 1 n l ( y i , y i ^ ) L=\Sigma_{i=1}^nl(y_i,\hat{y_i}) L=Σi=1nl(yi,yi^)
- 平方损失函数: l ( y i , y i ^ ) = ( y i , y i ^ ) 2 l(y_i,\hat{y_i})=(y_i,\hat{y_i})^2 l(yi,yi^)=(yi,yi^)2
- 对数损失函数: l ( y i , y i ^ ) = y i l n ( 1 + e − y i ^ ) + ( 1 − y i ) l n ( 1 + e y i ^ ) l(y_i,\hat{y_i})=y_iln(1+e^{-\hat{y_i}})+(1-y_i)ln(1+e^{\hat{y_i}}) l(yi,yi^)=yiln(1+e−yi^)+(1−yi)ln(1+eyi^)
正则化:
- L2正则化: Ω ( ω ) = λ ∣ ∣ ω ∣ ∣ 2 \Omega(\omega)=\lambda||\omega||^2 Ω(ω)=λ∣∣ω∣∣2
- L1正则化: Ω ( ω ) = λ ∣ ∣ ω ∣ ∣ 1 \Omega(\omega)=\lambda||\omega||_1 Ω(ω)=λ∣∣ω∣∣1
优化训练损失函数能保证模型具有预测性,而优化正则化项能是模型更简单。
回归树的集成
模型:
假设我们有K个树,则
y
i
^
=
Σ
k
=
1
K
f
k
(
x
i
)
,
f
k
∈
F
\hat{y_i}=\Sigma_{k=1}^Kf_k(x_i), f_k \in F
yi^=Σk=1Kfk(xi),fk∈F
F
F
F为包含所有回归树的函数空间。
如下图:
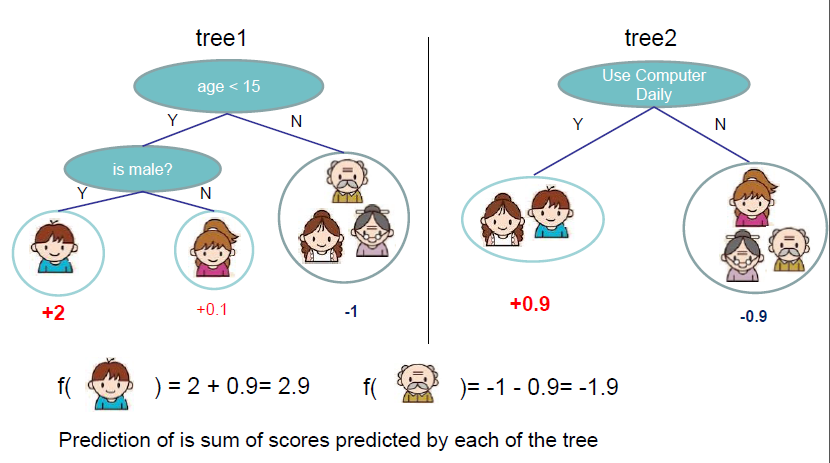
每一个人代表一个样例,而每个样例的总得分是由每个树在该样例得分加总得到的。所以 f k ( x i ) f_k(x_i) fk(xi)表示在树 f k f_k fk中样本 x i x_i xi的得分。
学习函数
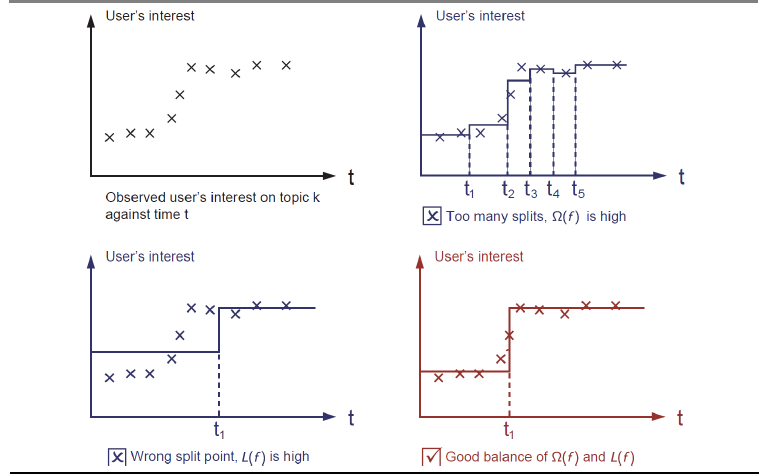
从第一张图我们看出,这是在话题k上用户兴趣随着时间的变化,在第二张图中,我们训练了一个模型,有非常多的切分点,这样虽然能很好的拟合数据,但是模型的复杂度上升了,这样可能导致大的方差;在第三张图中由于分割点错误,模型拟合不够,会造成较大的偏差,而最后一张图中在方差和偏差之间找到了较好的平衡。但是要怎样才能找到这样的平衡呢。
梯度提升
目标函数:
Σ
i
=
1
n
l
(
y
i
,
y
i
^
)
+
Σ
k
Ω
(
f
k
)
,
f
k
∈
F
\Sigma_{i=1}^nl(y_i,\hat{y_i})+\Sigma_k\Omega(f_k), f_k \in F
Σi=1nl(yi,yi^)+ΣkΩ(fk),fk∈F
首先从一个常数预测开始,每次加一个函数:
y
^
i
(
0
)
=
0
y
^
i
(
1
)
=
f
1
(
x
i
)
=
y
^
i
(
0
)
+
f
1
(
x
i
)
y
^
i
(
2
)
=
f
1
(
x
i
)
+
f
2
(
x
i
)
=
y
^
i
(
1
)
+
f
2
(
x
i
)
.
.
.
y
^
i
(
t
)
=
Σ
k
=
1
t
f
k
(
x
i
)
=
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
\hat{y}_i^{(0)} = 0\\ \hat{y}_i^{(1)} = f_1(x_i)=\hat{y}_i^{(0)}+f_1(x_i)\\ \hat{y}_i^{(2)}=f_1(x_i)+f_2(x_i)=\hat{y}_i^{(1)}+f_2(x_i)\\ ...\\ \hat{y}_i^{(t)}=\Sigma_{k=1}^tf_k(x_i)=\hat{y}_i^{(t-1)}+f_t(x_i)
y^i(0)=0y^i(1)=f1(xi)=y^i(0)+f1(xi)y^i(2)=f1(xi)+f2(xi)=y^i(1)+f2(xi)...y^i(t)=Σk=1tfk(xi)=y^i(t−1)+ft(xi)
在第t轮预测中 y ^ i ( t ) = y ^ i ( t − 1 ) + f t ( x i ) \hat{y}_i^{(t)}=\hat{y}_i^{(t-1)}+f_t(x_i) y^i(t)=y^i(t−1)+ft(xi),而这个 f t ( x i ) f_t(x_i) ft(xi)就是在第t轮我们需要决定的。
O b j ( t ) = Σ i = 1 n l ( y i , y i ^ ( t ) ) + Σ i = 1 t Ω ( f i ) = Σ i = 1 n l ( y i , y i ^ ( t − 1 ) + f t ( x i ) ) + Ω ( f t ) + c o n s t a n t Obj^{(t)}=\Sigma_{i=1}^nl(y_i,\hat{y_i}^{(t)})+\Sigma_{i=1}^t\Omega(f_i)\\ =\Sigma_{i=1}^nl(y_i,\hat{y_i}^{(t-1)}+f_t(x_i))+\Omega(f_t)+constant Obj(t)=Σi=1nl(yi,yi^(t))+Σi=1tΩ(fi)=Σi=1nl(yi,yi^(t−1)+ft(xi))+Ω(ft)+constant
我们的目标就是找到
f
t
f_t
ft使得
Σ
i
=
1
n
l
(
y
i
,
y
i
^
(
t
−
1
)
+
f
t
(
x
i
)
)
+
Ω
(
f
t
)
\Sigma_{i=1}^nl(y_i,\hat{y_i}^{(t-1)}+f_t(x_i))+\Omega(f_t)
Σi=1nl(yi,yi^(t−1)+ft(xi))+Ω(ft)最小。
如果我们考虑平方损失函数,则
O
b
j
(
t
)
=
Σ
i
=
1
n
(
y
i
−
(
y
i
^
(
t
−
1
)
+
f
t
(
x
i
)
)
)
2
+
Ω
(
f
t
)
+
c
o
n
s
t
=
Σ
i
=
1
n
[
2
(
y
i
^
(
t
−
1
)
−
y
i
)
f
t
(
x
i
)
+
f
t
(
x
i
)
2
]
+
Ω
(
f
t
)
+
c
o
n
s
t
Obj^{(t)}=\Sigma_{i=1}^n(y_i-(\hat{y_i}^{(t-1)}+f_t(x_i)))^2+\Omega(f_t)+const\\ =\Sigma_{i=1}^n[2(\hat{y_i}^{(t-1)}-y_i)f_t(x_i)+f_t(x_i)^2]+\Omega(f_t)+const
Obj(t)=Σi=1n(yi−(yi^(t−1)+ft(xi)))2+Ω(ft)+const=Σi=1n[2(yi^(t−1)−yi)ft(xi)+ft(xi)2]+Ω(ft)+const
现在目标函数看起来仍非常复杂。那么,我们对目标函数进行泰勒展开式展开
二阶泰勒展开式为
f
(
x
+
△
x
)
≃
f
(
x
)
+
f
′
(
x
)
△
x
+
1
/
2
f
′
′
(
x
)
△
x
2
f(x+\triangle x)\simeq f(x)+f'(x)\triangle x+1/2f''(x)\triangle x^2
f(x+△x)≃f(x)+f′(x)△x+1/2f′′(x)△x2
定义:
g
i
=
∂
y
^
(
t
−
1
)
l
(
y
i
,
y
^
(
t
−
1
)
)
,
h
i
=
∂
y
^
(
t
−
1
)
2
l
(
y
i
,
y
^
(
t
−
1
)
)
g_i=\partial_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)}),h_i=\partial_{\hat{y}^{(t-1)}}^2l(y_i,\hat{y}^{(t-1)})
gi=∂y^(t−1)l(yi,y^(t−1)),hi=∂y^(t−1)2l(yi,y^(t−1))
g
i
,
h
i
g_i,h_i
gi,hi分别是
l
(
y
i
,
y
i
^
(
t
−
1
)
)
l(y_i,\hat{y_i}^{(t-1)})
l(yi,yi^(t−1))对
y
^
(
t
−
1
)
\hat{y}^{(t-1)}
y^(t−1)的一阶和二阶求导。
在这里,
f
(
x
)
=
l
(
y
i
,
y
^
(
t
−
1
)
)
f(x)=l(y_i,\hat{y}^{(t-1)})
f(x)=l(yi,y^(t−1)),而由
y
^
i
(
t
)
=
y
^
i
(
t
−
1
)
+
f
t
(
x
i
)
\hat{y}_i^{(t)}=\hat{y}_i^{(t-1)}+f_t(x_i)
y^i(t)=y^i(t−1)+ft(xi)可知
△
x
=
f
t
(
x
i
)
=
y
^
i
(
t
)
−
y
^
i
(
t
−
1
)
\triangle x=f_t(x_i)=\hat{y}_i^{(t)}-\hat{y}_i^{(t-1)}
△x=ft(xi)=y^i(t)−y^i(t−1)
则目标函数可以写作:
O
b
j
(
t
)
≃
Σ
i
=
1
n
[
l
(
y
i
,
y
i
^
(
t
−
1
)
)
+
g
i
f
t
(
x
i
)
+
1
/
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
+
c
o
n
s
t
Obj^{(t)}\simeq \Sigma_{i=1}^n[l(y_i,\hat{y_i}^{(t-1)})+g_if_t(x_i)+1/2h_if_t^2(x_i)]+\Omega(f_t)+const
Obj(t)≃Σi=1n[l(yi,yi^(t−1))+gift(xi)+1/2hift2(xi)]+Ω(ft)+const
当目标函数去掉常数项时为
O
b
j
(
t
)
≃
Σ
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
/
2
h
i
f
t
2
(
x
i
)
]
+
Ω
(
f
t
)
Obj^{(t)}\simeq \Sigma_{i=1}^n[g_if_t(x_i)+1/2h_if_t^2(x_i)]+\Omega(f_t)
Obj(t)≃Σi=1n[gift(xi)+1/2hift2(xi)]+Ω(ft)
其中
g
i
=
∂
y
^
(
t
−
1
)
l
(
y
i
,
y
^
(
t
−
1
)
)
,
h
i
=
∂
y
^
(
t
−
1
)
2
l
(
y
i
,
y
^
(
t
−
1
)
)
g_i=\partial_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)}),h_i=\partial_{\hat{y}^{(t-1)}}^2l(y_i,\hat{y}^{(t-1)})
gi=∂y^(t−1)l(yi,y^(t−1)),hi=∂y^(t−1)2l(yi,y^(t−1))
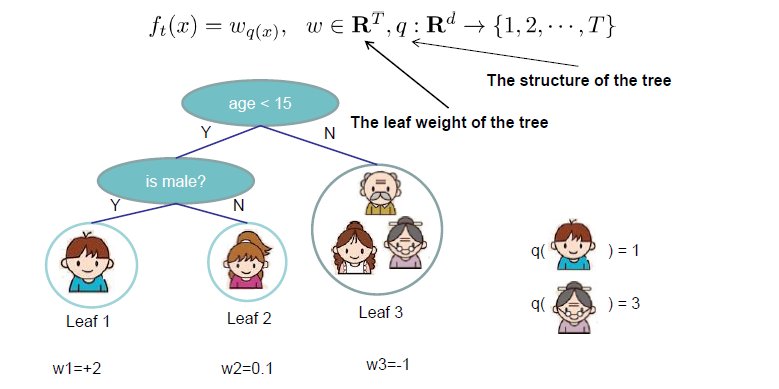
重新定义树
f
t
(
x
)
=
w
q
(
x
)
,
w
∈
R
T
,
q
:
R
d
→
{
1
,
2
,
.
.
.
,
T
}
f_t(x)=w_{q(x)}, w\in R^T, q:R^d\rightarrow \{1,2,...,T\}
ft(x)=wq(x),w∈RT,q:Rd→{1,2,...,T}
q
q
q代表每棵树的结构,它把一个样例映射到对应的叶结点上,
q
(
x
)
q(x)
q(x)即代表样例x在第几个叶节点上,
T
T
T是叶结点的个数,
w
q
(
x
)
w_{q(x)}
wq(x)为树的第
q
(
x
)
q(x)
q(x)个叶结点的权重得分
定义树的复杂度
Ω
=
γ
T
+
1
/
2
λ
Σ
j
=
1
T
w
j
2
\Omega=\gamma T + 1/2\lambda\Sigma_{j=1}^Tw_j^2
Ω=γT+1/2λΣj=1Twj2
右边第一项
T
T
T为叶结点的个数,第二项为L2正则化项。当然这个复杂度函数并不是唯一的。
下图展现了怎样计算复杂度
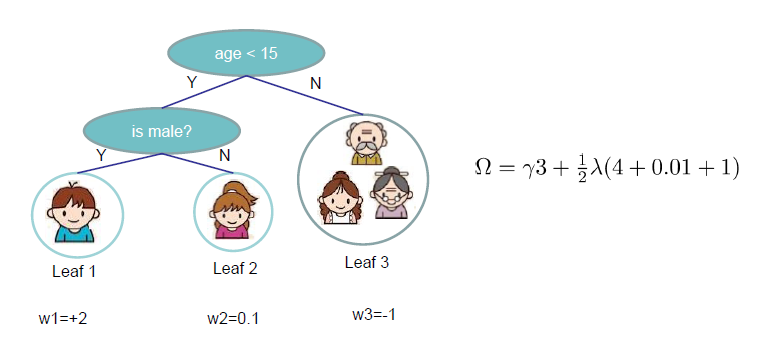
再次回顾目标函数
定义叶结点 j j j的样例集为 I j = { i ∣ q ( x i ) = j } I_j=\{i|q(x_i)=j\} Ij={i∣q(xi)=j}
这时,目标函数为
O
b
j
(
t
)
≃
Σ
i
=
1
n
[
g
i
f
t
(
x
i
)
+
1
/
2
h
i
f
i
2
(
x
i
)
]
+
Ω
(
f
t
)
=
Σ
i
=
1
n
[
g
i
w
q
(
x
i
)
+
1
/
2
h
i
w
q
(
x
i
)
2
]
+
γ
T
+
λ
1
2
Σ
j
=
1
T
w
j
2
=
Σ
j
=
1
T
[
(
Σ
i
∈
I
j
g
i
)
w
j
+
1
/
2
(
Σ
i
∈
I
j
h
i
+
λ
)
w
j
2
]
+
γ
T
Obj^{(t)}\simeq \Sigma_{i=1}^n[g_if_t(x_i)+1/2h_if_i^2(x_i)]+\Omega(f_t)\\ =\Sigma_{i=1}^n[g_iw_{q(x_i)}+1/2h_iw^2_{q(x_i)}]+\gamma T+\lambda\frac{1}{2}\Sigma_{j=1}^Tw_j^2\\ =\Sigma_{j=1}^T[(\Sigma_{i\in I_j}g_i)w_j+1/2(\Sigma_{i\in I_j}h_i+\lambda)w_j^2]+\gamma T
Obj(t)≃Σi=1n[gift(xi)+1/2hifi2(xi)]+Ω(ft)=Σi=1n[giwq(xi)+1/2hiwq(xi)2]+γT+λ21Σj=1Twj2=Σj=1T[(Σi∈Ijgi)wj+1/2(Σi∈Ijhi+λ)wj2]+γT
Σ
i
∈
I
j
\Sigma_{i\in I_j}
Σi∈Ij为样例
i
i
i在叶结点
j
j
j的集合,而
Σ
j
=
1
T
\Sigma_{j=1}^T
Σj=1T为所有的叶结点,故
Σ
i
=
1
n
=
Σ
j
=
1
T
Σ
i
∈
I
j
\Sigma_{i=1}^n=\Sigma_{j=1}^T\Sigma_{i\in I_j}
Σi=1n=Σj=1TΣi∈Ij,这样就得到最后一步了。
#结构得分及其计算
定义
G
j
=
Σ
i
∈
I
j
g
i
,
H
j
=
Σ
i
∈
I
j
h
i
G_j=\Sigma_{i\in I_j}g_i,H_j=\Sigma_{i\in I_j}h_i
Gj=Σi∈Ijgi,Hj=Σi∈Ijhi,则
O
b
j
(
t
)
=
Σ
j
=
1
T
[
G
j
w
j
+
1
/
2
(
H
j
+
λ
)
w
j
2
]
+
γ
T
Obj^{(t)}=\Sigma_{j=1}^T[G_jw_j+1/2(H_j+\lambda)w_j^2]+\gamma T
Obj(t)=Σj=1T[Gjwj+1/2(Hj+λ)wj2]+γT
假设树的结构(
q
(
x
)
q(x)
q(x))固定,则每个叶结点的最优权重和目标函数值为:
w
j
∗
=
−
G
j
H
j
+
λ
,
O
b
j
=
−
1
/
2
Σ
j
=
1
T
G
j
2
H
j
+
λ
+
γ
T
w_j^*=-\frac{G_j}{H_j+\lambda},Obj=-1/2\Sigma_{j=1}^T\frac{G_j^2}{H_j+\lambda}+\gamma T
wj∗=−Hj+λGj,Obj=−1/2Σj=1THj+λGj2+γT
这里的目标函数可被用作得分函数,用来测量树结构q的性能。
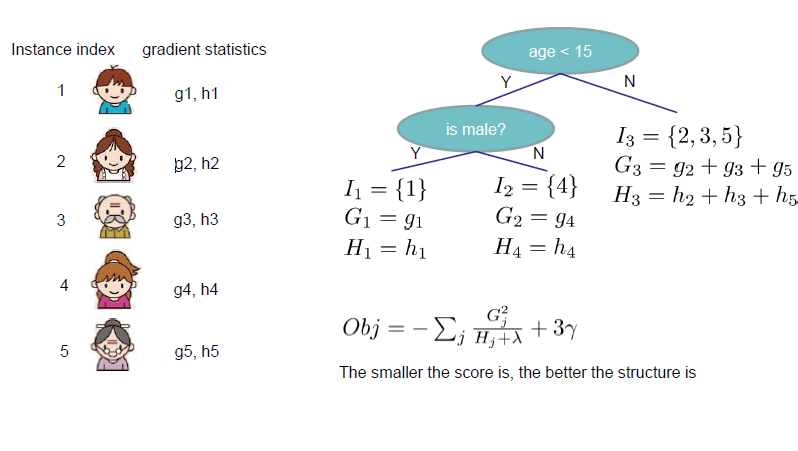
从上图,我们只需要计算一阶和二阶导数,然后加总并应用到得分方程。
树的贪婪学习
实际上,树的生长是贪婪的
- 首先从树的深度为0开始,即从根节点开始,枚举所有的特征;
- 对每一个特征,按照特征值对样例排序
- 对树的每一个叶结点,增加一个切割点,在增加切割点后,目标函数的变化为:
G a i n = 1 2 [ G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ ] − γ Gain=\frac{1}{2}[\frac{G_L^2}{H_L+\lambda}+\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}]-\gamma Gain=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−γ
右式第一项为左子节点得分,第二项为右子节点得分,第三项为分割前的得分, γ \gamma γ为增加额外节点的复杂度。 - 从左向右线性扫描排序后的样例,决定最佳的特征分割节点。
时间复杂度为:
O
(
n
d
K
l
o
g
n
)
O(ndKlogn)
O(ndKlogn)
对每一水平,需要
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)来排序,有d个特征和K个水平。
处理分类变量
xgBoost偏好处理稀疏矩阵,对于分类变量,我们需要进行one-hot编码。对分类变量进行one-hot编码后矩阵就会变得非常稀疏,这样xgBoost就容易处理。
总结
- 每次迭代增加一颗新树
- 开始每次迭代,计算
g i = ∂ y ^ ( t − 1 ) l ( y i , y ^ ( t − 1 ) ) , h i = ∂ y ^ ( t − 1 ) 2 l ( y i , y ^ ( t − 1 ) ) g_i=\partial_{\hat{y}^{(t-1)}}l(y_i,\hat{y}^{(t-1)}),h_i=\partial_{\hat{y}^{(t-1)}}^2l(y_i,\hat{y}^{(t-1)}) gi=∂y^(t−1)l(yi,y^(t−1)),hi=∂y^(t−1)2l(yi,y^(t−1)) - 生成树
f
t
(
x
)
f_t(x)
ft(x)
O b j = 1 / 2 Σ j = 1 T G j 2 H j + λ + γ T Obj = 1/2\Sigma_{j=1}^T\frac{G_j^2}{H_j+\lambda}+\gamma T Obj=1/2Σj=1THj+λGj2+γT - 把 f t ( x ) f_t(x) ft(x)加到模型 y i ^ ( t ) = y i ^ ( t − 1 ) + f t ( x i ) \hat{y_i}^{(t)}=\hat{y_i}^{(t-1)}+f_t(x_i) yi^(t)=yi^(t−1)+ft(xi)
- 通常我们用 y i ^ ( t ) = y i ^ ( t − 1 ) + ϵ f t ( x i ) \hat{y_i}^{(t)}=\hat{y_i}^{(t-1)}+\epsilon f_t(x_i) yi^(t)=yi^(t−1)+ϵft(xi)代替上式
- ϵ \epsilon ϵ称为步长,这样能防止过度拟合。
算法

R语言实现
使用的数据为kaggle竞赛的手写字体识别
注意:数据由int型必须转换为numeric,否则在训练时会出现错误,请看 stackoverflow提问的问题。
Error in xgb.DMatrix(train[, -1], label = train[, 1]) : REAL() can only be applied to a 'numeric', not a 'integer'
library(data.table)
library(caret)
library(xgboost)
digit_train <- fread("train.csv",header=T)
digit_test <- fread("test.csv",header=T)
index <- createDataPartition(digit$label,p=0.75,list=F)
train <- digit[index]
test <- digit[-index]
xgb <- xgboost(data=as.matrix(apply(digit_train[,-1],2,as.numeric)),##如果不转化为numeric,会出现上述错误
label=as.numeric(digit_train$label),eta=0.1,nrounds=50,
booster="gbtree",
num_class=10,
objective = "multi:softmax",
max_depth = 12,
)
pred <- predict(xgb,as.matrix(apply(digit_test,2,as.numeric)))
write.csv(pred,"pred.csv",row.names=F)
最后的精确度大约为0.95,不算好,还可以再调整参数。
CRAN上的参考文档:XGBoost R tutorial
参考文献:
Introduction to Boosted Tree
XGBoost: A Scalable Tree Boosting System
XGBoost
one-hot
XGBoost-Python完全调参指南-参数解释篇
github
XGBoost package

















 10万+
10万+





 到【灌水乐园】发言
到【灌水乐园】发言







