







与C++语言分手好多年,重识C++发现它变了,变得陌生,变得犀利,然而又变得臃肿。
C语言的美在于质朴,编译器不会为了支撑OO默默做一些经常令我们抓耳挠腮的工作。
C#语言的美在于简单,不需要关心那些细节问题,编译器都为我们做好了。
C++语言很尴尬,效率不如C,易用性不如C#。只有那些既追求运行效率又要使用OO的项目才会使用C++,比如游戏引擎。
即便如此C++依然是我最爱的语言,因为它充满挑战,就像一匹桀骜不驯的野马,越是难以征服,越想征服它。
与C++相识是在C++98年代,如今已经是C++11 C++14甚至是C++17的年代了。有很多代码我竟然看不懂了,想当年我也是深入学习过C++语言的人。时代在进步,只能靠努力学习来弥补逝去的年华。
推荐几本C++学习的书籍,找到一本好书才是学习的最佳捷径。
《C++ Primer》《Effective C++》 《Inside The C++ object Model》 《C++ Template》《STL源码解析》按照顺序读,然后学习boost库,学完这一套,就可以用C++应付各种工作了。
对于C++的新特性可以参考《Effective Modern C++》以及《C++ Template第二版》
我认为任何事情都有因果关系,一门语言,一个功能的设计都是需求推动的,C++也不列外。
首先让我们思考一个问题,C++为什么在拥有指针的情况下加入了引用的概念。C++之父在《C++语言设计与演化》一书中提到加入引用的主要目的是为了操作符重载。如果形参使用值传递,那么实参的拷贝构造过程可能会消耗巨大的性能。如果使用指针,我们的代码可能就会写成这样c = &a+&b,它即丑陋又不方便。于是C++之父为了操作符重载加入了引用的概念。不仅如此,他还限制了引用的能力,引用必须初始化,并且一旦初始化就不能变更指向的对象。
int i = 0;
000B5AA2 mov dword ptr [i],0
int& ref_i = i;
000B5AA9 lea eax,[i]
000B5AAC mov dword ptr [ref_i],eax
int* ptr_i = &i;
000B5AAF lea eax,[i]
000B5AB2 mov dword ptr [ptr_i],eax 指针和引用的反汇编代码是一摸一样的,其实引用的底层实现就是type* const指针。
C#语言要想使用指针需要开启不安全代码(unsafe code)开发模式,可见指针是一把双刃剑,灵活强大但是危险重重。
对于C++语言我们到底如何选择指针和引用呢?放在10年前我会毫不犹豫的选择指针,因为它很酷,很强大。
现在我的选择是能用引用的地方尽量使用引用,因为它看上去清晰,使用方便,性能也不差,安全性又好。(PS:这里只是对比引用和指针,如果你说智能指针,就另当别论了)
考虑这样一个情景,假设我们有一个Object类,这个类里面结构非常复杂,它的创建依赖很多其它的类对象,我们使用一个叫做CreateObject的函数来创建Object对象。让我们忽略创建的细节,只考虑这个函数如何把创建的Object对象返回。我们先用指针进行返回值的传递。代码如下:
#include<iostream>
class Object
{
public:
Object()
{
std::cout << "默认构造函数" << std::endl;
}
~Object()
{
std::cout << "析构函数" << std::endl;
}
Object(const Object& demo)
{
std::cout << "拷贝构造函数" << std::endl;
}
Object& operator =(const Object& demo)
{
std::cout << "赋值构造函数" << std::endl;
return *this;
}
};
Object* CreateObject()
{
Object* pObject = new Object();
return pObject;
}
int main()
{
Object* mpObject = CreateObject();
delete mpObject;
}
代码很简单,让我们看看Object对象的创建和销毁情况。
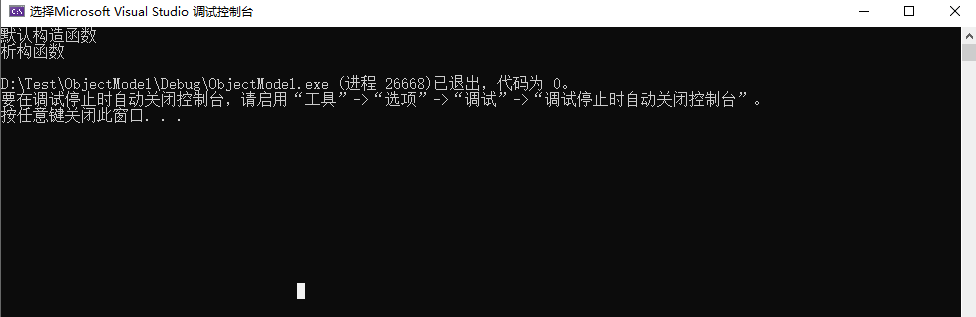
Object对象调用了一次默认构造函数,一次析构函数,很完美,唯一美中不足就是使用了指针。
接下来让我们用值传递的方式返回Object对象,代码只修改了CreateObject函数和main函数,Object类的代码没有改变。
Object CreateObject()
{
Object pObject;
return pObject;
}
int main()
{
Object object;
object = CreateObject();
}这里我必须强调一下C++的函数返回值会创建一个临时变量,这个临时变量会调用拷贝构造函数进行初始化。赋值操作结束后这个临时变量会被销毁。以上描述并不准确,我们暂时先这样理解。
还有一个事情需要强调C++并不保证默认的拷贝构造函数能够正确的处理所有的数据,它只是进行按位拷贝。如果类成员里面包含指针,数组,这种指向一块内存的数据,你需要考虑一下按位拷贝是不是你想要的行为。
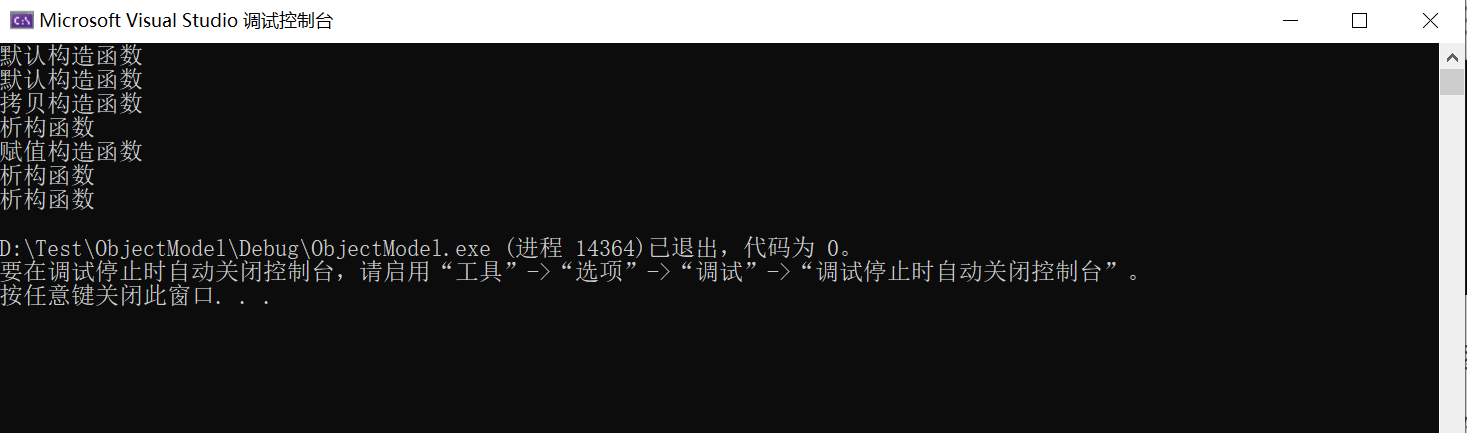
上面的输出结果非常不满意,我来解释一下每一个输出是怎么来的。
第一个默认构造函数是main函数中object初始化
第二个默认构造函数是CreateObject函数中pObject初始化
第三个拷贝构造函数是函数返回值临时变量的初始化
第四个析构函数是CreateObject函数中pObject对象的销毁
第五个赋值构造函数是对main中的object进行赋值
第六个析构函数是返回值临时变量的销毁
第七个析构函数是main中object的销毁
解释的又臭又长,让我们来对它进行优化,依然只是改变main和CreateObject这两个函数。
Object CreateObject()
{
std::cout << "CreateObject" << std::endl;
Object pObject;
return pObject;
}
int main()
{
Object object = CreateObject();
}
为了确定默认构造函数调用的顺序,我在CreateObject中加了一段输出。
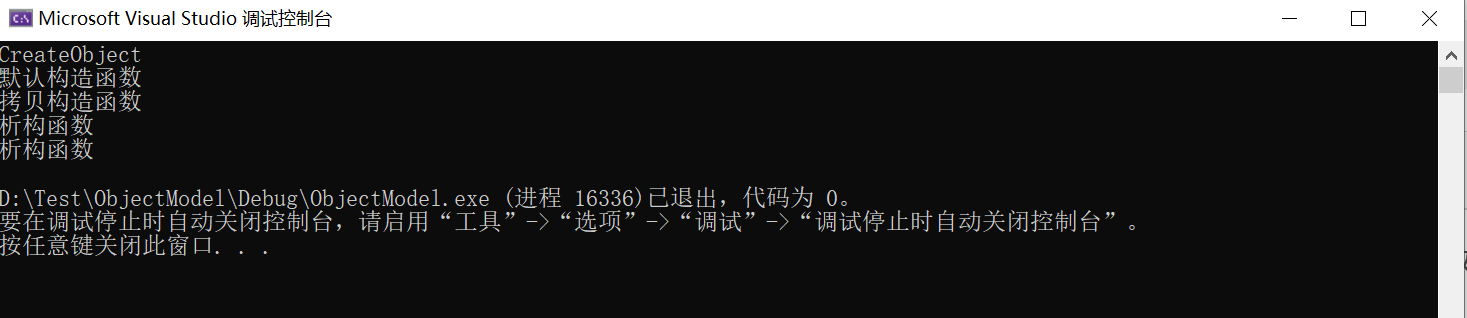
哇哦,看上去好了很多,解释一下每个输出。
第一个默认构造函数是CreateObject中的pObject的初始化,我们可以看到先输出了CreateObject
第二个拷贝构造函数是main中的object进行初始化
第三个析构函数是pObject的析构
第四个析构函数是object的析构
why???????为什么会是这样,我们考虑一下函数的调用顺序,CreateObject函数先被调用,然后函数返回,接着用返回值初始化object。这里有一个问题如何把函数的返回值保存下来,因为CreateObject函数结束后,pObject这个局部变量会被销毁。因此我们需要一个临时变量保存函数的返回值,待它使用完毕后再对他进行销毁。
很明显这个例子并没有创建一个临时变量,这是编译器的一个优化,这个优化的名字叫做NRV(具体参见Inside the c++ object model第二章)。
它会把object对象直接传入到CreateObject函数中然后调用一个拷贝构造函数进行初始化,下面是编译器优化的伪代码:
void CreateObject(Object& ref_object)
{
Object object;
//...进行各种处理
res_object(object);//调用拷贝构造函数初始化ref_object
return;
}
void main()
{
Object object;//不必调用默认构造函数
CreateObject(object);
}为什么上个例子编译器不会做优化呢?这个我没有在书上找到答案,说一下自己的理解吧。
首先上个例子中的object是被构建完成后进行的赋值,既然已经构建完成,我们就不能再对它调用拷贝构造函数了,因此不能使用上述的优化方案。
那我们也可以在CreateObject函数中直接对引用的ref_object做赋值操作,这样也就不用创建临时变量了。咳咳,引用一旦初始化是不能被赋值的,ref_object已经被实参绑定了。那我们不用引用,用值传递。值传递参数又会拷贝一个临时变量,问题又绕回到了原点。
其实可以使用指针将object对象的地址传递到CreateObject函数中,然后调用赋值操作,这样是行得通的,为什么编译器不用,这个就不清楚了。
接下来让我们修改一下Object类,在里面加一个移动构造函数,CreateObject和main函数不变。
class Object
{
public:
Object()
{
std::cout << "默认构造函数" << std::endl;
}
~Object()
{
std::cout << "析构函数" << std::endl;
}
Object(const Object& demo)
{
std::cout << "拷贝构造函数" << std::endl;
}
Object& operator =(const Object& demo)
{
std::cout << "赋值构造函数" << std::endl;
return *this;
}
Object(Object&& object)
{
std::cout << "移动构造函数" << std::endl;
}
};我们增加了一个移动构造函数,这是C++11新增加的特性,其中的Object&&就代表了右引用,我们先不要纠结这个新名词,先看一下C++为什么会 引入这个新特性。
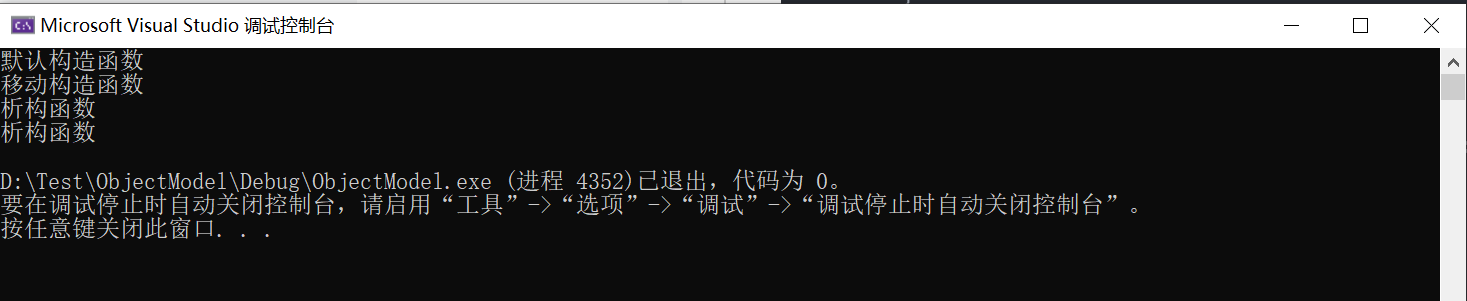
首先我们可以看到之前的拷贝构造函数被换成了移动构造函数,其次编译器依然做了优化并没有产生临时对象。
看上去C++11新增加的这个特性没什么用啊,我们可以在移动构造函数里面初始化对象,也可以在拷贝构造函数里面做啊。
关键就在这两个函数的形参上,拷贝构造函数的形参必须是const type&,这是对被拷贝对象的一种保护,而移动构造函数的形参是object&& type(当然你也可以加上const,但是没人会这么做),这样我们就可以在移动构造函数里面修改被拷贝对象了。
假设我们Object类里面有一个指针,这个指针指向一块内存地址,为了安全起见通常我们会copy这块内存中的内容,以免两个指针指向同一个地址。因为一个对象被析构后,另一个对象中的指针就会变成野指针。
这样做很安全,但是效率不高,有的时候被拷贝的对象是一个临时对象,我们希望直接把临时对象拿过来用,而不是再copy一份。
要想这么做我们需要修改被拷贝对象的指针,将其置空,否则临时对象生命周期结束后会析构指针指向的地址。但是拷贝构造函数做不到,因为它被声明位const type&。C++11只能增加一个移动构造函数来处理这个问题,并增加右引用来专门匹配临时变量这种参数。
好了现在我们清楚为什么C++11会引入拷贝构造函数和右引用这两个新特性了,当然这只是其中的一个原因。
说一下什么是右引用,右引用就是对右值的引用,什么是左值和右值。网上对左值右值有很多不同的定义,我个人觉得最简单的理解就是左值能够通过&取地址,右值不能通过&取地址。临时对象是一个匿名对象,连名字都没有,我们怎么通过&取地址呢?
CreateObject函数返回的是一个匿名对象,它是一个右值,因此被分配到了移动构造函数上去处理。
总结一下重点:
1.即便是一个简单的初始化操作不同的写法也会造成不同的性能消耗,这就是C++复杂的地方
2.拷贝构造函数和移动构造函数最大的区别就是能否修改被拷贝对象
3.能够取地址的对象都是左值,不能够的是右值
4.左引用指向左值对象,右引用指向右值对象

















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









