







之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,算是一个知识积累,同时也分享给大家。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Flink-1.19.x,Flink支持多种语言,这里的所有代码都是使用java,JDK版本使用的是19。
代码参考:https://github.com/forever1986/flink-study.git
目录
通过前面两章的FlinkSQL的入门基础讲解,相信对FlinkSQL应该有一个初步的了解,接下来将会大概按照之前Data Stream API的内容顺序,来讲解FlinkSQL的实现。这里尽量保持与前面Data Stream API的讲解目录顺序一致,这样让读者能够很好的理解。这一章主要讲解源算子和输出算子,与《系列之六 - Data Stream API的源算子》和《系列之十二 - Data Stream API的输出算子》一致,不记得的朋友可以回顾一下,或者可以对比一下FlinkSQL的区别。
1 源算子(Source)和输出算子(Sink)
关于源算子和输出算子,在Data Stream API中已经讲过,源算子就是指定加载/创建初始数据,是一个数据来源;而输出算子则是将数据流输出到外部的存储,Flink将源算子和输出算子独立提取为Connector模块,制定连接一个数据源的规范,并且Flink目前支持很多外部数据Connector,包括集合、文件、kafka、数据库等等。在FlinkSQL中,也是同样支持使用这些Connector。但是要注意以下两点不同:
- 1)原先Data Stream API支持的源算子,FlinkSQL不一定支持,具体参考《官方文档》
- 2)引入的jar可能不同,虽然Flink已经尽可能将相同的source的jar统一为一个,但是可能有些jar还未改进。因此原先Data Stream API引入的jar一般是flink-connector-XXX,而FlinkSQL可能会引入以flink-sql-connector-XXX的jar包。这个以官方文档为准。
以下是截止到目前为止官方网站关于FlinkSQL支持的源算子:
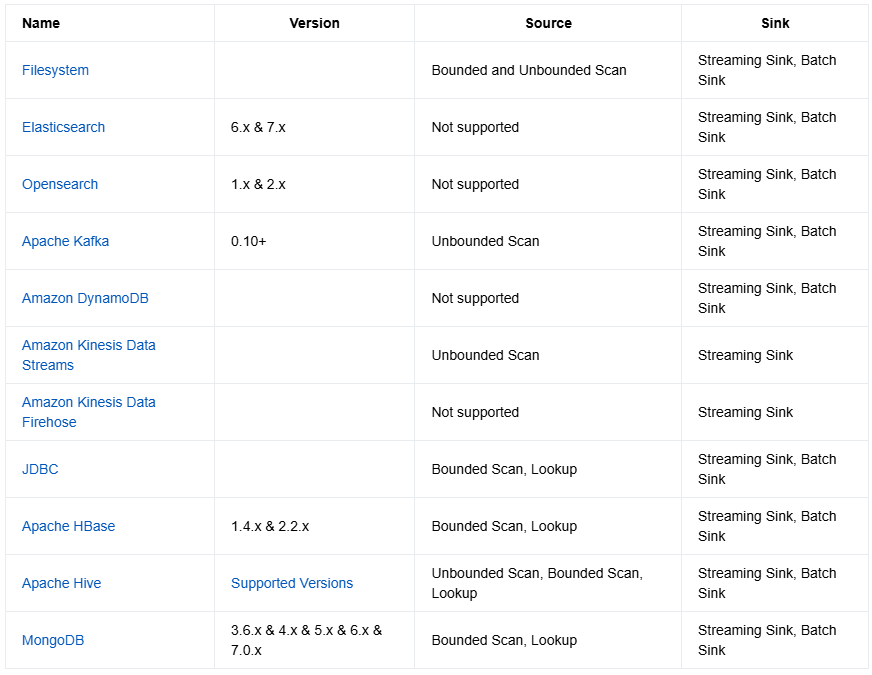
说明:
- Not supported :不支持作为源算子
- Bounded Scan :源算子作为有界流接入,意味着只能通过时间范围一次性查询,但是后续更新的内容无法同步。(相当于Batch操作)
- Unbounded Scan :源算子作为无界流接入,意味着会实时同步,更新数据也会进行同步。
- Lookup : Lookup也是一次性查询,但是与 Bounded Scan查询模式不同,Bounded Scan 是对一个时间范围内的数据进行查询,而 Lookup 查询只会对一个精确的时间点进行查询,所以查询结果只有一行数据。
- Streaming Sink :输出算子以流方式输出到目标外部系统中
- Batch Sink:输出算子以批方式输出到目标外部系统中
2 常见Connector
2.1 FileSystem
2.1.1 说明
FileSystem 连接器:此连接器提供对文件系统中分区文件的访问。文件系统连接器本身包含在 Flink 中,不需要额外的依赖jar包。

FileSystem的具体语法如下(全部语法参照《官方文档-FileSystem》):
CREATE TABLE MyUserTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- required: specify the connector
'path' = 'file:///path/to/whatever', -- required: path to a directory
'format' = '...', -- required: file system connector requires to specify a format,
-- Please refer to Table Formats
-- section for more details
'partition.default-name' = '...', -- optional: default partition name in case the dynamic partition
-- column value is null/empty string
'source.path.regex-pattern' = '...', -- optional: regex pattern to filter files to read under the
-- directory of `path` option. This regex pattern should be
-- matched with the absolute file path. If this option is set,
-- the connector will recursive all files under the directory
-- of `path` option
-- optional: the option to enable shuffle data by dynamic partition fields in sink phase, this can greatly
-- reduce the number of file for filesystem sink but may lead data skew, the default value is false.
'sink.shuffle-by-partition.enable' = '...',
...
)
2.1.2 示例演示
本实例通过将一个log.csv文件读取到log表,准备一个log.csv,放到指定位置/opt/data目录下
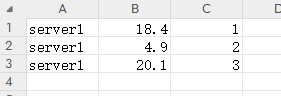
1)查询数据演示:在sql-client客户端下,创建log表,关联/opt/data目录,并查询表
CREATE TABLE log (
id STRING,
cpu DOUBLE,
ts INT
) WITH (
'connector' = 'filesystem',
'path' = '/opt/data',
'format' = 'csv'
);
SET sql-client.execution.result-mode=TABLEAU;
select * from log;
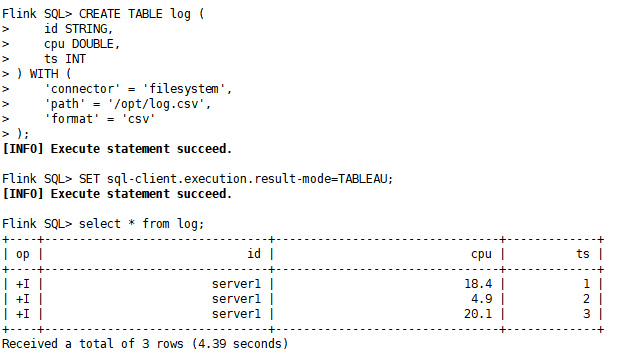
2)插入数据演示:插入一条数据,并重新查询表
insert into log values('server1',40.2,4);
select * from log;
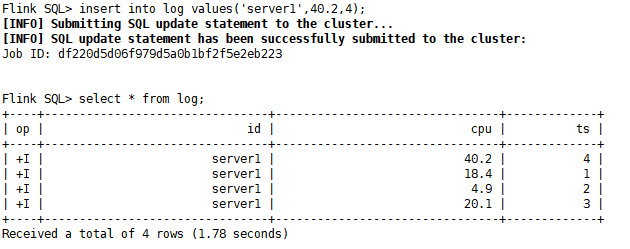
3)更新数据演示:更新记录,可以发现FlieSystem不支持update

2.2 DataGen
2.2.1 说明
DataGen 连接器 :就是生成数据的源算子。在开发过程中,往往需要一些测试数据,这时候就可以使用DataGen生成测试数据,而不用连接第三方数据源系统。因此DataGen只能作为源算子。
具体语法可以参考《官方文档-DataGen 》
2.2.2 示例演示
其实在《系列之二十四 - Flink SQL - 基础操作》中就已经做过演示,这里使用同样一个案例作为演示:
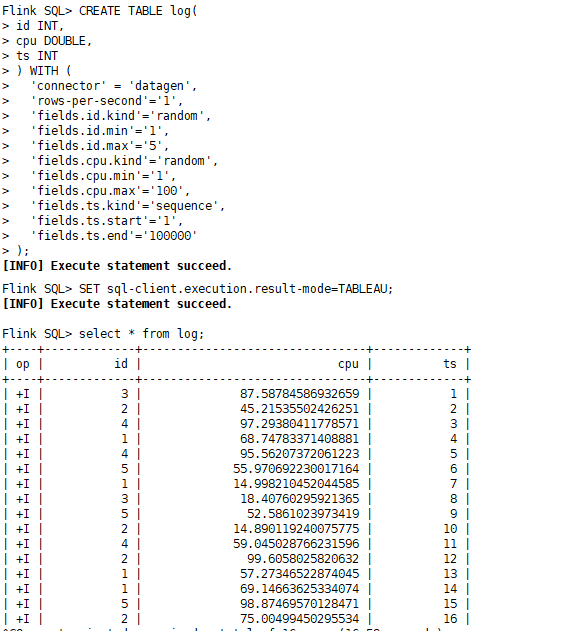
CREATE TABLE log(
id INT,
cpu DOUBLE,
ts INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
'fields.id.kind'='random',
'fields.id.min'='1',
'fields.id.max'='5',
'fields.cpu.kind'='random',
'fields.cpu.min'='1',
'fields.cpu.max'='100',
'fields.ts.kind'='sequence',
'fields.ts.start'='1',
'fields.ts.end'='100000'
);
SET sql-client.execution.result-mode=TABLEAU;
select * from log;
2.3 JDBC
2.3.1 说明
JDBC 连接器:允许使用 JDBC 驱动程序从任何关系数据库中读取数据或将数据写入其中。连接数据库需要注意一点:如果在Flink上创建表时定义了主键,则 JDBC 接收器将在 upsert 模式下运行,插入主键相同的数据,Flink会自动进行更新操作;否则,在没有定义主键情况下,它将在 append 模式下运行,并且不支持自动更新操作,会在Web-UI控制台任务显示错误。
2.3.2 示例演示
1)准备mysql数据库:准备一个mysql数据库,数据库名称为flink,创建数据库表,脚本如下:
CREATE DATABASE flink;
use flink;
CREATE TABLE log (
id varchar(100) NOT NULL,
cpu DOUBLE NULL,
ts INT NULL,
PRIMARY KEY (id)
)
ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4;
2)上传connector的jar:需要将connector的jar和mysql连接驱动的jar上传到Flink服务器的lib目录下面

3)重启Flink集群
./stop-cluster.sh
./start-cluster.sh
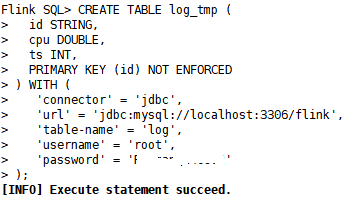
4)创建log_tmp表:启动sql-client客户端,并在flink中创建log_tmp表
CREATE TABLE log_tmp (
id STRING,
cpu DOUBLE,
ts INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink',
'table-name' = 'log',
'username' = 'root',
'password' = '自己的密码'
);
5)插入数据
insert into log_tmp values('server1',40.2,4);

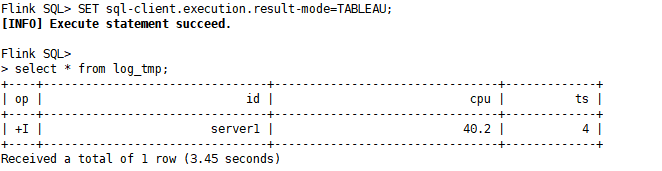
6)在Flink客户端查看结果
SET sql-client.execution.result-mode=TABLEAU;
select * from log_tmp;
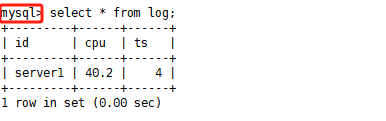
7)在mysql客户端查看结果:通过mysql的客户端,查看插入数据(注意:这里是mysql客户端,不是flink客户端)
注意:在flink客户端中创建log_tmp表时,使用PRIMARY KEY (id) NOT ENFORCED,指定主键。
- 当指定了主键,则再次插入与主键相同的数据,则会对数据进行更新操作(指定主键时,mysql数据库表也要设定主键)
- 当未指定主键,则再次插入与主键相同的数据,在Web-UI中可以看到任务执行失败,并不会进行更新操作。
2.4 MongoDB
2.4.1 说明
MongoDB连接器:允许从 MongoDB 读取数据以及将数据写入 MongoDB。跟JDBC一样,如果Flink创建表时注明了主键,连接器可以在 upsert 模式下运行,会自动更新主键相同的数据。如果未定义主键,则连接器只能在 与外部系统交换仅 INSERT。
2.4.2 示例演示
1)准备mongoDB:安装mongoDB,并创建数据库flink,同时创建集合和用户,脚本如下
use flink
db.createCollection("log")
db.createUser({ user: "flink_user", pwd: "3KgkR2oY9k22Y3e5", roles: [ { role: "dbOwner", db: "flink" } ] })
2)上传connector的jar:需要将connector的jar和mongo连接驱动的jar上传到Flink服务器的lib目录下面(可以看到mongo的连接器还是带有sql的,与Data Stream API依赖的jar不一样)

3)重启Flink集群
./stop-cluster.sh
./start-cluster.sh
4)创建log_tmp表:启动sql-client客户端,并在flink中创建log_tmp表
CREATE TABLE log_tmp (
_id STRING,
cpu DOUBLE,
ts INT,
PRIMARY KEY (_id) NOT ENFORCED
) WITH (
'connector' = 'mongodb',
'uri' = 'mongodb://flink_user:3KgkR2oY9k22Y3e5@127.0.0.1:27017',
'database' = 'flink',
'collection' = 'log'
);
5)插入数据
insert into log_tmp values('server1',40.2,4);
6)在Flink客户端查看结果
SET sql-client.execution.result-mode=TABLEAU;
select * from log_tmp;
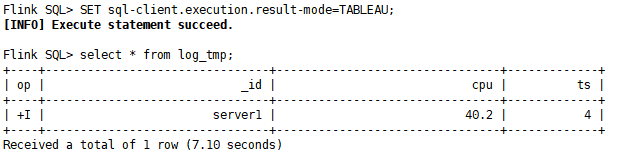
7)在mongo客户端查看结果
db.log.find()

2.5 Kafka
2.5.1 说明
Kafka 连接器:允许从 Kafka 主题读取数据以及将数据写入 Kafka 的topic。
2.5.2 示例演示
1)准备kafka:准备好一个安装完成的kafka服务器
2)上传connector的jar:需要将connector的jar上传到Flink服务器的lib目录下面

3)重启Flink集群
./stop-cluster.sh
./start-cluster.sh
4)创建log_tmp表:启动sql-client客户端,并在flink中创建log_tmp表
CREATE TABLE log_tmp (
`id` STRING,
`cpu` DOUBLE,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'log',
'properties.bootstrap.servers' = '172.18.4.10:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'sink.partitioner' = 'fixed',
'format' = 'json'
);
5)插入数据
insert into log_tmp(id,cpu) values('server1',12.8);

6)查询数据
SET sql-client.execution.result-mode=TABLEAU;
select * from log_tmp;

注意:这个示例中创建log_tmp表时,使用METADATA FROM ‘timestamp’,这是元数据字段,就是将元数据字段timestamp赋值给ts列,因此在插入数据时,无需插入ts列。而kafka中有多少元数据,可以在《官方文档的Connector的Kafka》获取。
2.6 Upsert Kafka
2.6.1 说明
Upsert Kafka 连接器:允许以 upsert 方式从 Kafka 主题读取数据以及将数据写入 Kafka 主题。有了一个kafka的连接器,为什么还需要另外一个*Upsert Kafka 连接器呢?在《系列之二十三 - Flink SQL - 开篇》中的表转换为流,有三种方式,其中有一种叫做 Upsert 流 。 上面 Kafka连接器 实现的是一种 Retract 流 ,而 Upsert Kafka 连接器 就是实现 Upsert 流 的。
2.6.2 示例演示
1)创建log_tmp表:启动sql-client客户端,并在flink中创建log_tmp表
CREATE TABLE log_tmp2 (
`id` STRING,
`cpu` DOUBLE,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp',
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'log2',
'properties.bootstrap.servers' = '172.18.4.10:9092',
'key.format' = 'json',
'value.format' = 'json'
);
2)插入数据
insert into log_tmp2(id,cpu) values('server1',12.8);
insert into log_tmp2(id,cpu) values('server1',20.5);
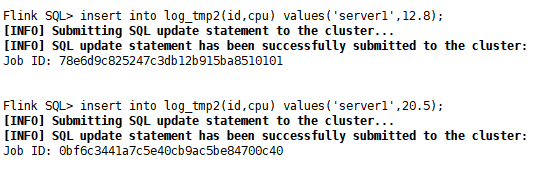
3)查询数据
SET sql-client.execution.result-mode=TABLEAU;
select * from log_tmp2;

3 Connector帮助文档
前面演示了一些常见的Connector,当然Flink中还有很多的Connector,这里讲不完。这里教大家如何通过查看帮助文档,学习Connector的使用,这样即便没有演示的Connector,大家也可以通过帮助文档学习。下面以Kafka Connector为例讲解,下图是《Kafka Connector官方文档》的目录:
很多Connector的目录都是差不多,这里会讲解一些共同的点:
1)Dependencies:主要是描述和下载依赖的jar包,当你要使用该Connector时,可以从这里下载jar
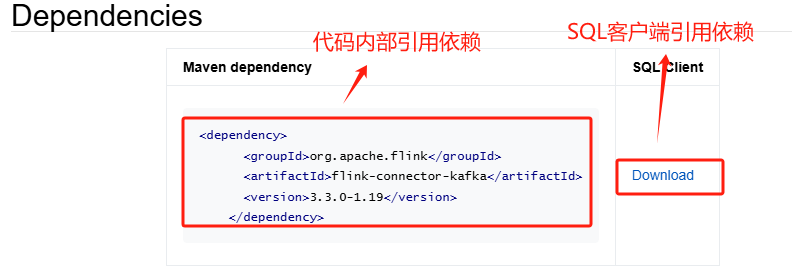
2)How to create a Kafka table :这一部分主要是教大家如何在Flink中创建一张表的语法

3)Available Metadata :这是Connector中自带的元数据列,这个每个Connector不一样,比如Kafka中就有一个列叫做topic,你可以定义表的时候,将其放入到表中某一列。

4)Connector Options :连接器的配置选择,一般先看必须填写的选项,再学习可选的选项。
5)Data Type Mapping :这是外部系统的字段类型与Flink中的字段类型对应,如果有的话,必须先了解
因此学习一个Connector如何使用,基本上就先看这几部分,再详细学习其中特殊的内容。
结语:本章将源算子和输出算子放在一起讲,是因为之前在Data Stream API 已经学习过,写入和写出都是有共性,因此放在一起讲。接下来会讲解中间算子。



















 2768
2768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











