








 该专栏为热销专栏榜 第62名
该专栏为热销专栏榜 第62名
随机森林的基本原理是什么?
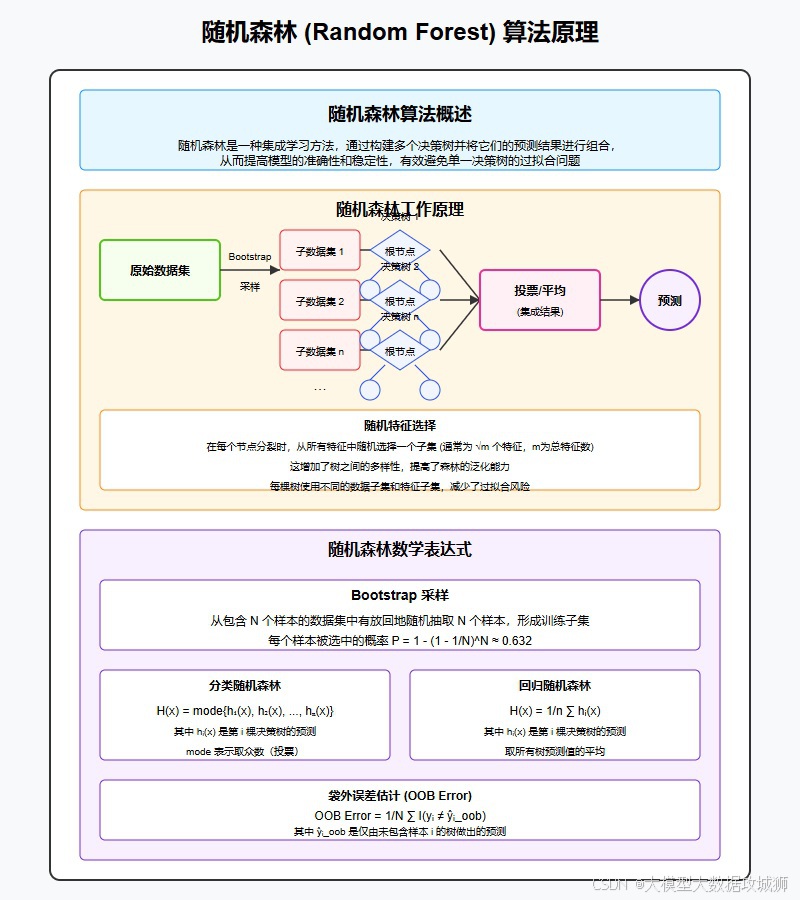
随机森林是一种基于决策树的集成学习算法。它从原始训练数据集有放回地随机抽取多个子样本集,然后基于每个子样本集构建一棵决策树,最后将这些决策树的结果进行综合,从而得到最终的预测结果 。
在训练阶段,首先通过自助采样法,即从原始数据集中有放回地抽取多个与原始数据集样本量相同的子数据集。例如,若原始数据集有 1000 个样本,那么可能抽取 100 个子数据集,每个子数据集也有 1000 个样本,但其中会有部分样本是重复的。然后针对每个子数据集分别构建一棵决策树,在构建决策树的过程中,每次从所有的特征中随机选择一部分特征来进行节点分裂的计算,而不是使用全部特征。这样可以降低树之间的相关性,增加模型的多样性。
当进行预测时,对于分类问题,通常采用投票的方式,即每棵决策树对样本的分类结果进行投票,得票最多的类别即为最终的预测类别。对于回归问题,则是对每棵决策树的预测结果进行平均或加权平均等操作来得到最终的预测值。通过这种方式,随机森林能够利用多个决策树的集体智慧,提高模型的准确性和稳定性,减少过拟合的风险,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











