




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 蚂蚁百灵开源两款思考模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在过去几年里,人工智能领域最激动人心的故事,莫过于大模型的“参数竞赛”。从几百亿到上万亿,参数量一度成为衡量模型能力的最直接、最粗暴的标尺。然而,当这些“性能猛兽”真正要走出实验室、进入千行百业的实际应用时,一个极其现实的问题摆在了所有企业面前:太贵了。
高昂的推理成本——也就是模型每次响应用户请求时消耗的计算资源——就像一道无形的墙,阻碍了AI技术的规模化落地。用户希望与AI进行更长、更复杂的对话,企业则希望模型能处理海量的文档和数据,但每一次交互背后,都是实打实的算力在燃烧。
正是在这个背景下,AI赛道的风向开始悄然转变。大家不再仅仅追求“更大”,而是开始探索如何让模型在保持强大能力的同时,变得“更聪明”、“更高效”、“更省钱”。近日,蚂蚁集团百灵大模型团队的一次重磅开源,正是对这一趋势的有力回应。他们推出的两款新模型——`Ring-mini-linear-2.0`与`Ring-flash-linear-2.0`,给出了一个极具吸引力的答案:推理成本直降90%。
一、AI为什么这么“贵”?问题的核心在“注意力”
要理解蚂蚁这次的技术突破,我们得先简单了解一下大模型为什么这么耗费资源,尤其是在处理长文本时。
问题的核心在于一种叫做“注意力机制”(Attention)的技术。你可以把它想象成模型在阅读一段文字时,为了理解某个词的含义,需要回顾上文中所有其他词与它的关系。这个机制非常强大,是大模型能够理解上下文、进行逻辑推理的关键。
但它有一个天生的“缺陷”:计算量会随着文本长度的增加而呈平方级增长。也就是说,文本长度增加1倍,计算量可能增加4倍;长度增加10倍,计算量就暴增100倍。这就是为什么当你输入一篇长长的报告让AI总结时,它会响应得更慢,消耗的成本也更高。
二、蚂蚁的解决方案:一套“混合动力”引擎
面对这个行业难题,蚂蚁的工程师们没有选择常规的优化路线,而是设计了一套巧妙的“混合动力”系统。这套系统的核心是两大关键技术:稀疏MoE架构 和 混合线性注意力。
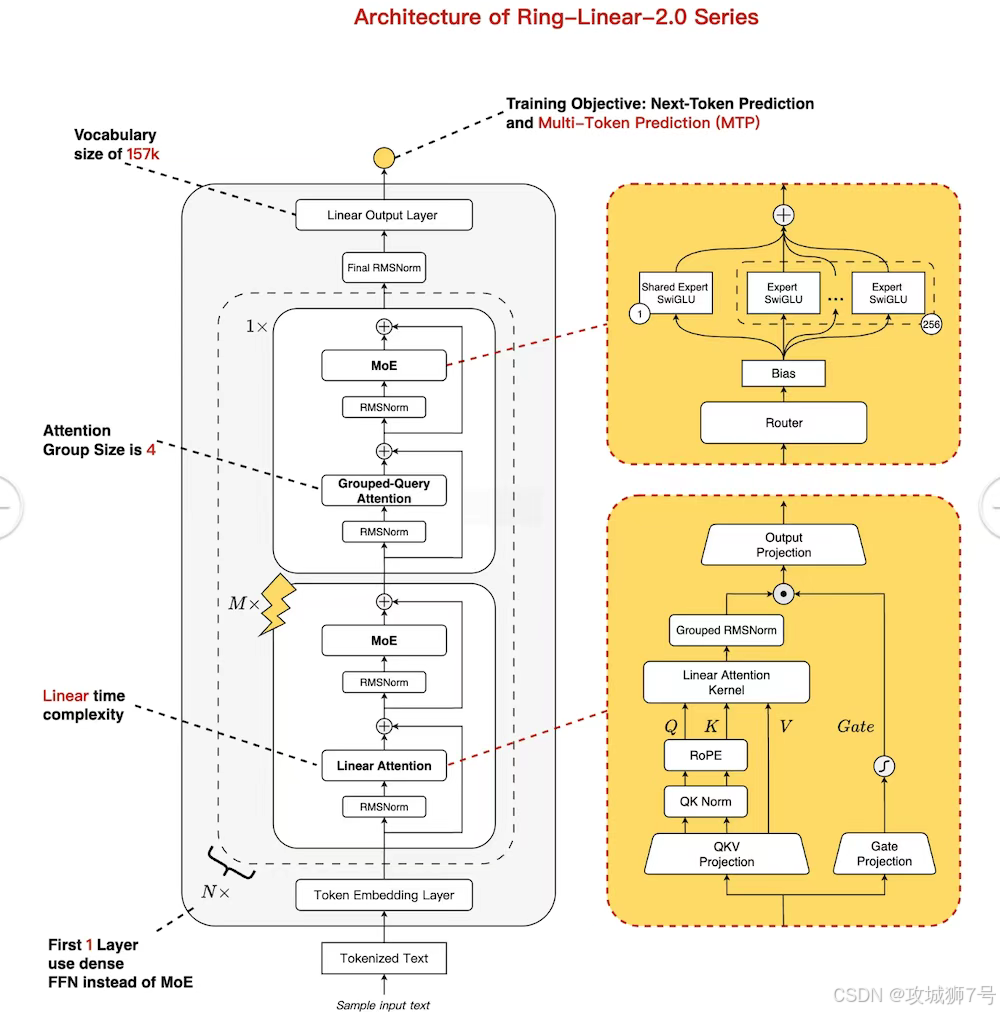
(1)稀疏MoE:从“全员加班”到“专家会诊”
MoE(Mixture of Experts,专家混合)架构,是近年来非常流行的一种模型设计思路。传统的“密集模型”(Dense Model),在处理任何任务时,都需要调动体内全部的参数,就像一个公司,不管大事小事,所有员工都得一起上阵,效率低下且成本高昂。
而MoE则像一个拥有众多专家的智库。当一个任务进来时,模型会自动判断这个任务属于哪个领域,然后只激活(“唤醒”)一小部分最相关的“专家”参数来处理。比如,处理代码问题时就找“编程专家”,写诗就找“文学专家”。
蚂蚁的Ring系列模型采用了“超稀疏”的MoE结构,每次只有1/32的专家被激活。这意味着,一个名义上拥有400亿参数的模型,在实际运行时可能只动用了60亿左右的参数。这就好比用一支精锐小分队的成本,达到了一个庞大军团的效果,极大地降低了能耗和计算需求。
(2)混合线性注意力:既要“快”,又要“准”
为了解决前面提到的注意力机制在长文本上的效率瓶颈,研究者们提出了一种“线性注意力”(Linear Attention)。它通过算法上的革新,将计算复杂度从平方级降到了近乎线性级,处理长文本的速度大大加快。
但是,线性注意力在精度上相比标准注意力,有时会略有损失。为了兼顾速度与质量,蚂蚁团队开创性地采用了“混合架构”:在模型的大部分(87.5%)层级中使用高效的线性注意力,保证处理长文本时的速度优势;同时,保留一小部分(12.5%)标准的注意力层,用于处理最关键的语义信息,确保模型的理解能力和准确率不打折扣。
这种“快慢结合”的设计,如同汽车的混合动力引擎,在高速巡航时用省油的模式,在需要强劲动力时切换到高性能模式,最终实现了性能与成本的最佳平衡。
三、降本90%意味着什么?
技术革新的最终价值,要体现在实际效果上。根据蚂蚁团队的实测数据,这套“混合动力”系统带来了惊人的提升:
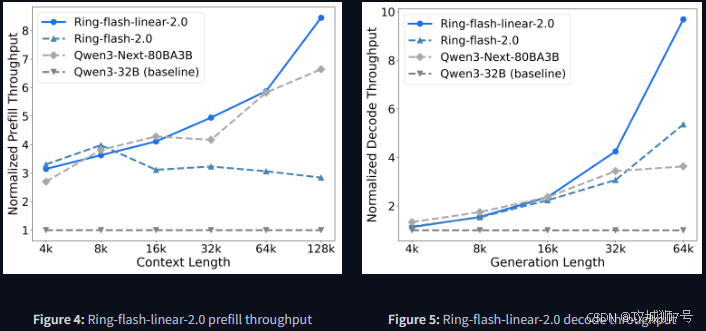
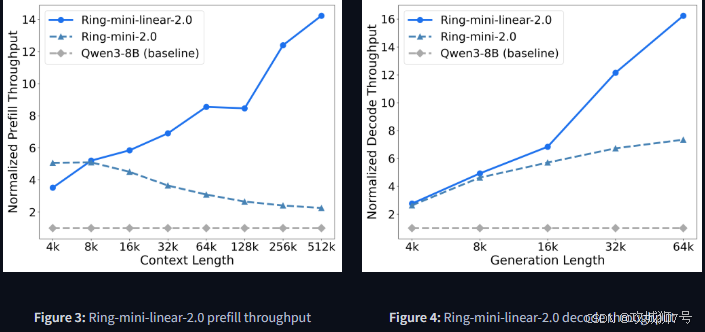
(1)成本:在处理512k(约合百万汉字)的超长文本时,推理成本压缩至传统密集模型的十分之一。与蚂蚁自家的上一代Ring模型相比,成本也降低了50%以上。
(2)速度:在高并发场景下,新模型的吞吐量(单位时间内处理请求的能力)可以达到业界主流开源模型(如Qwen3-8B)的12倍以上。
这意味着什么?对于企业来说,可以用同样的预算,支持10倍的用户查询量,或者处理10倍的文档数据。对于开发者,这意味着部署大模型的硬件门槛大大降低。对于普通用户,这意味着更快、更流畅的AI交互体验。
更重要的是,这种极致的性价比并没有以牺牲性能为代价。在数学推理、代码生成、语言理解等多个标准测试中,这两款模型都表现出了与更大规模模型相媲美的竞争力。它们可以根据自然语言指令,生成结构清晰、可直接运行的数独游戏、坦克大战游戏,甚至是模拟股票交易软件的前端代码。
四、从“能用”到“好用”:解决AI训练的深层难题
除了降本增效,蚂蚁团队还解决了MoE模型在强化学习(RL)训练中的一个关键瓶颈:训推不一致。
简单来说,就是模型在“学习”(训练)时和“考试”(实际应用)时,因为环境的细微差别,表现会不一样,导致学习效果打折扣。蚂蚁团队从底层算子层面统一了训练和推理的逻辑,确保模型“学到的就是用到的”,大大提升了训练的稳定性和最终效果。这为MoE这类复杂模型走向更高级的AI阶段扫清了障碍。
结语:AI进入“精打细算”的新时代
从追逐万亿参数的“庞然大物”,到如今精巧设计的“效率先锋”,蚂蚁百灵Ring-linear系列模型的开源,清晰地揭示了AI行业发展的下一个方向。
它构建了一个从通用基座(Ling-1T)到推理先锋(Ring-1T-preview),再到轻量化标兵(Ring-mini-linear)和长文本王者(Ring-flash-linear)的能力金字塔。这表明,AI的未来不再是“一招鲜吃遍天”,而是为不同场景、不同需求提供梯度化、专业化的解决方案。
当AI的算力成本不再是高不可攀的门槛,当高效、经济的模型变得触手可及,这项变革性的技术才能真正渗透到我们生活和工作的方方面面。蚂蚁的这次开源,无疑为加速这一进程,又推开了一扇重要的门。
开源地址:Ring-V2/hybrid_linear at main · inclusionAI/Ring-V2 · GitHub



















 2万+
2万+






 到【灌水乐园】发言
到【灌水乐园】发言









