




目录
3.1 第一步:“非推理”监督微调 (Non-Reasoning SFT)

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 微软开源的rStar2-Agent
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
AI领域曾奉“大力出奇迹”为圭臬:模型参数从百亿卷至万亿,“长思维链”成提升智能的主流路径,OpenAI o系列、DeepSeek-R1等顶尖模型沿此成功。
但这条路渐显天花板:竞赛级数学题中,模型即便写万字解题步骤,也可能因一步小错满盘皆输,且难自纠。
此时微软研究院的`rStar2-Agent`研究投下“深水炸弹”,提出颠覆性观点:让AI“更聪明思考”,远比“更长时间思考”重要。
他们用140亿(14B)参数模型,在多难度基准上媲美甚至超越6710亿(671B)参数的DeepSeek-R1,且仅需64块GPU训练一周。
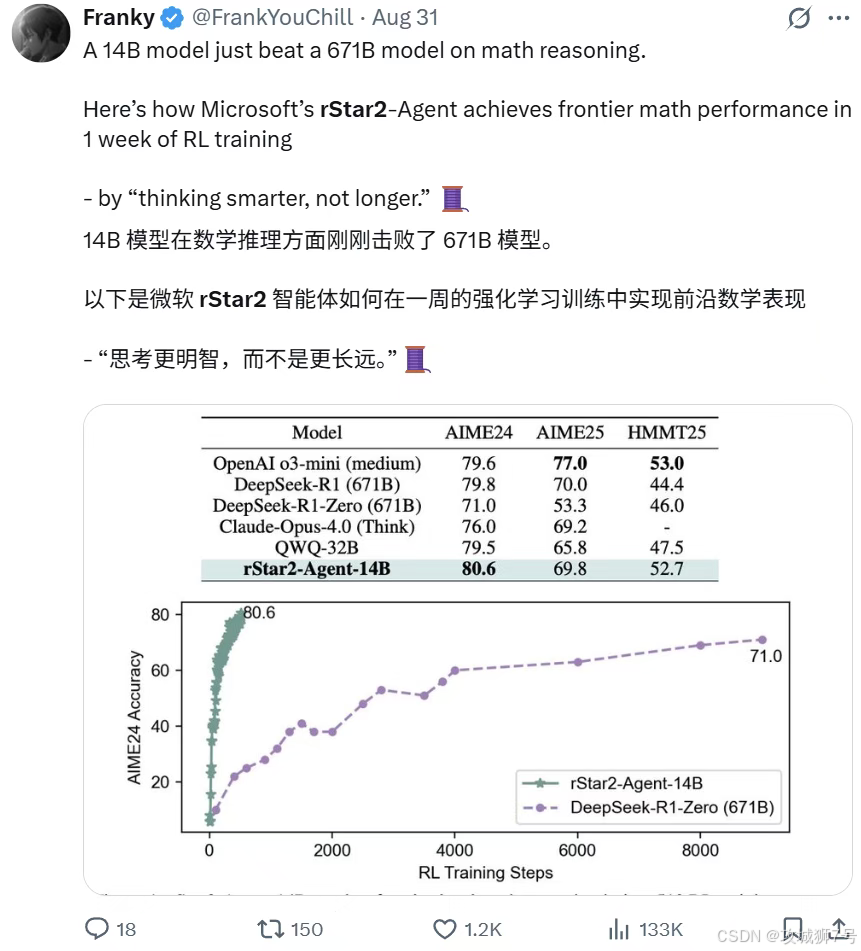
这不仅是“四两拨千斤”的技术胜利,更可能预示AI推理范式革命。今天我们就解析,rStar2-Agent如何让小模型学会“更聪明思考”。
一、从“纸上谈兵”到“动手实验”:智能体强化学习的威力
传统思维链(CoT)模型,像一个只会在纸上演算的学生。他可以写下长篇大论的推理过程,但缺乏与现实世界互动的能力。他无法使用计算器来验证中间结果,也无法从错误中获得即时反馈。
`rStar2-Agent` 的核心思想,就是将这个学生,变成一个能够动手做实验的“智能体”(Agent)。它不再局限于自身的“内心独白”,而是被赋予了与外部环境——一个Python编程和解释器——进行交互的能力。
这意味着,模型在解决问题时,可以:
(1)提出假设:构思一个解题步骤。
(2)动手验证:将这个步骤写成Python代码,并让解释器运行。
(3)观察反馈:如果代码运行成功,它会得到一个确切的结果;如果代码有误,它会收到一条明确的错误信息。
(4)学习调整:根据这些来自环境的、真实的反馈,来调整自己的下一步策略。
这种“提出假设-动手验证-观察反馈-学习调整”的闭环,就是所谓的智能体强化学习(Agentic Reinforcement Learning)。它让模型从一个封闭的“思考者”,变成了一个开放的“探索者”。
二、GRPO-RoC算法:在“嘈杂”的环境中学会优雅
让AI使用工具听起来很美,但实践中却有一个巨大的“坑”——环境噪声。
想象一下,一个新手程序员在解题,他写的代码可能充满语法错误和逻辑bug。Python解释器会不断返回各种错误信息。在传统的强化学习中,通常只看最终答案是否正确来给予奖励。这就导致了一个严重的问题:一个模型可能写了九次错误代码,第十次歪打正着蒙对了答案,系统依然会给它满分奖励。
这种机制,无异于在鼓励一种混乱、低效、充满“脏动作”的解题方式。模型学会的不是严谨的推理,而是“只要能蒙对,过程不重要”。
为了解决这个核心难题,微软的研究者们提出了一种极其精妙的算法——GRPO-RoC(带有正确重采样的组相对策略优化)。这个名字很长,但其核心思想——“正确重采样”(Resample-on-Correct, RoC)——却异常简洁和高效。
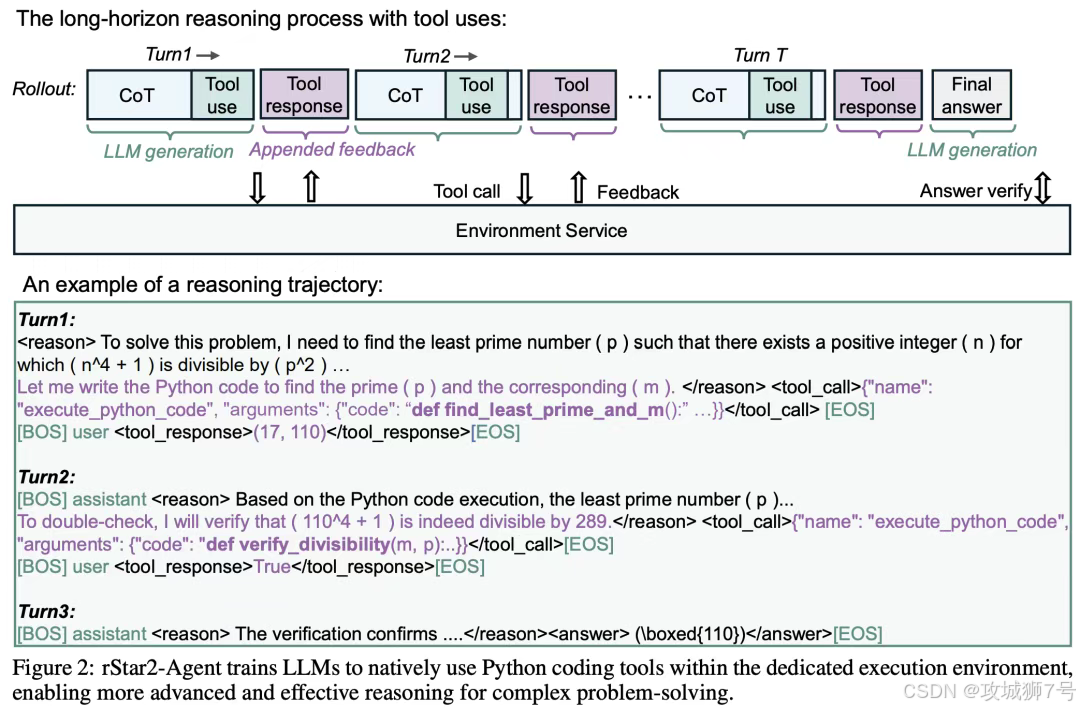
我们可以把它理解为一位高明的“AI教练”,它的教学方法是:
(1)超量练习与分类:首先,让模型对一个问题,生成远超常规数量的解题尝试(比如32次)。然后,将这些尝试根据最终答案的对错,分为“成功组”和“失败组”。
(2)从失败中学习“禁区”:对于“失败组”,教练会随机抽取一部分“错题案例”,让模型学习,告诉它“这些路是走不通的”,从而避免再犯。
(3)从成功中学习“品味”:这是最关键的一步!对于“成功组”,教练变得异常“挑剔”。它不会把所有答对的都当成范本,而是会根据解题过程的“质量”进行筛选。质量如何衡量?主要看两点:工具使用错误率和格式规范性。那些代码写得干净利落、工具用得精准、格式完美的“高分作文”,会有更大概率被选中,作为正面榜样来指导模型的学习。
这个算法的精髓在于,它没有去设计复杂的规则来惩罚每一种错误(这很容易被模型“钻空子”),而是通过在数据层面进行“非对称”的筛选,巧妙地提升了学习材料的质量。
它告诉模型:“不仅要答对,更要答得漂亮。”
通过这种方式,`rStar2-Agent` 不仅学会了如何解决数学问题,更在潜移默化中,成了一名更优秀的“程序员”和一个更高效的“工具使用者”。
三、反直觉的训练配方:“先学用锤子,再学造房子”
拥有了顶尖的算法,还需要高效的训练策略。`rStar2-Agent` 的训练“配方”同样与众不同,甚至有些反直觉。
3.1 第一步:“非推理”监督微调 (Non-Reasoning SFT)
在进行强化学习之前,绝大多数模型都会先进行“推理SFT”,即用大量带详细解题步骤的例子来“喂”模型,让它模仿。

`rStar2-Agent` 却反其道而行之。它的初始微调阶段,刻意避开了复杂的数学推理。这个阶段的目标只有一个:教会模型如何当一个合格的“工具人”。它只学习如何遵守指令、如何使用Python工具的接口(JSON格式)、如何规范地输出答案。
这就像教一个木匠,不是先让他看复杂的建筑图纸,而是先让他熟练掌握如何使用锤子、锯子和尺子。这种做法的好处是:
(1)避免了模型过早地固化某种冗长的、低效的推理模式。
(2)让模型初始的回答都非常简短,为后续在有限的“篇幅”内进行高效推理打下了基础。
3.2 第二步:多阶段强化学习“闯关”
在模型熟练掌握了“工具”之后,才正式进入强化学习的“实战”阶段。这个过程被设计成了三个难度递增的“关卡”:
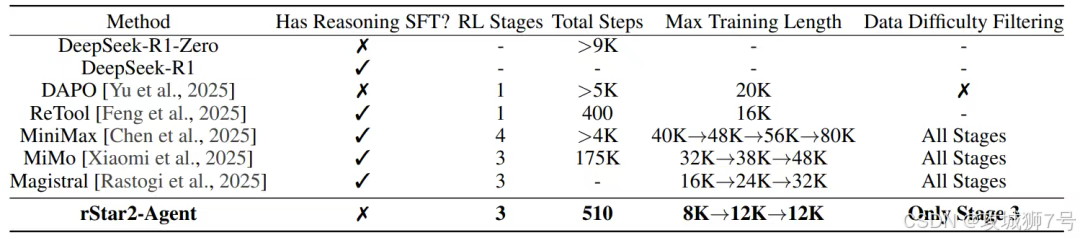
(1)第一关(简洁训练):将模型的最大回答长度限制在一个较短的范围(如8K token)。这会迫使模型去寻找最高效、最简洁的解题路径,而不是无限制地“长篇大论”。
(2)第二关(放宽限制):当模型在第一关的性能达到瓶颈后,适当放宽长度限制(如12K token),让它有更多的“思考空间”去解决更复杂的问题。
(3)第三关(难题攻坚):在最后阶段,主动筛选出那些模型仍然难以解决的“硬骨头”问题,进行集中训练,将模型的性能推向极限。
这套“先学工具,再分阶段攻坚”的训练流程,配合强大的RL基础设施(能够处理每秒4.5万次工具调用),使得整个训练过程异常高效。
四、结果:更短的推理,更高的准确率,更强的泛化
经过这番精心雕琢,14B的 `rStar2-Agent` 展现出了惊人的实力。
(1)数学能力登顶:在AIME等极具挑战性的数学竞赛基准上,它的准确率全面超越了体量是其近50倍的DeepSeek-R1以及o3-mini、Claude Opus 4.0等一众顶尖模型。
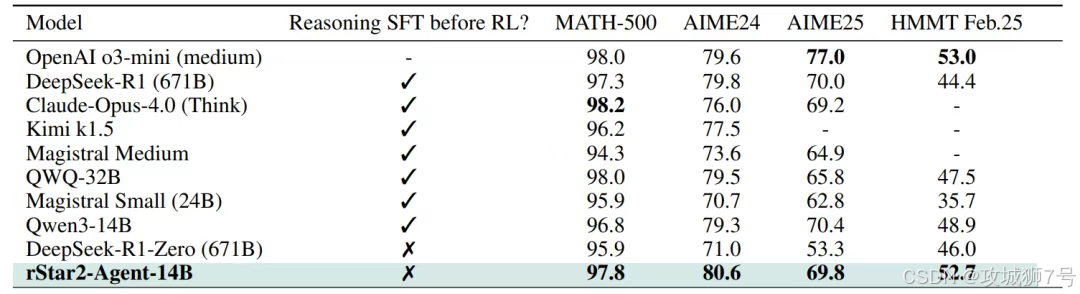
(2)推理效率更高:更难能可贵的是,它的胜利并非靠“堆字数”。在解决同样的问题时,它的平均回答长度比对手们短了数千个token。这无可辩驳地证明了,它真的学会了“更聪明地思考”。
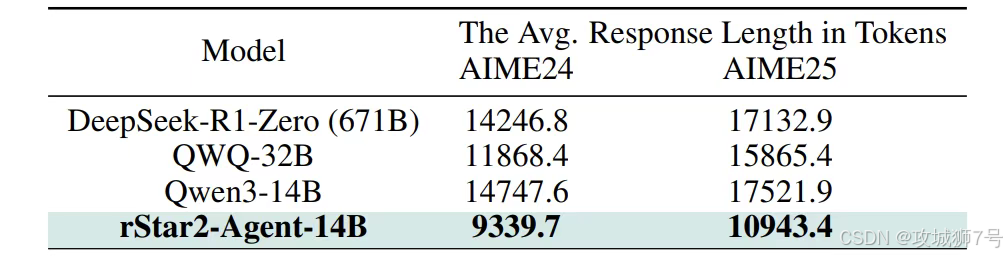
(3)惊人的泛化能力:这也许是这项研究最令人兴奋的发现。尽管 `rStar2-Agent` 的强化学习过程完全只用了数学数据,但它学到的能力却成功地迁移到了其他领域。在GPQA科学推理基准测试上,它的性能甚至超过了专门训练过的DeepSeek-V3。

这说明,模型学到的不是孤立的数学技巧,而是一种更底层的、通用的“利用工具进行探索、验证和纠错” 的问题解决方法论。它学会了如何像一个科学家或工程师那样思考。
结语:AI进化的新路径
`rStar2-Agent` 的成功,有力地挑战了AI领域“越大越好”的传统观念。它用无可辩驳的结果证明,通过精巧的算法设计、高效的训练策略和与环境的深度交互,一个中等规模的模型,完全可以在复杂的认知任务上,实现对“巨无霸”模型的超越。
这项工作为AI的未来发展,指明了一条充满希望的新路径。未来的突破,或许不再仅仅依赖于基础模型的无限膨胀,而更多地将来自于“模型能力”与“智能体训练技术”的深度结合。
它让我们看到,AI的智慧,不仅可以蕴藏于海量的参数之中,更可以绽放于与世界的一次次巧妙互动之间。当AI学会了拿起“锤子”去敲打和感受这个世界时,它离真正的智能,或许就又近了一大步。
论文地址:https://arxiv.org/pdf/2508.20722
代码地址:https://github.com/microsoft/rStar
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!
























 到【灌水乐园】发言
到【灌水乐园】发言









