




DMA
英文拼写是“Direct Memory Access”,汉语的意思就是直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式。 PIO模式下硬盘和内存之间的数据传输是由CPU来控制的;而在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器(接管系统总线)来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了CPU资源占有率。传送过程中不需要cpu参与,开始时要提供起始地址同数据长度!(老板不用做事交给秘书去搞的琐碎事,只要向老板报告声就ok啦)
PIO模式下硬盘和内存之间的数据传输是由CPU来控制的;而在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器(接管系统总线)来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了CPU资源占有率。传送过程中不需要cpu参与,开始时要提供起始地址同数据长度!(老板不用做事交给秘书去搞的琐碎事,只要向老板报告声就ok啦)
PIO
的英文拼写是“Programming Input/Output Model”,PIO模式是一种通过CPU执行I/O端口指令来进行数据的读写的数据交换模式。(杯子话筒一样)
Cache
与全部由硬件实现主存之间可采取多种地址映射方式,直接映射方式是其中的一种。在这种映射方式下,主存中的每一页只能复制到某一固定的Cache页中。由于Cache块(页)的大小为16B,而Cache容量为16KB。因此,此Cache可分为1024页。可以看到,Cache的页内地址只需4位即可表示;而Cache的页号需用10位二进制数来表示;在映射时,是将主存地址直接复制,现主存地址为1234E8F8(十六进制),则最低4位为Cache的页内地址,即1000,中间10位为Cache的页号,即1010001111。Cache的容量为16KB决定用这14位编码即可表示。题中所需求的Cache的地址为10100011111000。
Cache中的内容随命中率的降低需要经常替换新的内容。替换算法有多种,例如,先入后出(FILO)算法、随机替换(RAND)算法、先入先出(FIFO)算法、近期最少使用(LRU)算法等。这些替换算法各有优缺点,就以命中率而言,近期最少使用(LRU)算法的命中率最高。
cache是一个高速小容量的临时存储器,可以用高速的静态存储器芯片实现,或者集成到CPU芯片内部,存储CPU最经常访问的指令或者操作数据。
buffer与cache操作的对象就不一样。
buffer(缓冲)是为了提高内存和硬盘(或其他I/0设备)之间的数据交换的速度而设计的。缓冲(buffers)是根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
cache(缓存)是为了提高cpu和内存之间的数据交换速度而设计,
(就是老板跟秘书的沟通问题,老板有时为方便做事用的一个交流工具)
软件设计 包
括软件的结构设计,数据设计,接口设计和过程设计既独立又相互联系活动.
结构设计(体系设计)是指:定义软件系统各主要部件之间的关系
数据设计是指:将模型转换成数据结构的定义
接口设计是指:软件内部,软件和操作系统间以及软件和人之间如何通信
过程设计是指:系统结构部件转换成软件的过程描述
“瀑布模型”,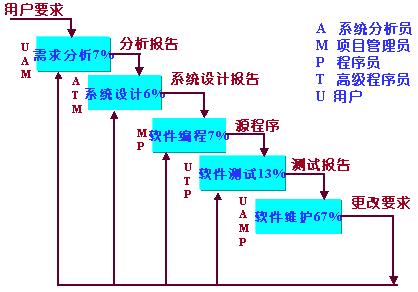
1970年温斯顿•罗伊斯(Winston Royce)提出了著名的“瀑布模型”,直到80年代早期,它一直是唯一被广泛采用的软件开发模型。
瀑布模型核心思想是按工序将问题化简,将功能的实现与设计分开,便于分工协作,即采用结构化的分析与设计方法将逻辑实现与物理实现分开。将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。从本质来讲,它是一个软件开发架构,开发过程是通过一系列阶段顺序展开的,从系统需求分析开始直到产品发布和维护,每个阶段都会产生循环反馈,因此,如果有信息未被覆盖或者发现了问题,那么最好 “返回”上一个阶段并进行适当的修改,开发进程从一个阶段“流动”到下一个阶段,这也是瀑布开发名称的由来。
螺旋模型(Spiral Model)
1988年,Barry Boehm正式发表了软件系统开发的"螺旋模型",它将瀑布模型和快速原型模型结合起来, 强调了其他模型所忽视的风险分析,特别适合于大型复杂的系统。螺旋模型沿着螺线进行若干次迭代,图中的四个象限代表了以下活动:
(1) 制定计划:确定软件目标,选定实施方案,弄清项目开发的限制条件;
(2)(每一圈) 风险分析:分析评估所选方案,考虑如何识别和消除风险;
(3) 实施工程:实施软件开发和验证;
(4) 客户评估:评价开发工作,提出修正建议,制定下一步计划。
. 增量模型(Incremental Model)
与建造大厦相同,软件也是一步一步建造起来的。在增量模型中,软件被作为一系列的增量构件来设计、实现、集成和测试,每一个构件是由多种相互作用的模块所形成的提供特定功能的代码片段构成.增量模型在各个阶段并不交付一个可运行的完整产品,而是交付满足客户需求的一个子集的可运行产品。整个产品被分解成若干个构件,开发人员逐个构件地交付产品,这样做的好处是软件开发可以较好地适应变化,客户可以不断地看到所开发的软件,从而降低开发风险。但是,增量模型也存在以下缺陷:
(1) 由于各个构件是逐渐并入已有的软件体系结构中的,所以加入构件必须不破坏已构造好的系统部分,这需要软件具备开放式的体系结构。
(2) 在开发过程中,需求的变化是不可避免的。增量模型的灵活性可以使其适应这种变化的能力大大优于瀑布模型和快速原型模型,但也很容易退化为边做边改模型,从而是软件过程的控制失去整体性。
快速原型模型(Rapid Prototype Model)
快速原型模型的第一步是建造一个快速原型,实现客户或未来的用户与系统的交互,用户或客户对原型进行评价,进一步细化待开发软件的需求。通过逐步调整原型使其满足客户的要求,开发人员可以确定客户的真正需求是什么;第二步则在第一步的基础上开发客户满意的软件产品。显然,快速原型方法可以克服瀑布模型的缺点,减少由于软件需求不明确带来的开发风险,具有显著的效果。
快速原型的关键在于尽可能快速地建造出软件原型,一旦确定了客户的真正需求,所建造的原型将被丢弃。因此,原型系统的内部结构并不重要,重要的是必须迅速建立原型,随之迅速修改原型,以反映客户的需求。
模型 优点 缺点 http://baike.baidu.com/view/8300.htm(参考)
瀑布模型 文档驱动 系统可能不满足客户的需求
快速原型模型 关注满足客户需求 可能导致系统设计差、效率低,难于维护
增量模型 开发早期反馈及时,易于维护 需要开放式体系结构,可能会设计差、效率低
螺旋模型 风险驱动 风险分析人员需要有经验且经过充分训练

















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









