




 本文介绍了一款名为PushDeer的消息推送服务,该服务可通过简单的HTTP请求将信息推送到用户的手机。支持iOS轻App及Android快应用,适用于多种监测场景。文章详细介绍了其工作原理及如何使用Python进行消息推送。
本文介绍了一款名为PushDeer的消息推送服务,该服务可通过简单的HTTP请求将信息推送到用户的手机。支持iOS轻App及Android快应用,适用于多种监测场景。文章详细介绍了其工作原理及如何使用Python进行消息推送。
前言
真的是一行代码实现了。先给看下代码。
https://api2.pushdeer.com/message/push?pushkey=你的key&text=推送内容
一、PushDeer是什么?
PushDeer 是一款由 Server酱 开发者 @Easy 牵头的众筹开源项目,实现了一个可「自行架设的无 APP 推送服务」,基于 iOS 轻 App(App Clips)、Android 快应用(暂未发布),只需要发送一个简单的 HTTP 请求,即可在手机上获得推送通知。
详细的还是得看官网。
什么情况下使用这个PushDeer?
比如你爬虫程序爬好了,可以把消息推送到你手机告诉你一下,比如你服务器崩溃了,也可以推送消息到你手机,应用场景广泛,只要有监测需求,就可以使用。
Server酱开发的另外一个项目是可以把消息推送到微信,但是个人觉得推送到微信还是不太方便,不如推送到手机。苹果安卓均可, 那下面就说一下怎么实现。
二、使用步骤,以安卓为例
1.下载Android测试版APP
app下载链接在官网有,或者私信我也可以。为什么还要下载APP?官网说Android 快应用还在开发中嘛,一个没有广告的APP安装在手机上没差别。
2.APP上操作
1.通过apple账号(或微信账号·仅Android版支持)登录
2.切换到「设备」标签页,点击右上角的加号,注册当前设备
3.切换到「密匙」标签页,点击右上角的加号,创建一个Key,把Key复制出来
3.python代码推送消息
python推送有2个方式,只要推送文字消息的话,就不需要用到SDK方式的了,就是大家在前言看到的这一行代码。
import requests
api="https://api2.pushdeer.com/message/push?pushkey=你的key&text=推送内容"
req = requests.post(api)
需要把api中的你的key替换成刚才设备上获取的key。推送内容可以根据实际情况写上时间、百分比、某个监测的参数等。
Python的SDK方式推送代码如下(示例):
from pypushdeer import PushDeer
pushdeer = PushDeer(pushkey="your_push_key")
pushdeer.send_text("hello world", desp="optional description")
pushdeer.send_markdown("# hello world", desp="**optional** description in markdown")
pushdeer.send_image("https://github.com/easychen/pushdeer/raw/main/doc/image/clipcode.png")
pushdeer.send_image("data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAQAAAC1HAwCAAAAC0lEQVQYV2NgYAAAAAMAAWgmWQ0AAAAASUVORK5CYII=")
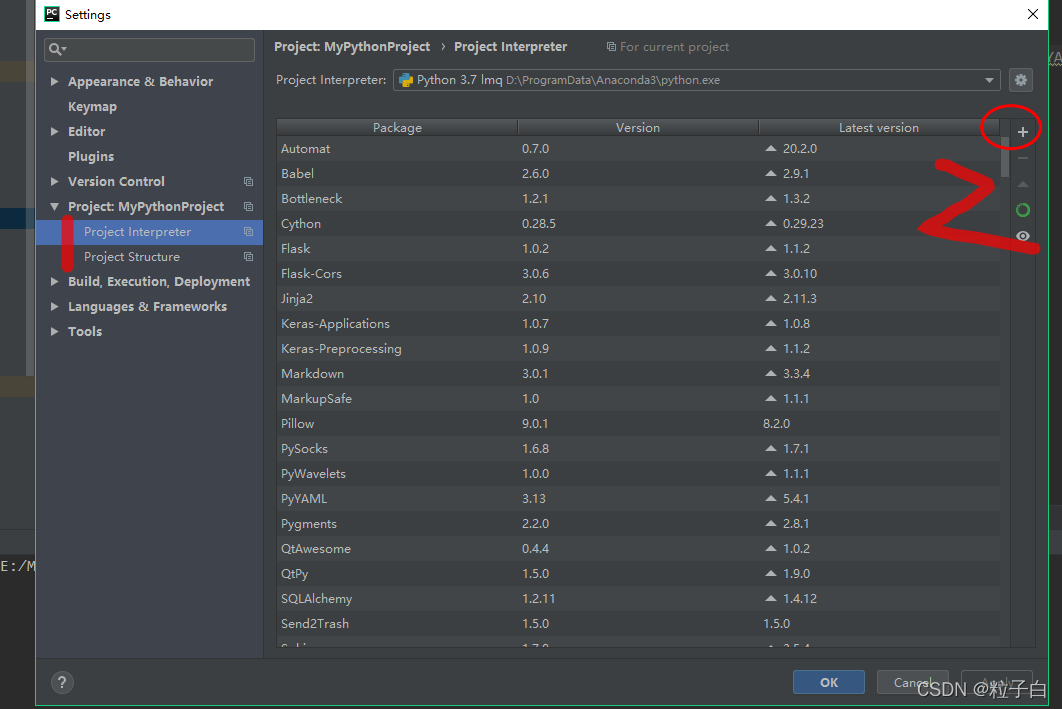
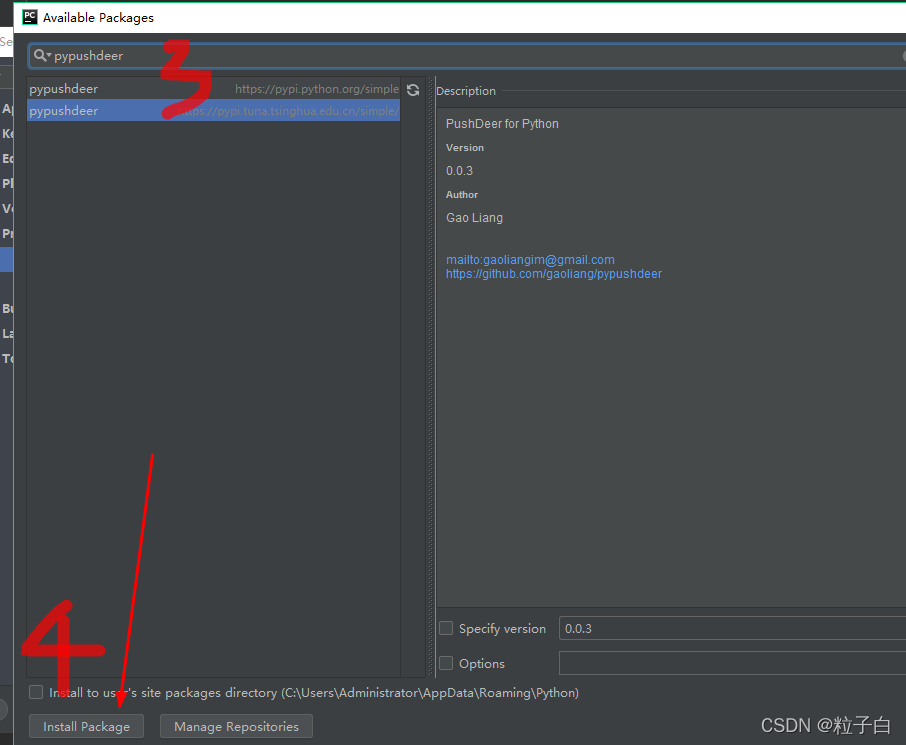
得先安装一下pypushdeer 这个包。pip install pypushdeer或者在pycharm,点设置,然后按照图片顺序安装。
以下是用SDK方式测试发送文字的。建议手机开启通知栏通知,比较方便。
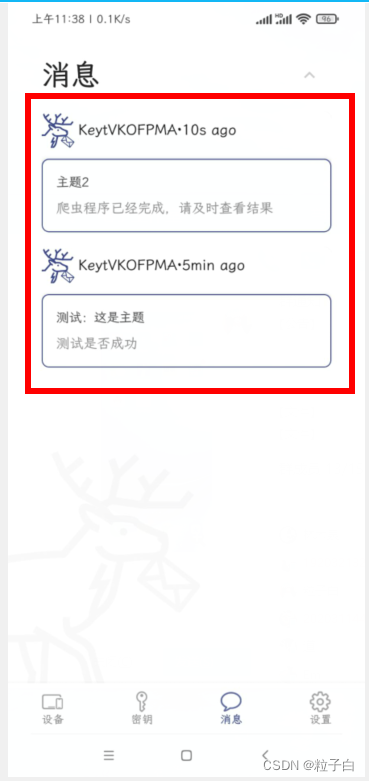
经测试发送图片的好像不行,应该是官方限制流量。
目前这个方法是使用官方服务器的,作者提供了自建服务器的使用方法,可以docker部署。
总结
多看看官网资料,这个用处还是很大的。



















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











