







 本文介绍如何使用卷积神经网络(CNN)训练模型识别复杂图片验证码,包括预处理、模型训练及预测流程。
本文介绍如何使用卷积神经网络(CNN)训练模型识别复杂图片验证码,包括预处理、模型训练及预测流程。
最近新冠肺炎肆虐,已在家办公三周左右,闲来无聊,来写一篇最近用到的卷积神经网络训练模型来识别图片验证码的blog。
最近在做一个网络爬虫的项目,爬取官方网站上的信息,需要输入查询内容及图片验证码上边的1-9及A-Z(除去O和I)字符进行验证,验证通过方可获取到返回的数据内容。
起初用到了python推荐的tesserocr lib,但识别效率不是很高,因为我需要识别的验证码是倾斜的,并且带有干扰线
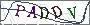
这种就不太好验证了,一般tesserocr可以验证无干扰线、不黏连且无倾斜角度的字符验证码图片
故考虑到了CNN,通过训练样本训练模型来识别个性化的图片验证码,这里工作量最大的就是前期的训练集的获取了
1、首先用爬虫的方式爬取网站上的原始图片验证码,大概获取了七八千张,注意,其中有许多是无法预处理的,所以原始图片越多越好。
2、将原始图片转换成二值图片,0-黑,255-白
处理逻辑即将那些干扰线处理成黑色,否则为白色(将值set为1),下一步会将这些孤立点作为噪声去掉(干扰线周围均为白色(1))
gray = img.convert('L')
gray = gray.point(lambda x: 0 if x < 100 else 255, '1')
3、用9领域方法将孤立黑点去掉,去除原理是判断当前黑色点(0)周围的白色值(1)是否多于阈值,若是则认为是孤立点将其去除。
# 降噪
noise_point_list = collect_noise_point(gray)
remove_noise_pixel(gray, noise_point_list)
sum_9_region_new(img,x,y) 函数是用9领域方法判断该点周围是否为1(白点),若超过阈值(0 < res_9 < 3)并且该点为黑点,则remove_noise_pixel去除
def collect_noise_point(img):
'''收集所有的噪点'''
noise_point_list = []
for x in range(img.width):
for y in range(img.height):
res_9 = sum_9_region_new(img, x, y)
if (0 < res_9 < 3) and img.getpixel((x, y)) == 0: # 找到孤立点
pos = (x, y)
noise_point_list.append(pos)
return noise_point_list
def sum_9_region_new(img, x, y):
'''确定噪点 '''
cur_pixel = img.getpixel((x, y)) # 当前像素点的值
width = img.width
height = img.height
if cur_pixel == 1: # 如果当前点为白色区域,则不统计邻域值
return 0
# 因当前图片的四周都有黑点,所以周围的黑点可以去除
if y < 2: # 本例中,前两行的黑点 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











