




 本文介绍了如何开启和调整TiKV与PD的RegionMerge配置,以及检查和处理空Region的方法。针对大量空Region存在的问题,分析了可能原因,并提出了关闭splittable特性的解决方案,涉及参数如`split-region-on-table`和`enable-cross-table-merge`的调整。此外,还提及了`enable-one-way-merge`参数对Region合并的影响。
本文介绍了如何开启和调整TiKV与PD的RegionMerge配置,以及检查和处理空Region的方法。针对大量空Region存在的问题,分析了可能原因,并提出了关闭splittable特性的解决方案,涉及参数如`split-region-on-table`和`enable-cross-table-merge`的调整。此外,还提及了`enable-one-way-merge`参数对Region合并的影响。
一、开启region merge
# 控制 Region Merge 的 size 上限,当 Region Size 大于指定值时 PD 不会将其与相邻的 Region 合并
pd-ctl config set max-merge-region-size 20
# 控制 Region Merge 的 key 上限,当 Region key 大于指定值时 PD 不会将其与相邻的 Region 合并
pd-ctl config set max-merge-region-keys 200000
# 同时进行的 Region Merge 调度的任务,设置为 0 则关闭 Region Merge。
pd-ctl config set merge-schedule-limit 8
二、查看空region的方法
pd里记录的所有空region
# pd监控中记录的region数量
tiup ctl:v4.0.13 pd -u http://pd_ip:pd_port region check empty-region > empty-region.json
# wc -l empty-region.json
# 通过对全量数据做对比
tiup ctl:v4.0.13 pd -u http://pd_ip:pd_port region scan> region_all.json
# 通过条件对比,可以发现官方对"approximate_size": 1的情况即定义为空region,approximate_size表示region的近似数据量
# 但是pd中的记录其实是存在一定的偏差,真实的空region要通过下面的sql查看
SELECT count(1) FROM INFORMATION_SCHEMA.TIKV_REGION_STATUS where APPROXIMATE_SIZE=1;
三、开启了region merge后还有大量空region的原因
创建过大量表后(包括执行 Truncate Table 操作)又清空了。此时如果开启了 split table 特性,这些空 Region 是无法合并的,此时需要调整以下参数关闭这个特性:
TiKV: 将 split-region-on-table 设为 false,该参数不支持动态修改。
方式一、
# PD:
config set key-type raw
# config set key-type txn
# 如果集群中不存在 TiDB 实例,key-type 的值为 "raw" 或 "txn"。此时,无论 enable-cross-table-merge 设置为何,PD 均可以跨表合并 Region。
#如果集群中存在 TiDB 实例,key-type 的值应当为 "table"。此时,enable-cross-table-merge 的设置决定了 PD 是否能跨表合并 Region。如果 key-type 的值为 "raw",placement rules 不生效。
方式二、
# enable-cross-table-merge 用于开启跨表 Region 的合并。当设置为 false 时,PD 不会合并不同表的 Region。该选项只在键类型为 "table" 时生效。
config set enable-cross-table-merge true
小记:
# enable-one-way-merge 用于控制是否只允许和相邻的后一个 Region 进行合并。当设置为 false 时,PD 允许与相邻的前后 Region 进行合并。设置为true只允许和相邻的后一个 Region 合并
config set enable-one-way-merge true
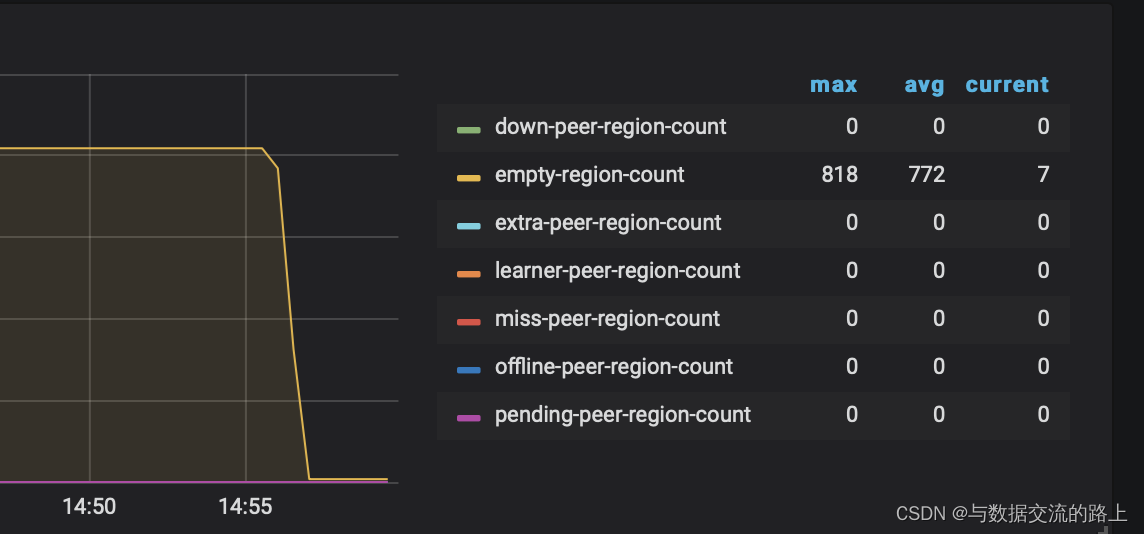
这是开启了跨表合并后的空region现象,还有一些点不明白的之后再补充

















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









