






 本文讲述了作者为满足女友需求,编写爬虫抓取动态加载搞笑动图的过程。首先分析网页结构,通过正则表达式获取文章链接,接着处理动态加载问题,抓取所有文章并保存。然后使用生产者消费者模型,通过Go语言并发下载图片,最终成功下载大量动图。
本文讲述了作者为满足女友需求,编写爬虫抓取动态加载搞笑动图的过程。首先分析网页结构,通过正则表达式获取文章链接,接着处理动态加载问题,抓取所有文章并保存。然后使用生产者消费者模型,通过Go语言并发下载图片,最终成功下载大量动图。
背景
上次给女朋友爬完了“发表情”的热门表情后,兴高采烈的给她看。结果她一脸不高兴:不是让你看xxxx的视频了么!这不是我要的图。我要那种长视频那种的图片。……那种搞笑的图片。

经过一番研究,终于搞明白了需求。原来要的是那种整天在水文章的各大平台小编最喜欢发的那种搞笑动图,还会配上一段文字就水了一篇文章的那种。。。

就像上面这种。。。
(层次能不能高点。。。
好吧,女朋友永远没有错。再折腾折腾吧。
目标网站
凭借直觉(某度 搞笑图片),我找到了目标。
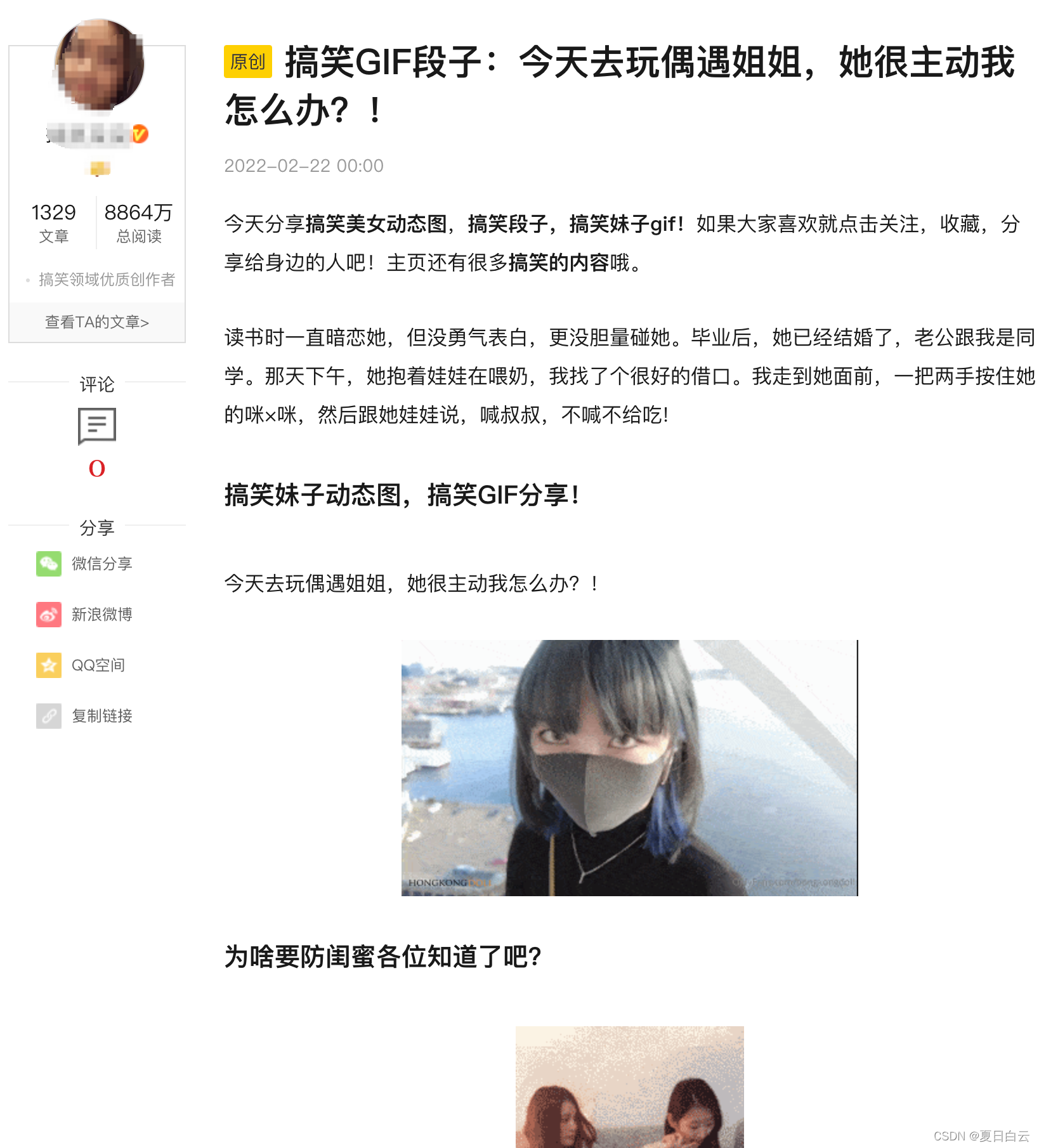
嗯。这不就是女票想要的那种gif么。
代码
分析网页及正则表达式
F12看看什么情况。
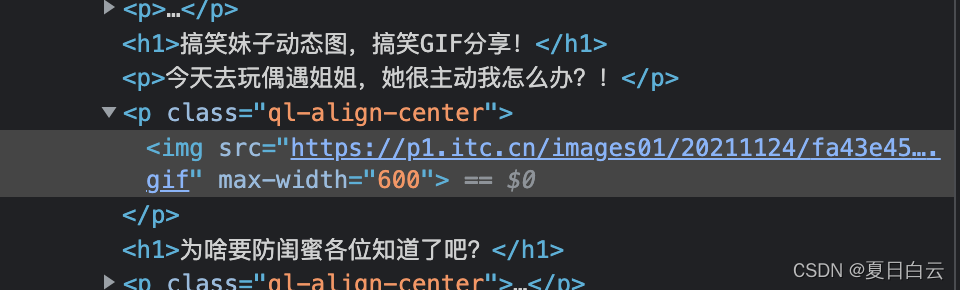
好像文章中的img都是有max-width="600"作为后缀的。那就明白怎么写正则了
<img src="([^"]*)" max-width="600">
对吧,蛮简单的。而且验证一下发现直接拉html就可以了,没有高级操作。舒适。
但是一个网页才一些gif,太少了。来到作者主页看看。
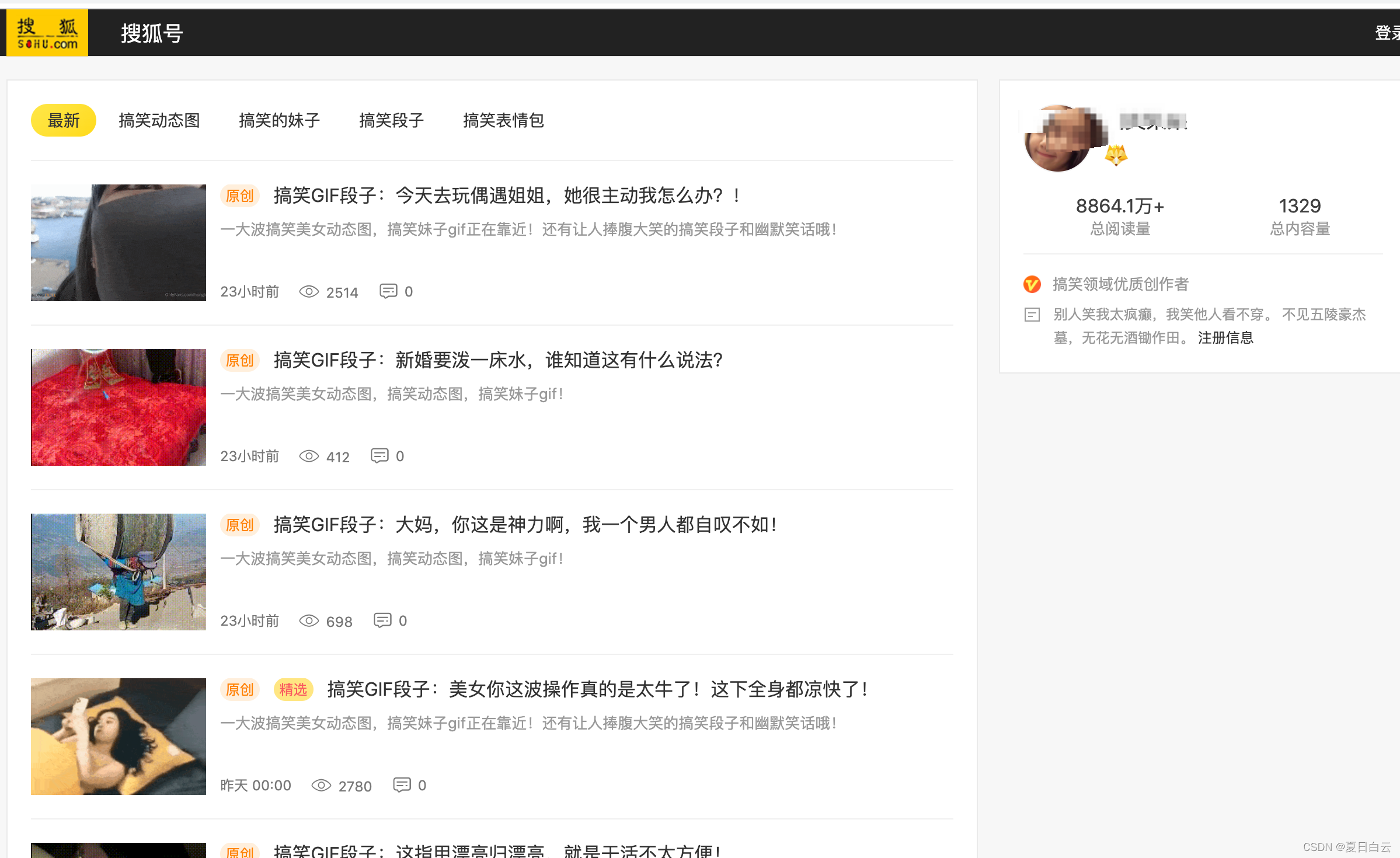
哦吼,这么多。F12看看。
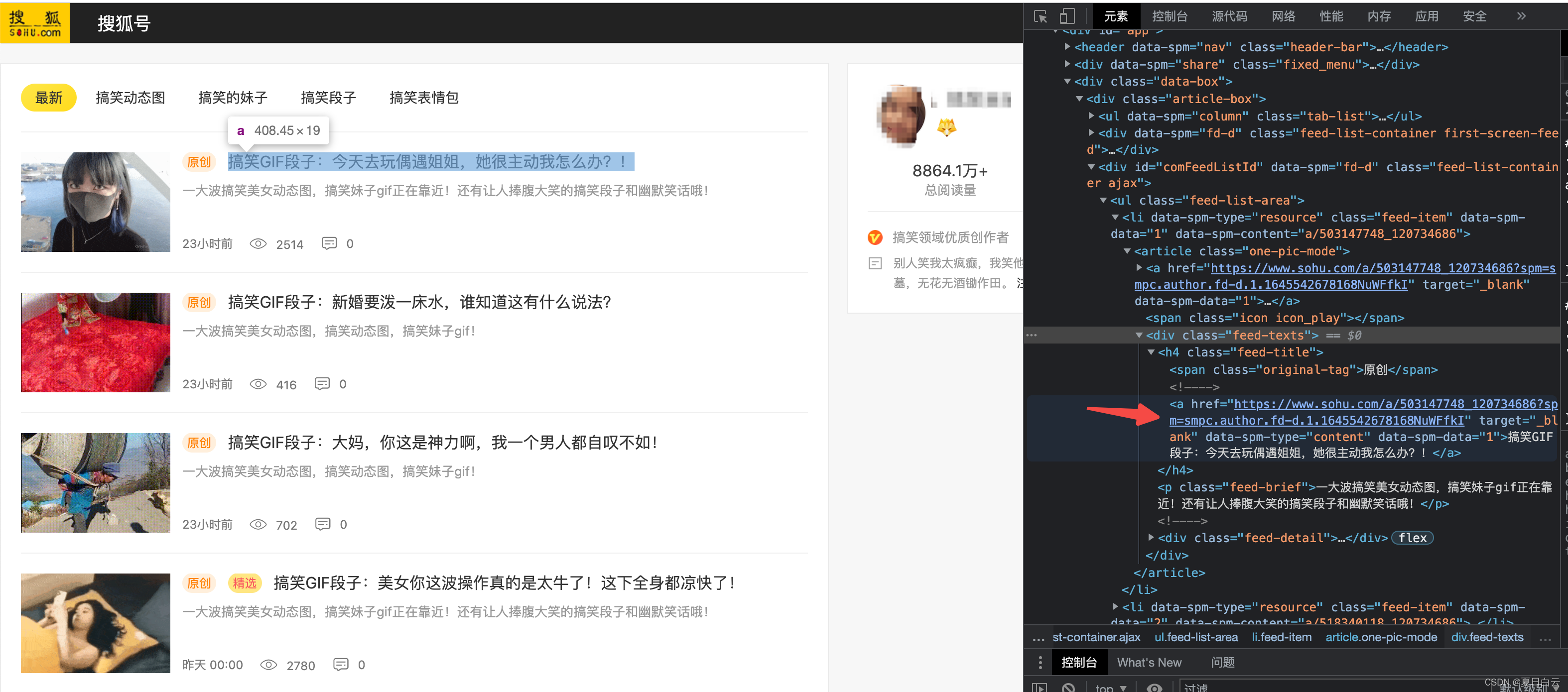
还行,大概就是这么个正则:
<a href="([^"]*)" target="_blank" data-spm-type="content"
我们这里使用target="_blank" data-spm-type="content"来定位列表中的链接,应为到处都是〈a〉,必须要区分出来需要的链接。
但是现在又有个问题了,发现这页面居然是动态加载的,而不是分页的!随着页面的下拉,出现越来越多文章。。
这可就坑了。看看包。
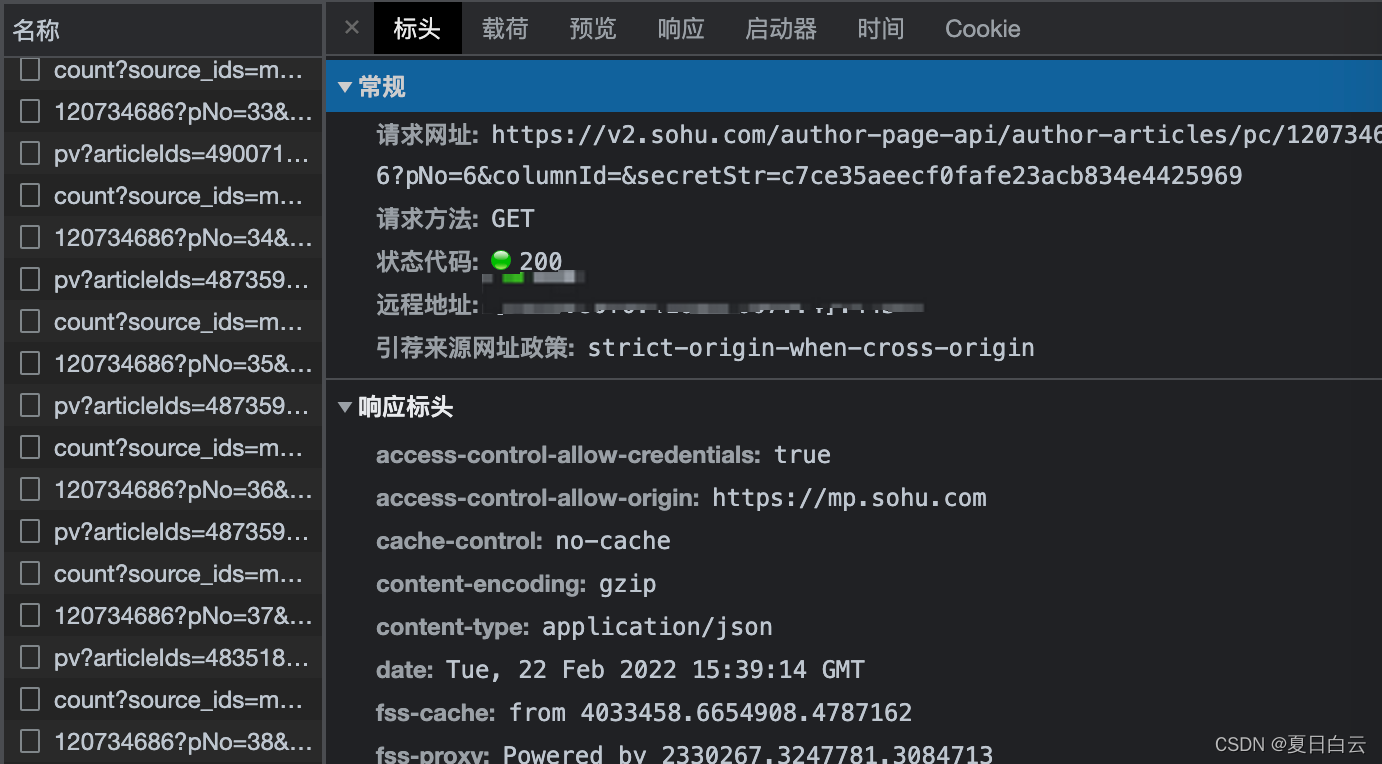
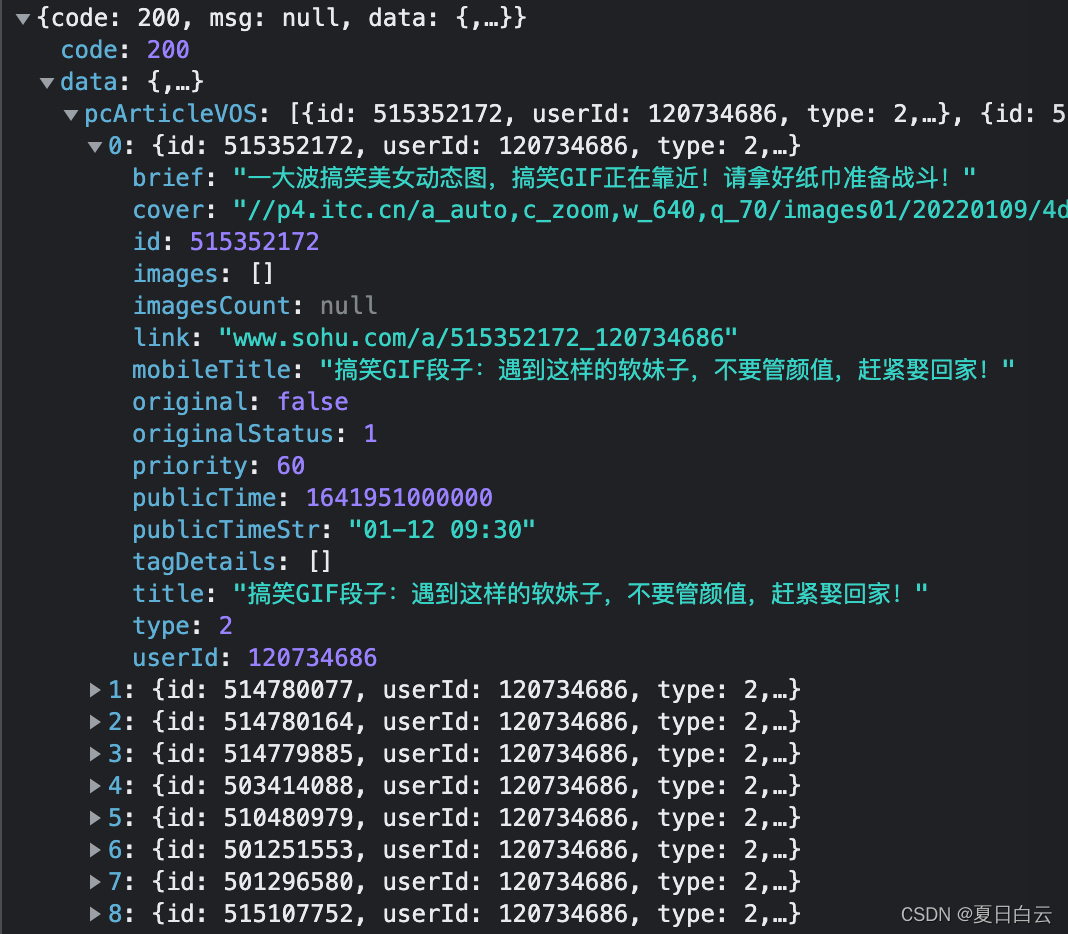
嗯。是这个请求返回的数据。但是这secretStr咋整呀。。。 js功底还是不太行,不好搞。
忽然灵光一闪。我把所有历史文章直接全加载出来不就得了!
疯狂下拉。终于见底。
大功告成。直接保存整个页面到工程下。就叫source.html吧。叫啥不重要。
读取文章url列表
然后我们只需要读取文件,正则匹配:
var urlRegex = regexp.MustCompile(`<a href="([^"]*)" target="_blank" data-spm-type="content"`)
func GetUrlList() ([]string, error) {
f, err := os.OpenFile("source.html", os.O_RDONLY, 0644)
if err != nil {
return nil, err
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, err
}
matchs := urlRegex.FindAllStringSubmatch(string(buf), -1)
rst := make([]string, len(matchs))
for i, match := range matchs {
rst[i] = match[1]
}
return rst, nil
}
就把所有文章的url搞出来了。
并发下载的框架
仍然是那个生产者消费者模型,用channel通信,开5个goroutine并发下载。
Task的定义如下:
package model
type Task struct {
URL string
FileName string
}
整个爬虫的代码框架:
package main
import (
"……/crapper/sohu_xxxxx"
"……/crapper/model"
"fmt"
"io"
"net/http"
"os"
"sync"
)
func main() {
taskCh := make(chan *model.Task, 1000)
wg := sync.WaitGroup{}
for i := 0; i < 5; i++ {
wg.Add(1)
go func(tasks <-chan *model.Task, wg *sync.WaitGroup) {
defer wg.Done()
for t := range tasks {
err := downloadFile(t.URL, t.FileName)
if err != nil {
fmt.Printf("fail to download %q to %q, err: %v", t.URL, t.FileName, err)
}
}
}(taskCh, &wg)
}
sohu_xxxxx.Crap(taskCh) // 生产者代码
close(taskCh)
wg.Wait()
}
func downloadFile(URL, fileName string) error {
//Get the resp bytes from the url
resp, err := http.Get(URL)
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return fmt.Errorf("status code %v", resp.StatusCode)
}
//Create a empty file
file, err := os.Create(fileName)
if err != nil {
return err
}
defer file.Close()
//Write the bytes to the fiel
_, err = io.Copy(file, resp.Body)
if err != nil {
return err
}
return nil
}
生产者通过把任务往taskCh里头仍,生产完毕后关掉channel,即可完成整个生产过程。
生产者代码
生产方只需要遍历读取所有的文章网址,从中取出图片链接,然后仍进channel即可。
整个生产代码如下:
package sohu_gaoxiaodaidai
import (
"……/crapper/model"
"fmt"
"io/ioutil"
"net/http"
"os"
"path"
"regexp"
)
var (
urlRegex = regexp.MustCompile(`<a href="([^"]*)" target="_blank" data-spm-type="content"`)
imgRegex = regexp.MustCompile(`<img src="([^"]*)" max-width="600">`)
)
func GetUrlList() ([]string, error) {
f, err := os.OpenFile("source.html", os.O_RDONLY, 0644)
if err != nil {
return nil, err
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, err
}
matchs := urlRegex.FindAllStringSubmatch(string(buf), -1)
rst := make([]string, len(matchs))
for i, match := range matchs {
rst[i] = match[1]
}
return rst, nil
}
func Crap(taskCh chan *model.Task) {
urls, err := GetUrlList()
if err != nil {
fmt.Printf("err: %v\n", err)
return
}
for _, url := range urls {
if err := produceForPage(url, taskCh); err != nil {
fmt.Sprintf("produce for %q fail ,err: %v", url, err)
}
}
}
func produceForPage(url string, taskCh chan *model.Task) error {
resp, err := http.Get(url)
if err != nil {
return fmt.Errorf("fail to get page: %v", err)
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return fmt.Errorf("status code: %v", resp.StatusCode)
}
buf, err := ioutil.ReadAll(resp.Body)
if err != nil {
return fmt.Errorf("read body err: %v", err)
}
content := string(buf)
matches := imgRegex.FindAllStringSubmatch(content, -1)
for _, match := range matches {
url := match[1]
fileName := path.Base(url)
taskCh <- &model.Task{
URL: url,
FileName: "images/"+ fileName),
}
}
return nil
}
运行
然后我们就在主目录下
go run main.go
一会就噼里啪啦下完。比上次那个慢,毕竟网页多,gif图大。
成果


我们的表情包很顺利的升级成了一堆gif长动图😁(估计那个账号也是个马甲号。从别的地方爬来文章各种发)


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









