






 本文介绍了使用Go语言编写一个简单的网络爬虫,目标是爬取一个热门表情网站上的GIF动图。通过分析网页结构,利用正则表达式抓取图片URL和标题,采用生产者消费者模型,利用channel进行并发下载。代码简洁明了,展示了Go语言在爬虫开发中的高效特性。
本文介绍了使用Go语言编写一个简单的网络爬虫,目标是爬取一个热门表情网站上的GIF动图。通过分析网页结构,利用正则表达式抓取图片URL和标题,采用生产者消费者模型,利用channel进行并发下载。代码简洁明了,展示了Go语言在爬虫开发中的高效特性。
背景
女朋友前两天抱怨说某某大V做视频一条视频好多热门表情。说那大V说过他是团队里有人爬虫直接爬的。问我什么时候给她爬一爬??叨叨了好多天,终于行动了。
目标网站分析
首先找了个热门表情的网站。
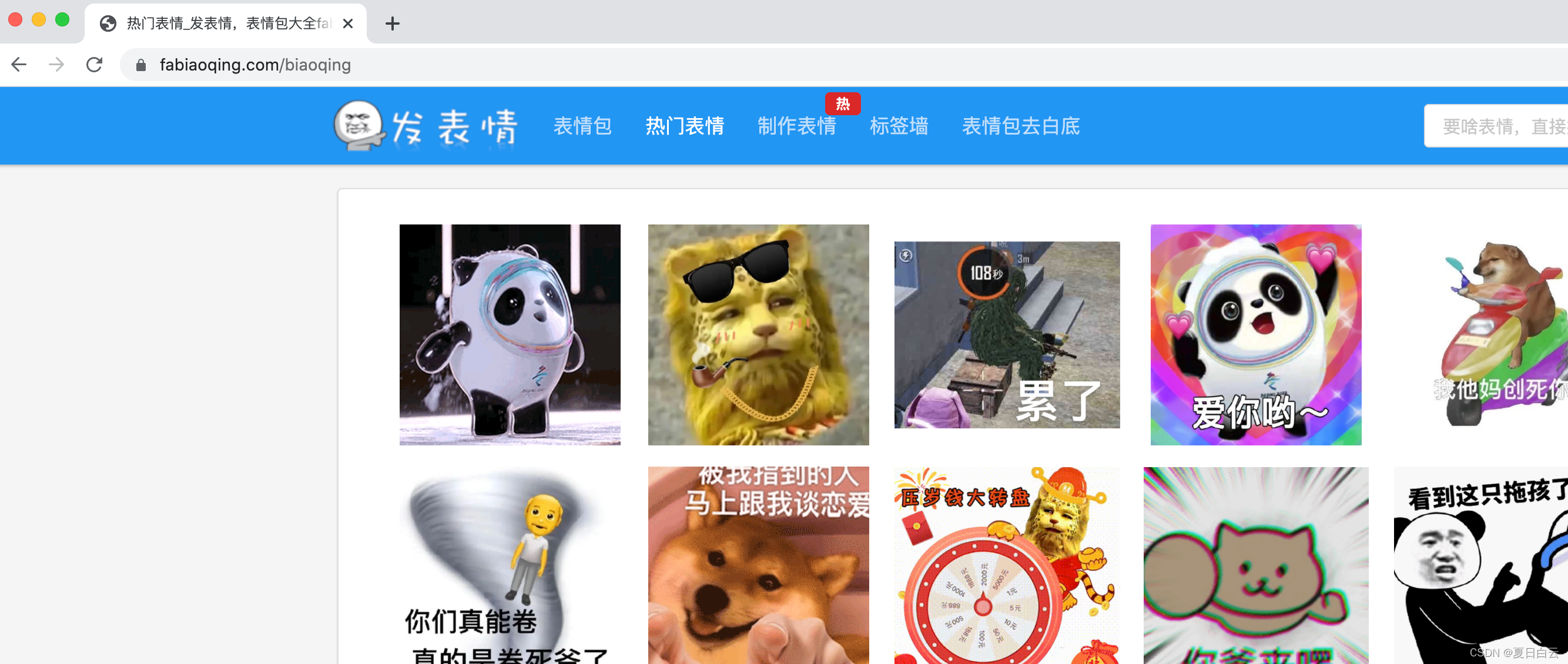
就这个发表情吧。正好里头有热门表情这个分类。它是分页的。我们来看看咋分页的。切到第2页。
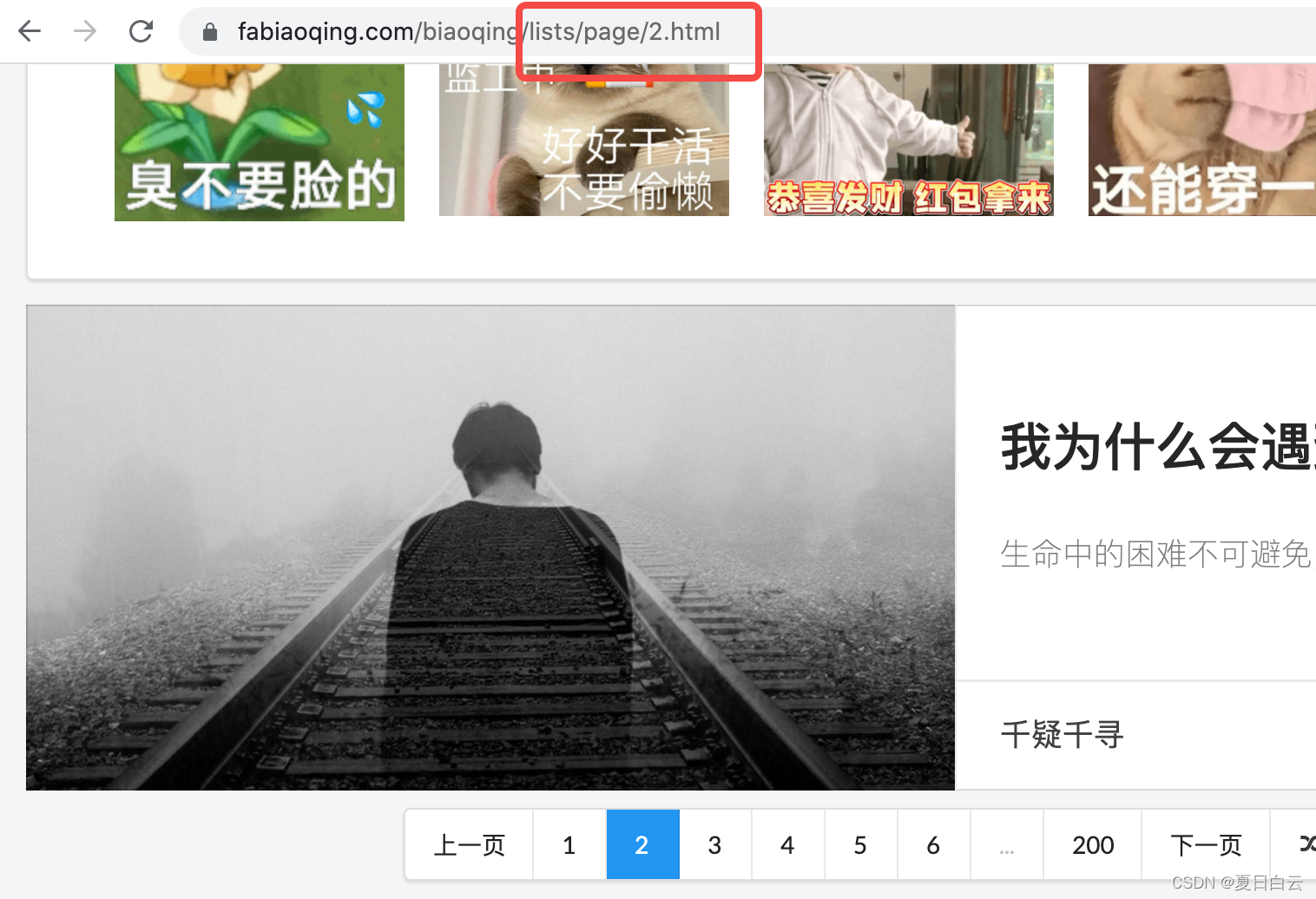
凭借多年程序员的直觉,明摆着每一页,包括第一页,都可以以
https://www.fabiaoqing.com/biaoqing/lists/page/${页数}.html
的形式访问到。尝试了一下,确实是这样的,并且直觉上每一页的html形式肯定也是一样的。
F12观察一下。
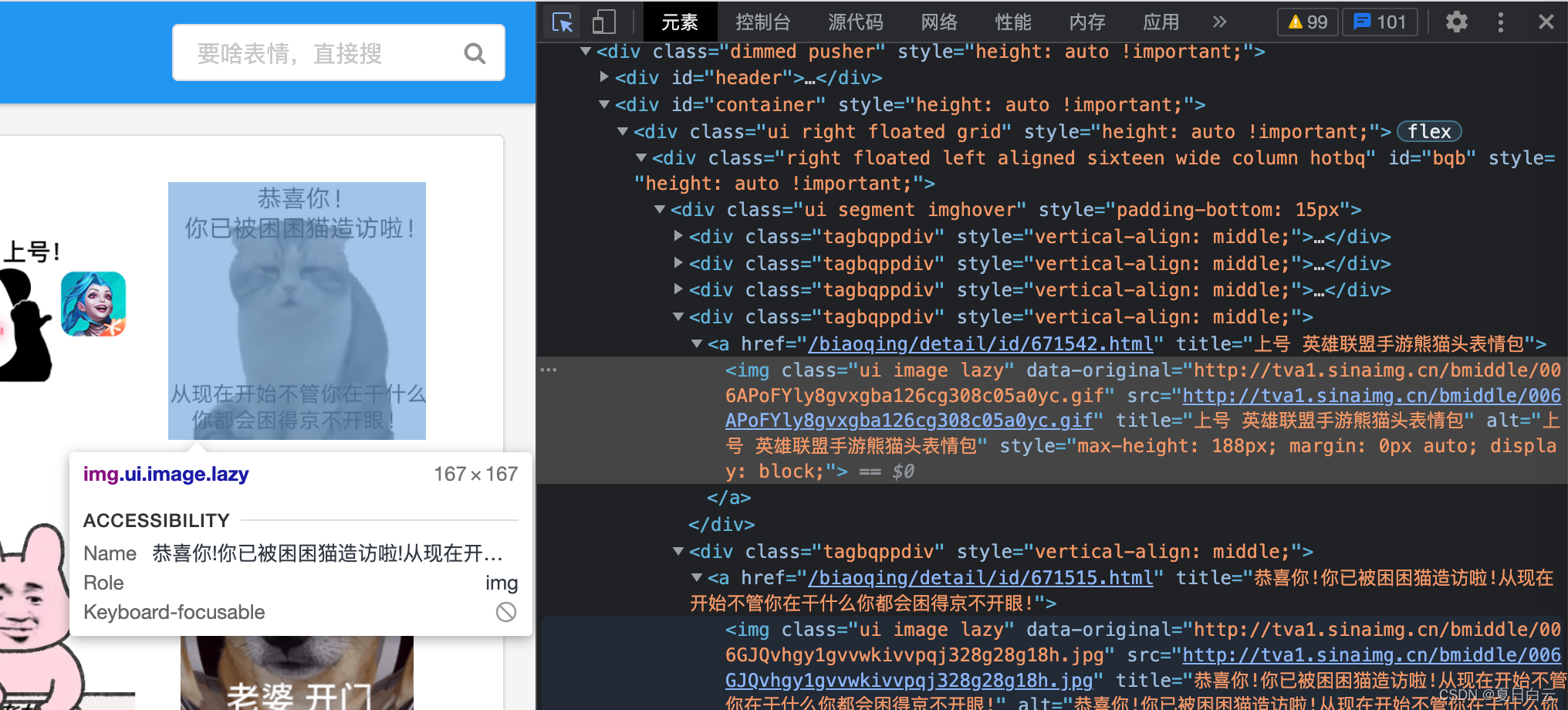
每个图片的形式是确定的,都有这个class=“xxxx” xxxx, src
那我只要从src中取出图片的下载链接然后去下载就行了。看上面还有title和alt,正好可以拿来做文件名打标签,方便搜索用。
我们来拉一下网页看看先。
func main() {
resp, _ := http.Get("https://www.fabiaoqing.com/biaoqing/lists/page/2.html")
buf, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("%s\n", buf)
}
$ go run main.go
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
……
<a href="/biaoqing/detail/id/671775.html" title="雀跃的小腿跳起来 GIF 动图">
<img class="ui image lazy" data-original="http://tva1.sinaimg.cn/bmiddle/006APoFYly8gw2hau44pdg306o06o74u.gif" src="/Public/lazyload/img/transparent.gif" title="雀跃的小腿跳起来 GIF 动图" alt="雀跃的小腿跳起来 GIF 动图" style="max-height:188;margin: 0 auto"/> </a>
……
诶,好像有点不太一样。拉html的格式是:
<img class="ui image lazy" data-original="http://tva1.sinaimg.cn/bmiddle/006APoFYly8gw2hau44pdg306o06o74u.gif" src="/Public/lazyload/img/transparent.gif" title="雀跃的小腿跳起来 GIF 动图" alt="雀跃的小腿跳起来 GIF 动图" style="max-height:188;margin: 0 auto"/>
也就是说,大概启动后js动态的把data-original里头的值填进了src里头替代掉了默认底图。那好吧。反正直接取data-original的就得了。
代码
并发下载的框架
我们整个生产者消费者模型,用channel通信,开5个goroutine并发下载。
Task的定义如下:
package model
type Task struct {
URL string
FileName string
}
整个爬虫的代码框架就差不多就是这样的了。
package main
import (
"……/crapper/fabiaoqing"
"……/crapper/model"
"fmt"
"io"
"net/http"
"os"
"sync"
)
func main() {
taskCh := make(chan *model.Task, 1000)
wg := sync.WaitGroup{}
for i := 0; i < 5; i++ {
wg.Add(1)
go func(tasks <-chan *model.Task, wg *sync.WaitGroup) {
defer wg.Done()
for t := range tasks {
err := downloadFile(t.URL, t.FileName)
if err != nil {
fmt.Printf("fail to download %q to %q, err: %v", t.URL, t.FileName, err)
}
}
}(taskCh, &wg)
}
fabiaoqing.Crap(taskCh) // 生产者代码
close(taskCh)
wg.Wait()
}
func downloadFile(URL, fileName string) error {
//Get the resp bytes from the url
resp, err := http.Get(URL)
if err != nil {
return err
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return fmt.Errorf("status code %v", resp.StatusCode)
}
//Create a empty file
file, err := os.Create(fileName)
if err != nil {
return err
}
defer file.Close()
//Write the bytes to the fiel
_, err = io.Copy(file, resp.Body)
if err != nil {
return err
}
return nil
}
其实唯一的差别就是生产者那一行代码。生产者通过把任务往taskCh里头仍,生产完毕后关掉channel,即可完成整个生产过程。
生产者代码
生产者部分的代码是爬取网页的核心。我们来看看怎么设计。
首先最外层应该有一层循环遍历所有200个页面。
func Crap(taskCh chan *model.Task) {
for i := 1; i <= 200; i++ {
url := fmt.Sprintf("https://www.fabiaoqing.com/biaoqing/lists/page/%d.html", i)
err := produceForPage(url, taskCh)
if err != nil {
fmt.Sprintf("produce for %q fail, err: %v", url, err)
continue
}
}
}
然后有了url后,最关键的就是http.Get到网页html文件后,怎么从中提取出所有所需图片的url。这里不需要用html文档的分析,直接用正则表达式就可以搞定了。正则表达式写出来如下:
<img class="ui image lazy" data-original="([^"]*)".*?title="([^"]*)"
这样,就可以直接匹配出图片地址和title。title用作拼接文件名用。
于是,整个生产者代码如下:
package fabiaoqing
import (
"……/crapper/model"
"fmt"
"io/ioutil"
"net/http"
"path"
"regexp"
"strings"
)
var regex = regexp.MustCompile(`<img class="ui image lazy" data-original="([^"]*)".*?title="([^"]*)"`)
func produceForPage(url string, taskCh chan *model.Task) error {
resp, err := http.Get(url)
if err != nil {
return fmt.Errorf("fail to get page: %v", err)
}
defer resp.Body.Close()
if resp.StatusCode != 200 {
return fmt.Errorf("status code: %v", resp.StatusCode)
}
buf, err := ioutil.ReadAll(resp.Body)
if err != nil {
return fmt.Errorf("read body err: %v", err)
}
content := string(buf)
matches := regex.FindAllStringSubmatch(content, -1)
for _, match := range matches {
url := match[1]
title := match[2]
fileNameOfUrl := path.Base(url)
idx := strings.LastIndex(fileNameOfUrl, ".")
if idx < 0 {
fmt.Printf("can't resolve url filename %q", url)
continue
}
firstPart := fileNameOfUrl[:idx]
extPart := fileNameOfUrl[idx:]
fileName := fmt.Sprintf("%s%s%s", title, firstPart, extPart)
taskCh <- &model.Task{
URL: url,
FileName: "images/"+fileName, // 加上保存文件的路径前缀
}
}
return nil
}
func Crap(taskCh chan *model.Task) {
for i := 1; i <= 200; i++ {
url := fmt.Sprintf("https://www.fabiaoqing.com/biaoqing/lists/page/%d.html", i)
err := produceForPage(url, taskCh)
if err != nil {
fmt.Sprintf("produce for %q fail, err: %v", url, err)
continue
}
}
}
运行
然后我们就在主目录下
go run main.go
一会就噼里啪啦下完。就一些title不符合文件名命名,以及太长了超过文件名限制的一些报错。
摁。没有被限流。如果可能被限流的话还是给消费者那里加个限速好了。
成果
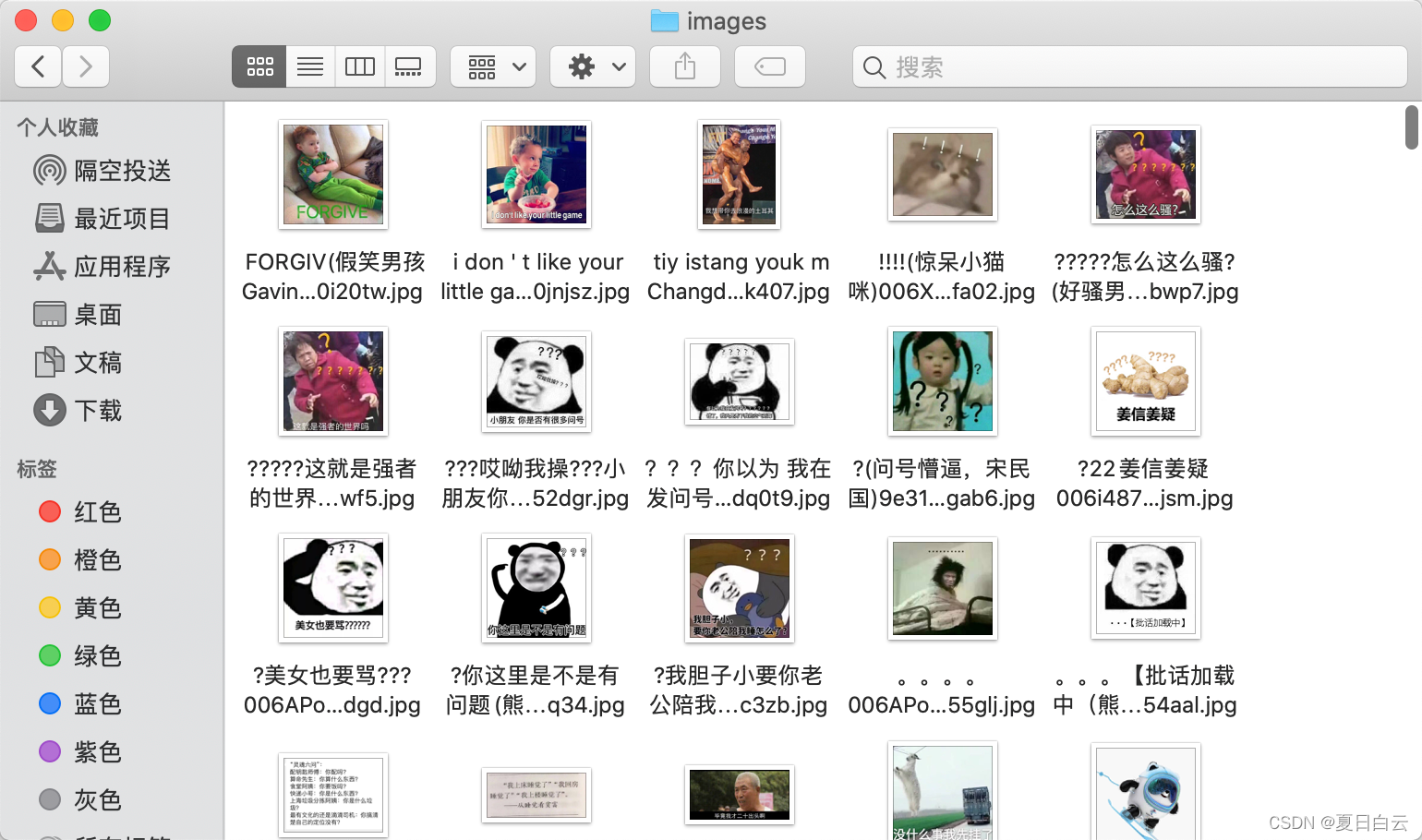





结语
写爬虫还是蛮简单的吧。对于这种简单网站。
大家玩的愉快。

















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









