



学习地址:
学习小册
RAG 基于私域数据进行回答。
结合前面的知识,已经掌握了构建一个基于私域数据回答问题的RAG bot的所有碎片;
- 基于prompt Templae 构建可复用的prompt模版
- 如何根据私域数据的类型来对数据进行分块(spliter)
- 构建私域数据的vecotr db
- 根据相似性查询vector db相关的上下文。
使用《骆驼祥子》来作为私域数据创建一个bot;
- 1 首先切割文档,转为向量存储在本地
使用TextLoader读取数据,使用RecursiveCharacterTextSplitter切割文档,然后embedding化存在本地vetcor db
// 切割文档,存为向量
async initVector() {
const dir = readdirSync("../db/luotuo");
if (dir.length) {
return;
}
const loader = new TextLoader("../data/1.txt");
const docs = await loader.load();
// 创建实例,设置分割文本的大小和重叠大小
const spliter = new RecursiveCharacterTextSplitter({
chunkOverlap: 100,
chunkSize: 500,
});
const splitDocs = await spliter.splitDocuments(docs);
// 使用FaissStore替换MemoryVectorStore 创建一个 FaissStore 实例
const vectorStore = await FaissStore.fromDocuments(
splitDocs,
this.embeddings
);
// 保存向量存储
await vectorStore.save(directory);
}
- 2 定义prompt
设计prompt有技巧,
比如 并且回答时仅根据原文,固定LLM的回答只能根据原文内容。
如果原文中没有相关内容,你可以回答“原文中没有相关内容”, 减少LLm的幻想问题。
generatorTemplate() {
// 设计prompt的时候,有技巧,比如 并且回答时仅根据原文,固定LLM的回答只能根据原文内容。
// 如果原文中没有相关内容,你可以回答“原文中没有相关内容”, 减少LLm的幻想问题。
const TEMPLATE = `
你是一个熟读老舍的《骆驼祥子》的终极原著党,精通根据作品原文详细解释和回答问题,你在回答时会引用作品原文。
并且回答时仅根据原文,尽可能回答用户问题,如果原文中没有相关内容,你可以回答“原文中没有相关内容”,
以下是原文中跟用户回答相关的内容:
{context}
现在,你需要基于原文,回答以下问题:
{question}`;
// 在运行时,我们只要将对应的变量传递给 prompt 就能将 prompt 中对应的变量替换成真实值。
this.prompt = ChatPromptTemplate.fromTemplate(TEMPLATE);
}
- 3 创建chain
- 先创建一个retirver chain,可以将输出的document通过convertDocsToString转为字符串,
- 然后创建一个rag chain,定义prompt,将retriever得到的pageContent作为上下文内容context,问题作为question,传给prompt,
- 然后该prompt交给LLM,最后将调用StringOutputParser将输出转为字符串。
convertDocsToString(documents: Document[]): string {
return documents.map((document) => document.pageContent).join("\n");
}
async ask(question: string) {
if (!this.retriever) {
this.questions.push(question);
return;
}
const contextRetriverChain = RunnableSequence.from([
// 1. 从输入中提取问题
(input) => input.question,
// 2. 从向量存储中检索文档
this.retriever,
// 3. 将文档转换为字符串
this.convertDocsToString,
]);
this.ragChain = RunnableSequence.from([
// 1. 从输入中提取问题,然后转为字符串,然后传给prompt,然后传给chatModel
{
context: contextRetriverChain,
question: (input) => input.question,
},
// 2固定的prompt
this.prompt,
// 3. 调用模型
this.chatModel,
// 4. 解析输出
new StringOutputParser(),
]);
const res = await this.ragChain.invoke({ question });
return res;
}
所有代码
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { FaissStore } from "@langchain/community/vectorstores/faiss";
import { VectorStoreRetriever } from "@langchain/core/dist/vectorstores";
import {
chatModel,
wenxinyiyanEmbeddings,
} from "./mode";
import { readdirSync } from "fs";
import { Document } from "@langchain/core/documents";
import { RunnableSequence } from "@langchain/core/runnables";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { ChatOpenAI, ChatOpenAICallOptions } from "@langchain/openai";
import { BaiduQianfanEmbeddings } from "@langchain/community/embeddings/baidu_qianfan";
import { StringOutputParser } from "@langchain/core/output_parsers";
const directory = "../db/sanguo";
class Bot {
questions: string[];
retriever: VectorStoreRetriever<FaissStore>;
prompt: any;
chatModel: ChatOpenAI<ChatOpenAICallOptions>;
embeddings: BaiduQianfanEmbeddings;
ragChain: RunnableSequence<any, string>;
constructor() {
this.chatModel = chatModel;
this.embeddings = wenxinyiyanEmbeddings;
}
// 切割文档,存为向量
async initVector() {
const dir = readdirSync("../db/sanguo");
if (dir.length) {
return;
}
const loader = new TextLoader("../data/1.txt");
const docs = await loader.load();
// 创建实例,设置分割文本的大小和重叠大小
const spliter = new RecursiveCharacterTextSplitter({
chunkOverlap: 100,
chunkSize: 500,
});
const splitDocs = await spliter.splitDocuments(docs);
// 使用FaissStore替换MemoryVectorStore 创建一个 FaissStore 实例
const vectorStore = await FaissStore.fromDocuments(
splitDocs,
this.embeddings
);
// 保存向量存储
await vectorStore.save(directory);
}
async init() {
await this.initVector();
this.generatorTemplate();
const vectorstore = await FaissStore.load(directory, wenxinyiyanEmbeddings);
this.retriever = vectorstore.asRetriever(2);
}
convertDocsToString(documents: Document[]): string {
return documents.map((document) => document.pageContent).join("\n");
}
async ask(question: string) {
if (!this.retriever) {
this.questions.push(question);
return;
}
const contextRetriverChain = RunnableSequence.from([
// 1. 从输入中提取问题
(input) => input.question,
// 2. 从向量存储中检索文档
this.retriever,
// 3. 将文档转换为字符串
this.convertDocsToString,
]);
this.ragChain = RunnableSequence.from([
// 1. 从输入中提取问题,然后转为字符串,然后传给prompt,然后传给chatModel
{
context: contextRetriverChain,
question: (input) => input.question,
},
// 2固定的prompt
this.prompt,
// 3. 调用模型
this.chatModel,
// 4. 解析输出
new StringOutputParser(),
]);
const res = await this.ragChain.invoke({ question });
return res;
}
generatorTemplate() {
// 设计prompt的时候,有技巧,比如 并且回答时仅根据原文,固定LLM的回答只能根据原文内容。
// 如果原文中没有相关内容,你可以回答“原文中没有相关内容”, 减少LLm的幻想问题。
const TEMPLATE = `
你是一个熟读老舍的《骆驼祥子》的终极原著党,精通根据作品原文详细解释和回答问题,你在回答时会引用作品原文。
并且回答时仅根据原文,尽可能回答用户问题,如果原文中没有相关内容,你可以回答“原文中没有相关内容”,
以下是原文中跟用户回答相关的内容:
{context}
现在,你需要基于原文,回答以下问题:
{question}`;
// 在运行时,我们只要将对应的变量传递给 prompt 就能将 prompt 中对应的变量替换成真实值。
this.prompt = ChatPromptTemplate.fromTemplate(TEMPLATE);
}
}
const bot = new Bot();
bot.init().then(async () => {
const content = await bot.ask("祥子是谁");
console.log("content==", content);
});
结果:

const bot = new Bot();
bot.init().then(async () => {
const content = await bot.ask("你觉得祥子映射了那时代哪些人");
console.log("content==", content);
});

小结
将上述的内容连在一起,我们就有了基于私域数据来构建rag chatbot的能力。缺点是目前的chatbot还是没有历史对话的数据。
让chatbot具有记忆
之前的bot是没有记忆的,当然可以暴力的把所有沟通上下文都给llm,但受限于LLM的上下文窗口,很容易触及到LLM的上下文窗口,也会花费大量的token。如果后续发的信息与前面的聊天记录无关,将无关的聊天记录都发给LLM,也会影响LLM关注点的错误等一系列问题。
ChatMessageHistory
chat history是一组Message子类对象组成的列表,可能是HumanMessage, AIMessage。
而Memory是构建在chat history之上的对象。
简单的说就是用户跟LLM的聊天记录会存在chat history中,然后我们并不会将完整的chat history嵌入到上下文中,而是提起摘要或返回几条聊天记录,这些处理逻辑就是Memory完成的。
chat history 负责忠实的记录聊天历史,Memory 负责在聊天历史之上整一些花活。
chat history
import { ChatMessageHistory } from "langchain/stores/message/in_memory";
import { HumanMessage, AIMessage } from "@langchain/core/messages";
const history = new ChatMessageHistory();
await history.addMessage(new HumanMessage("你好"));
await history.addMessage(new AIMessage("你好,我能为你做什么?"));
const messages = await history.getMessages();
console.log(messages);
结果
[
HumanMessage {
"content": "你好",
"additional_kwargs": {},
"response_metadata": {}
},
AIMessage {
"content": "你好,我能为你做什么?",
"additional_kwargs": {},
"response_metadata": {},
"tool_calls": [],
"invalid_tool_calls": []
}
]
这里我们模拟了人和AI的对话,然后放到history里面。
手动维护 chat history
我们目前的chatbot是无状态的,比如我们跟他说我们叫Tom,后面再问我叫什么的时候,llm应该会从聊天记录这个特殊的上下文中找到答案回答。
我们这里现最基础的把我们跟llm的所有聊天记录原封不动的给LLM。
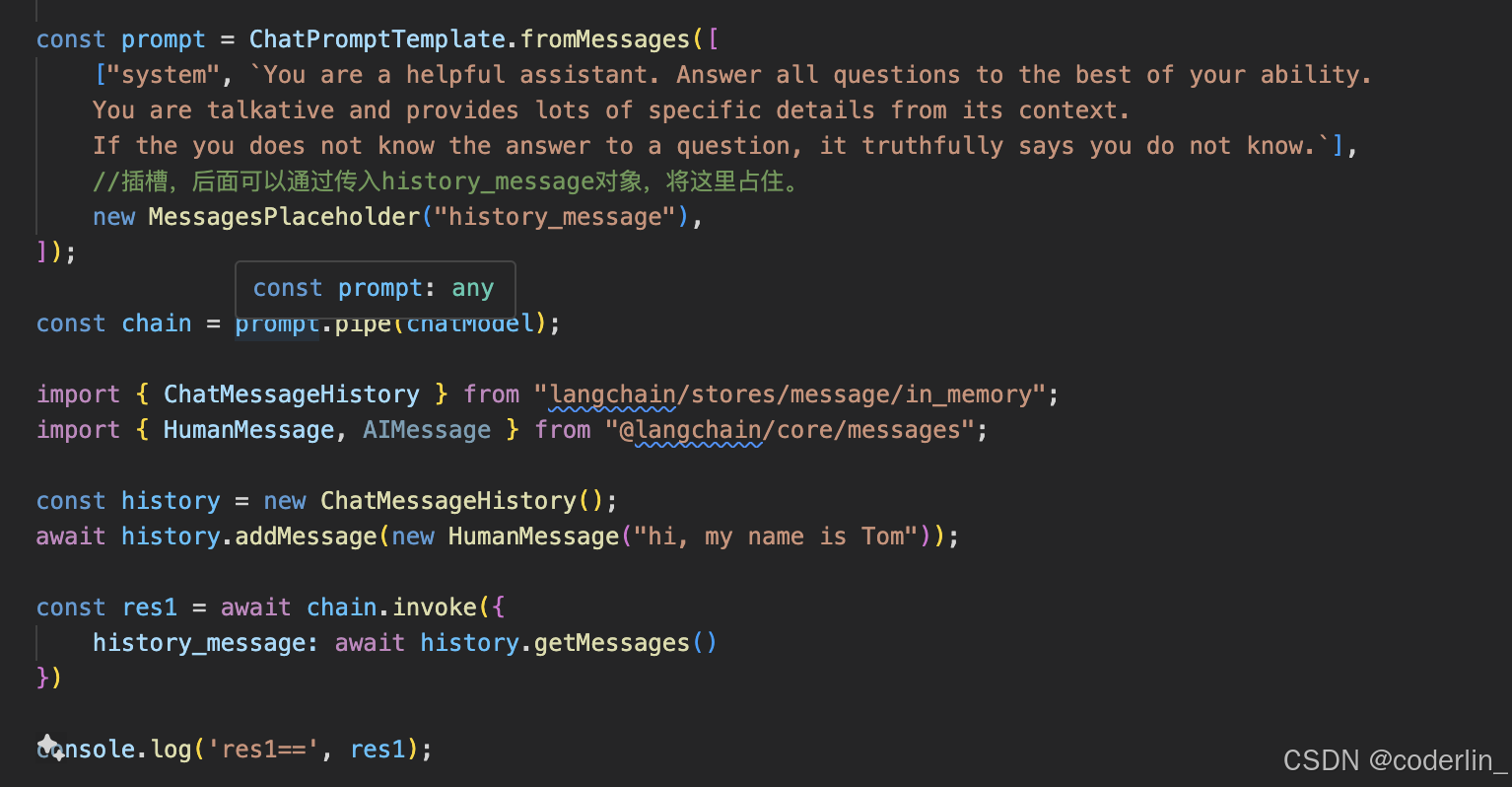
首先我们创建一个prompt,然后往chat hisotry中加入一个记录,然后传给chain,这样res1就是返回答案。
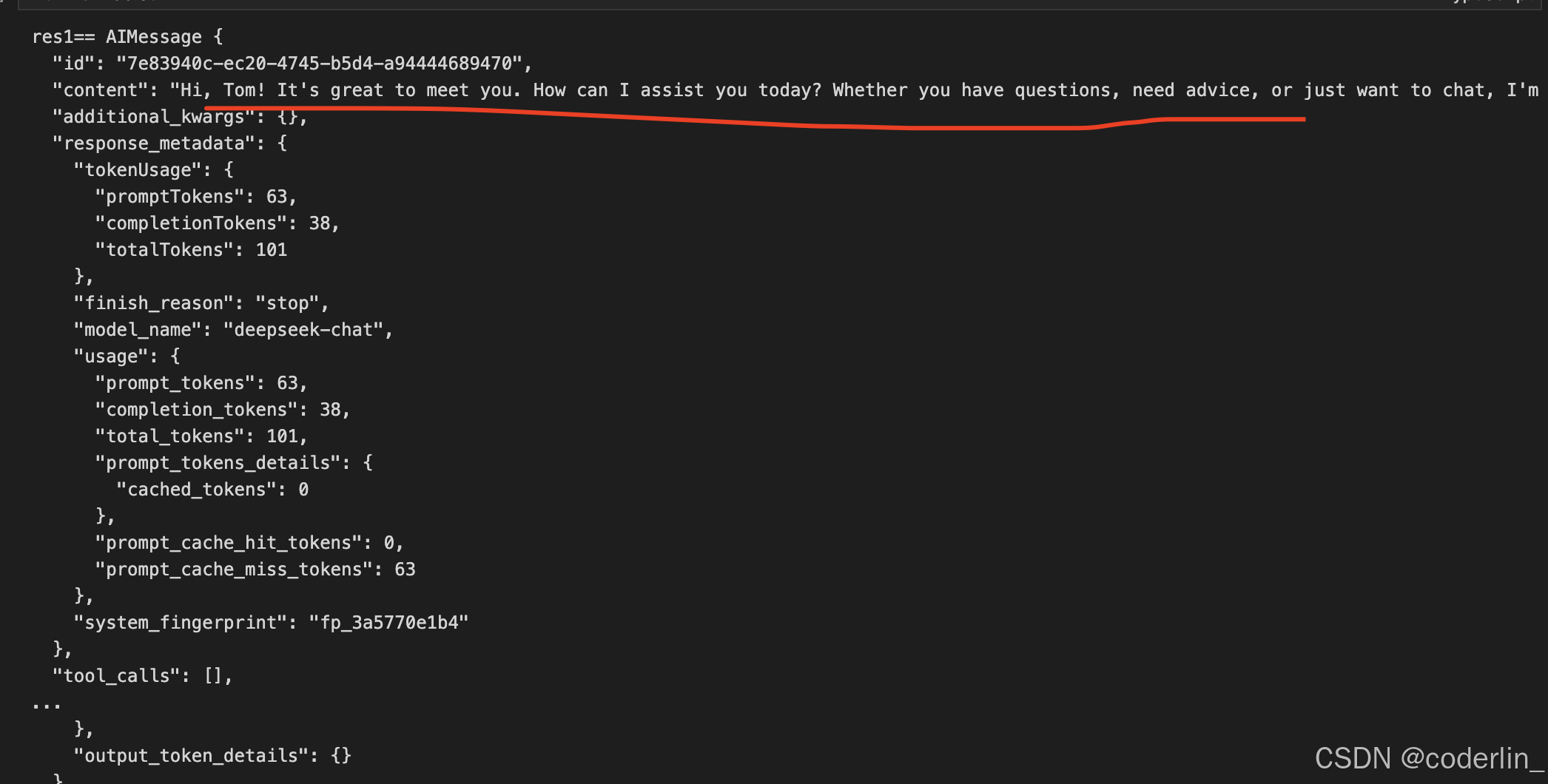
这是llm返回的消息,所以也要存到chat hisotry里去。再添加一条新的提问。
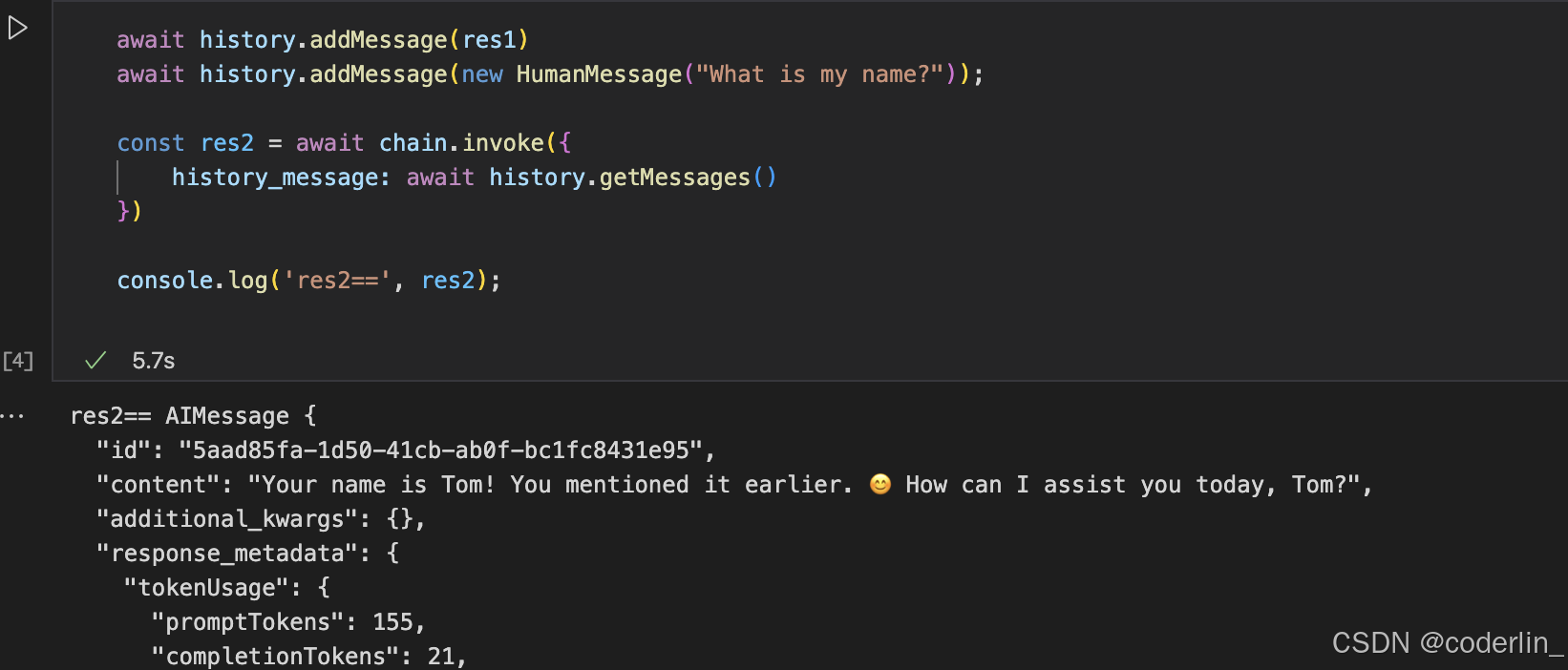
这就是手动维护啊chat history,本质上,chat history就是一个管理Message对象数组的一个对象。
自动维护chat hisotry
自动维护chat hisotry,可以用RunnableWithMessageHistory给任何chain包裹一层,
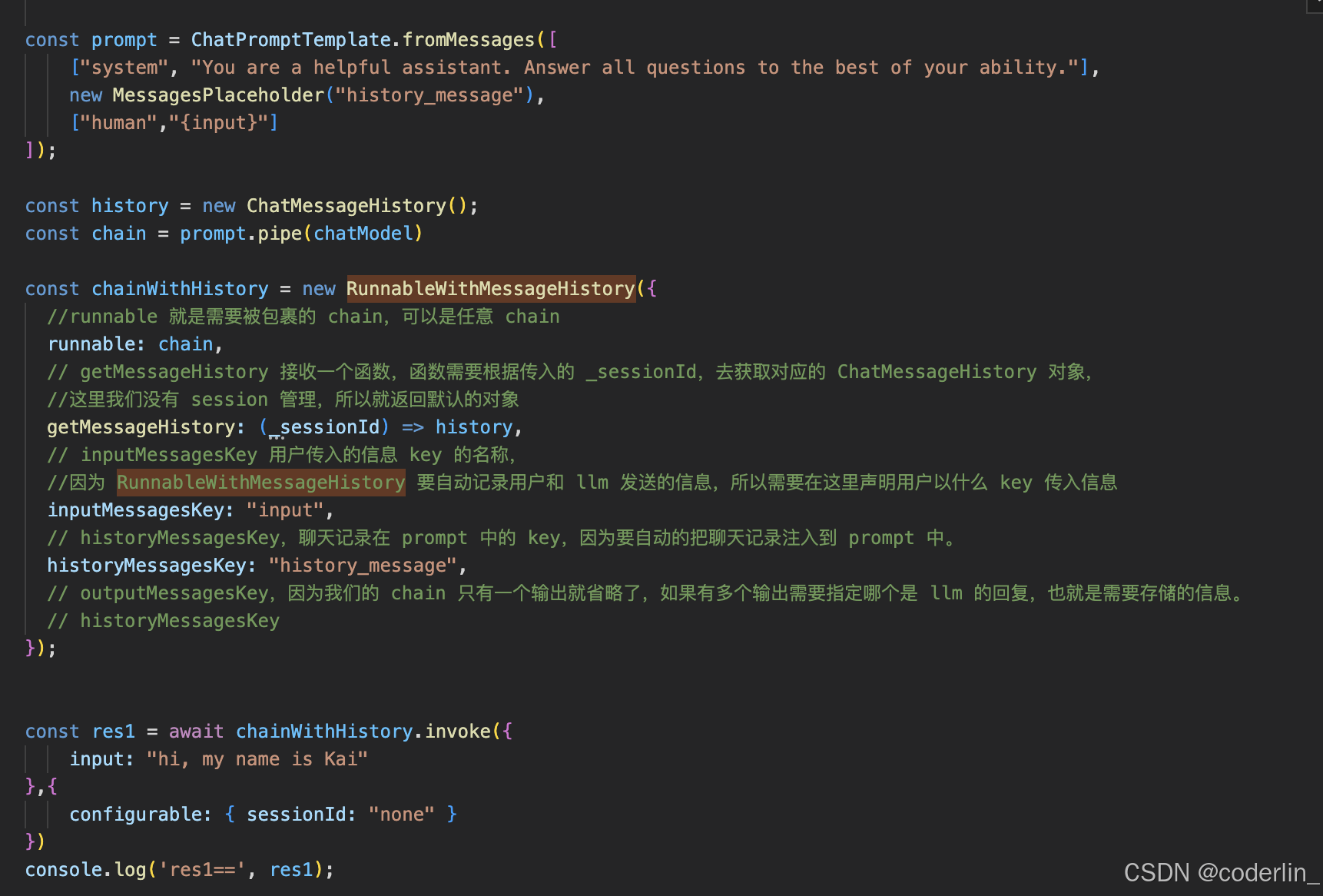
参数解释如上,这时就可以直接调用这个chian,其历史记录会自动保存。
除了正常 invoke 传入的参数外,还需要指定当前对话的 sessionId
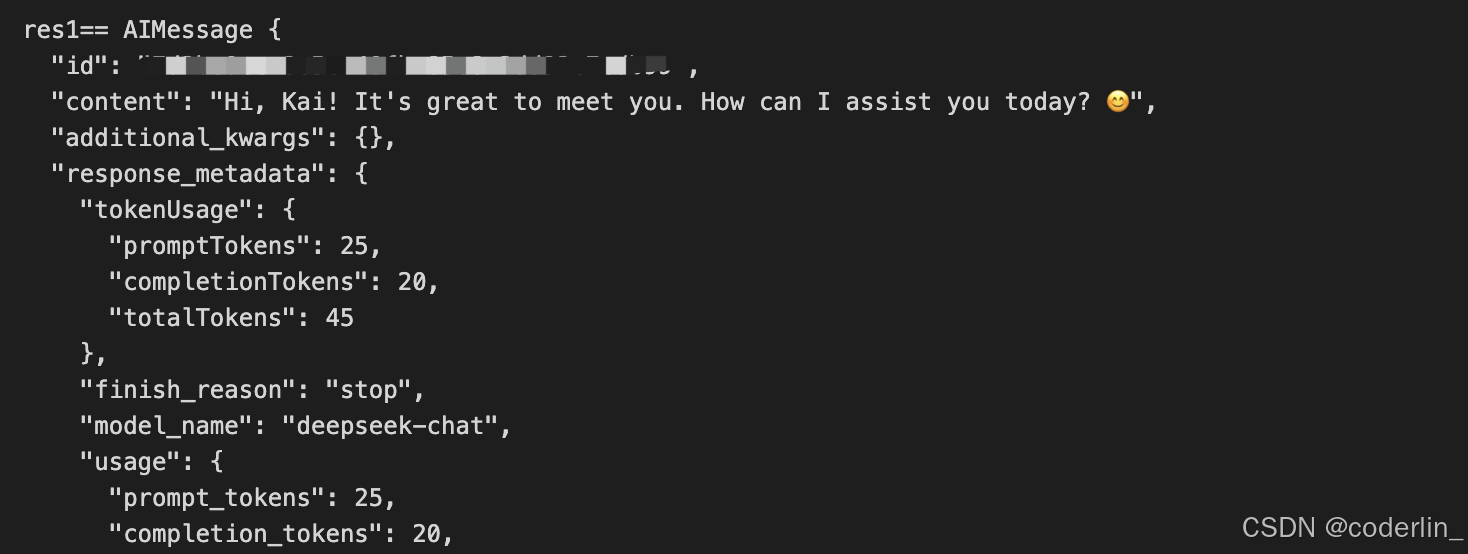
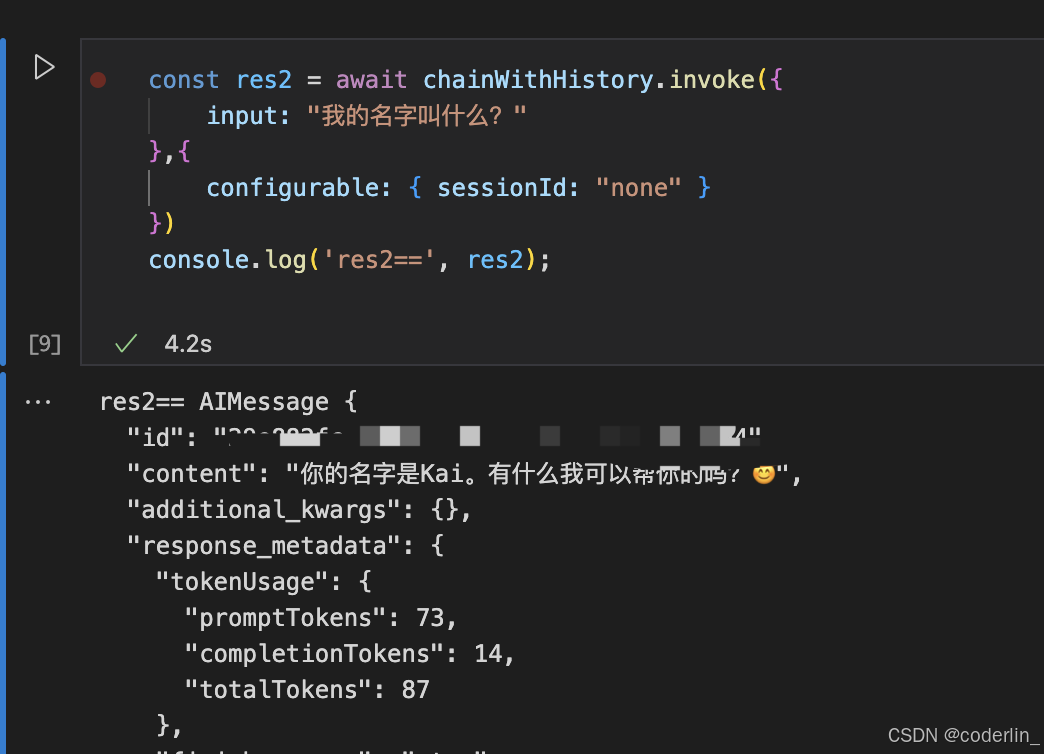
可以看到我们的chain有了记忆功能,打印history.getMessage(),就是刚才的四条记录
自动生成 chat history 摘要
前面的RunnableWithMessageHistory只是将历史记录完整的传递到LLM中,我们可以对LLM的历史记录进行更多操作,例如只传递最近的K条历史记录等
还可以实现自动对当前聊天记录进行总结,让llm根据总结的信息回复用户的chain。
首先实现一个总结的chain
这个 chain 接受两个参数:
- summary,上一次总结的信息
- new_lines,用户和 llm 新的回复
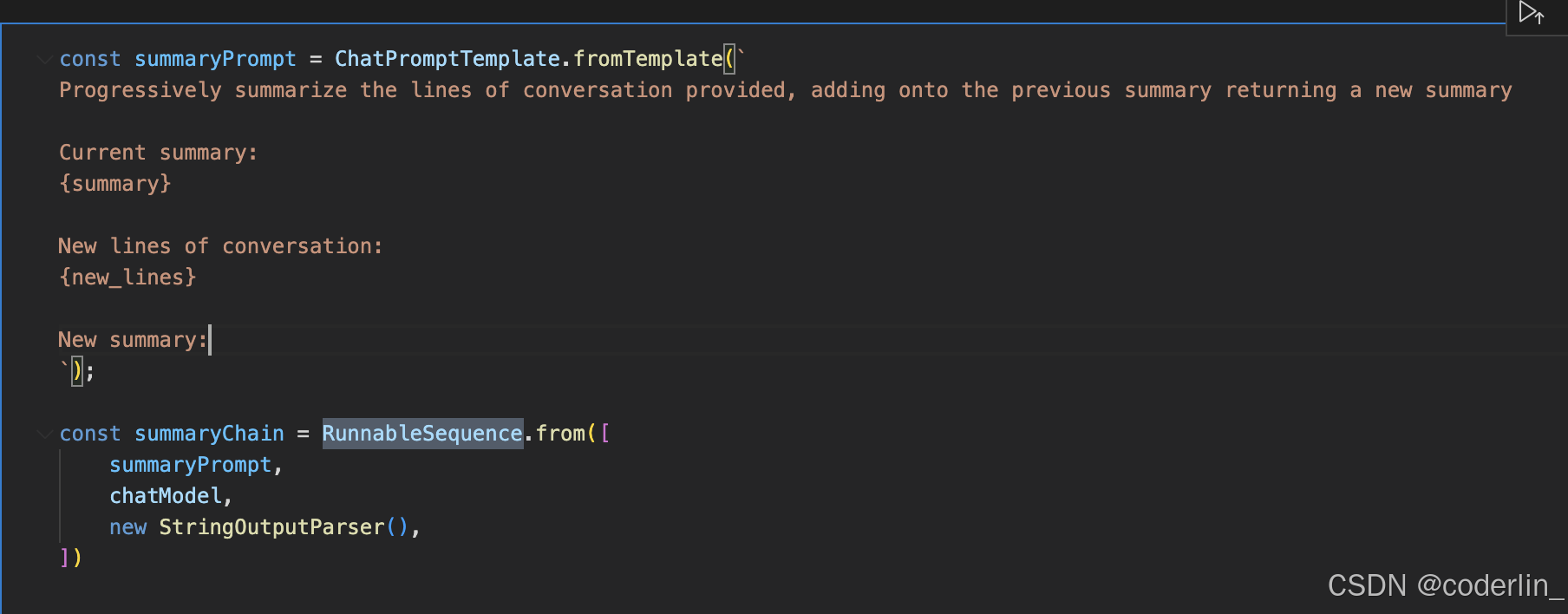
这个chain比较基础,传入两个变量prompt,然后将prompt传递给chat model,最后传滴给StringOutputParse生成纯文本。
然后调用一下
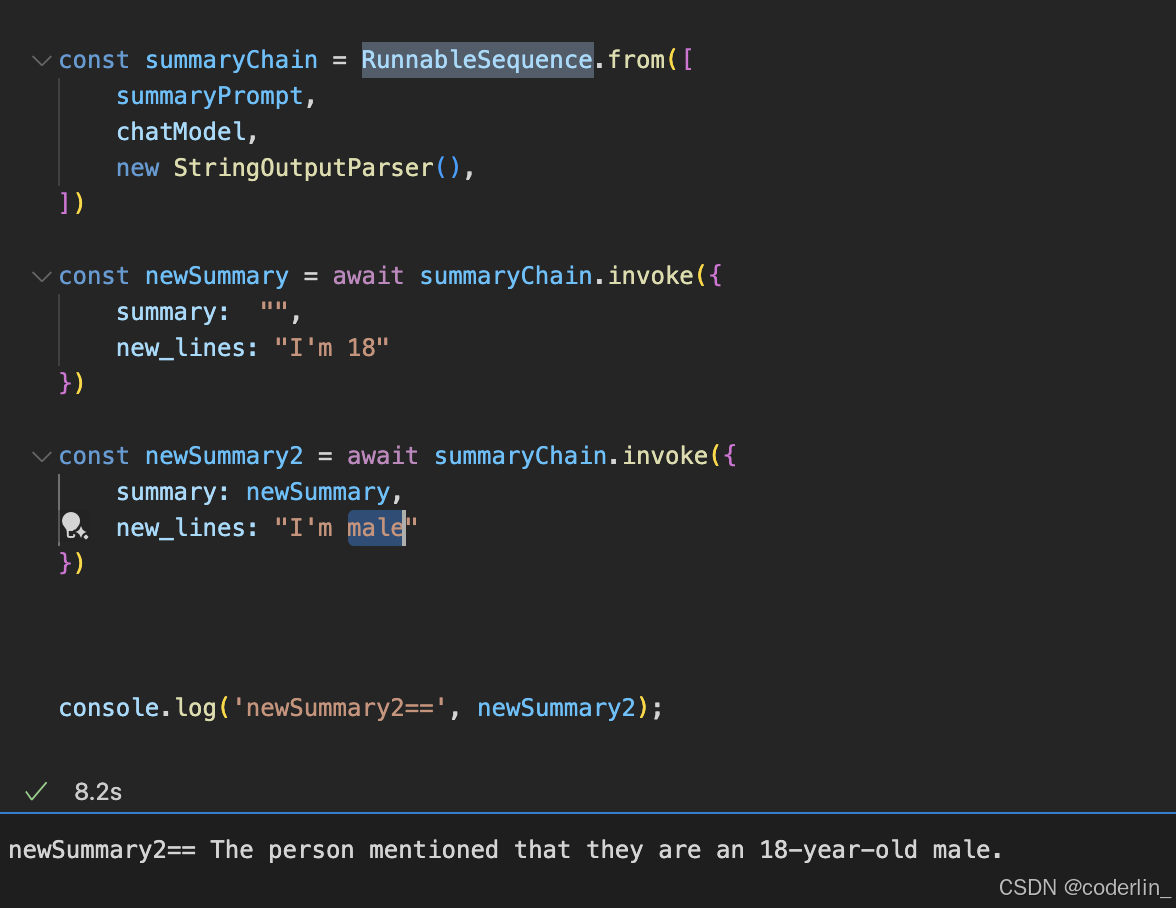
如此这般,就能实现渐进式总结历史聊天记录的chatbot,以此为基础构建一个chat bot,其会自动将聊天记录进行summary,并且传递给LLM作为上下文。
首先创建prompt
const chatPrompt = ChatPromptTemplate.fromMessages([
["system", `You are a helpful assistant. Answer all questions to the best of your ability.
Here is the chat history summary:
{history_summary}
`],
["human","{input}"]
]);
然后我们需要一个总结的chain
// 这里可以设置特殊的prompt,让其只总结想要的点。
const summaryPrompt = ChatPromptTemplate.fromTemplate(`
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary
Current summary:
{summary}
New lines of conversation:
{new_lines}
New summary:
`);
const summaryChain = RunnableSequence.from([
summaryPrompt,
chatModel,
new StringOutputParser(),
])
RunnableMap
RunnableMap概念,其是并行的执行多个 runnable 对象,然后返回结果对象的一个工具函数
比如
import { RunnableMap } from "@langchain/core/runnables"
const mapChain = RunnableMap.from({
a: () => "a",
b: () => "b"
})
const res = await mapChain.invoke()
// { a: "a", b: "b" }
函数也是一种 runnable 对象,这两个函数是并行执行的
如果这两个函数换成任意 runnable 对象,例如两个 chain 也就是会并行执行这两个 chain,并且返回相应的结果
然后实现一个完整的chain
let summary = ""
const history = new ChatMessageHistory();
// RunnableSequence 并行执行多个runnable对象
const chatChain = RunnableSequence.from([
// 自动转为RunnableMap对象,并行执行
{
// RunnablePassthrough 特殊节点,将input传给下一个节点,并且将input记录到chat history里面
input: new RunnablePassthrough({
func: (input) => history.addUserMessage(input)
})
},
// RunnablePassthrough.assign 是在不影响传递上一节点信息的基础上,再添加一部分信息。
//这里就是保留上一节点传递下来的 input 值,并且添加了 history_summary 值。
RunnablePassthrough.assign({
// 获取历史总结
history_summary: () => summary
}),
// input和sumary都会给chatPrompt
chatPrompt,
// chatPrompt给 chatModel
chatModel,
// 生成字符串
new StringOutputParser(),
// 做一些操作,记录信息,生成新的总结等等
new RunnablePassthrough({
func: async (input) => {
// 记录信息
history.addAIChatMessage(input)
// 获取所有历史信息
const messages = await history.getMessages()
// 转为string
const new_lines = getBufferString(messages)
// 通过summaryChain生成新的总结
const newSummary = await summaryChain.invoke({
summary,
new_lines
})
// 清掉历史记录
history.clear()
// 新的总结
summary = newSummary
}
})
])
然后试一下
const res1 = await chatChain.invoke("我现在饿了")
console.log('res1==', res1);
console.log('summary==', summary);
const res2 = await chatChain.invoke("我今天想吃方便面")
console.log('res1==', res2);
console.log('summary==', summary);
结果
res1== 既然你现在饿了,而且之前提到想吃方便面,我可以给你一些建议来提升方便面的味道和营养:
1. **加蔬菜**:比如菠菜、白菜、胡萝卜等,增加纤维和维生素。
2. **加蛋白质**:可以加一个鸡蛋,或者一些鸡肉、牛肉片,增加饱腹感和营养。
3. **少用调料包**:调料包通常含盐量较高,可以只用一半,或者用其他调味料代替,比如酱油、醋、辣椒酱等。
4. **加一些香料**:比如葱花、蒜末、香菜,提升风味。
如果你有其他偏好的口味或配料,告诉我,我可以给你更具体的建议! 😊
summary== The human reiterates that they are currently hungry, and the AI builds on the previous conversation by offering detailed suggestions to enhance the flavor and nutritional value of instant noodles, as previously discussed. The AI recommends adding vegetables like spinach, cabbage, or carrots for fiber and vitamins, incorporating protein sources such as eggs, chicken, or beef for satiety and nutrition, and using the seasoning packet sparingly to reduce sodium intake. Additionally, the AI suggests using alternative seasonings like soy sauce, vinegar, or chili sauce, and adding aromatic ingredients like scallions, garlic, or cilantro to elevate the dish. The AI invites the human to share specific flavor or topping preferences for more tailored recommendations, maintaining a focus on addressing hunger with practical and personalized advice.
res1== 好的!既然你今天想吃方便面,我们可以让它变得更美味和营养丰富。以下是一些建议,帮助你提升方便面的口感和营养价值:
### 1. **添加蔬菜**
- **推荐蔬菜**:菠菜、白菜、胡萝卜、蘑菇、豆芽等。
- **好处**:增加纤维和维生素,让方便面更健康。
### 2. **加入蛋白质**
- **推荐蛋白质**:鸡蛋、鸡胸肉、牛肉片、豆腐、虾仁等。
- **好处**:增加饱腹感,提供优质蛋白质。
### 3. **控制调味包用量**
- **建议**:只使用一半或三分之一的调味包,减少钠的摄入。
- **替代调味**:可以用酱油、醋、辣椒酱、芝麻油等代替部分调味包。
### 4. **加入香辛料和香草**
- **推荐**:葱花、蒜末、姜片、香菜、芝麻等。
...
- **海苔或芝麻**:撒一些海苔片或芝麻,增加口感和香气。
如果你有特别喜欢的口味或配料,可以告诉我,我可以为你提供更个性化的建议!😊
summary== The human expresses a desire to eat instant noodles today, and the AI responds with a detailed guide to enhance both the flavor and nutritional value of the dish. Building on previous suggestions, the AI recommends adding vegetables like spinach, cabbage, carrots, mushrooms, and bean sprouts for fiber and vitamins, as well as incorporating protein sources such as eggs, chicken, beef, tofu, or shrimp for satiety and nutrition. To reduce sodium intake, the AI advises using only a portion of the seasoning packet and suggests alternatives like soy sauce, vinegar, chili sauce, or sesame oil. Aromatic ingredients like scallions, garlic, ginger, cilantro, and sesame seeds are recommended to elevate the dish's flavor. The AI also proposes experimenting with different broths, such as chicken, bone, or vegetable stock, for a richer base. Creative additions like chili oil, lemon juice, milk, or coconut milk are suggested for those who enjoy spicy, tangy, or creamy flavors. Quick upgrades, such as adding a fried egg or garnishing with seaweed or sesame seeds, are also highlighted. The AI concludes by inviting the human to share specific preferences for more tailored recommendations, maintaining a focus on practical and personalized advice to address hunger while improving the meal's quality.
上述我们使用 new RunnablePassthrough({func: (input)=> void}),是有两个目的:
- 如果我们只写 new RunnablePassthrough(),那就是把用户输入的 input 再传递到下一个 runnable 节点中,不做任何操作,因为RunableMap返回值是对其中每个chain执行,将返回值给下一个runable节点。反之如果不对input使用RunablePassthrough,则下个chian拿不到input的值。
- new RunnablePassthrough({func: (input)=> void}) 中的 func 函数是在传递 input 的过程中,执行一个函数,这个函数返回值是 void,也就是无论其内容是什么,都不会对 input 造成影响。
第一个节点中,我们是希望将用户的输入存储到 history 中,并且将 input 原封不动的传递给下一个节点
RunnablePassthrough.assign 是在不影响传递上一节点信息的基础上,再添加一部分信息。这里就是保留上一节点传递下来的 input 值,并且添加了 history_summary 值。
然后,随着用户对话的继续,summary会更新总结,并作为后续的上下文,这样对比直接提供历史内容更加节省tomen,也可以通过设置特殊的prompt给summaryChain,让其总结的时候只关注哪些点,比如这是一个购物车的bot,可以通过指令让其总结信息的时候,只关注购物车的内容,忽略其他内容,以此提高总结。信息密度
小结
ChatMessageHistory管理Message对象,能将对话信息存储起来,然后创建一个summaryChain,自动总结聊天记录,减少对话大小,最后将总结作为上下文交给chain,让其具备记忆功能。
深入Memory机制
Langchain 在 chat history 的基础上抽象出了 Memory 对象,从命名可以看出来从 history => memory,是希望后者能够更像人类一样在不断的对话中去汇总出有价值的信息,而不只是暴力的记忆完整的信息。
ConversationChain

ConverstiaonChain调用起来非常方便,但他是高度封装的chain,外部能做的修改很少,限制的开发的自由度。
加上debug后
在运行的时候,ConverstaionChain会自动传入一个history属性,是字符串化后的chat history:
[chain/start] [1:chain:ConversationChain] Entering Chain run with input: {
"input": "我叫什么?",
"history": "Human: 我是小明\nAI: 你好,小明!很高兴认识你。你今天过得怎么样?有什么我可以帮忙的吗?\nHuman: 我叫什么?\nAI: 你刚刚告诉我你叫小明呀!😊 如果你有其他问题或需要帮助,随时告诉我哦!"
}
而调用llm传入的prompt是
"The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 我是小明
AI: 你好,小明!很高兴认识你。你今天过得怎么样?有什么我可以帮忙的吗?
Human: 我叫什么?
AI: 你刚刚告诉我你叫小明呀!😊 如果你有其他问题或需要帮助,随时告诉我哦!
可以看到和上面实现的记忆对话的chain是一样的,这里的prompt是可以自定义的,但如果想加入更加复杂的机制,比如上一节中自动实现的自动sumary chat history的chain就很暗,而ConverstiaonChain没有暴露自定义借口的属性。
内置Memory的机制
BufferWindowMemory,最多记住k个对话的记忆机制
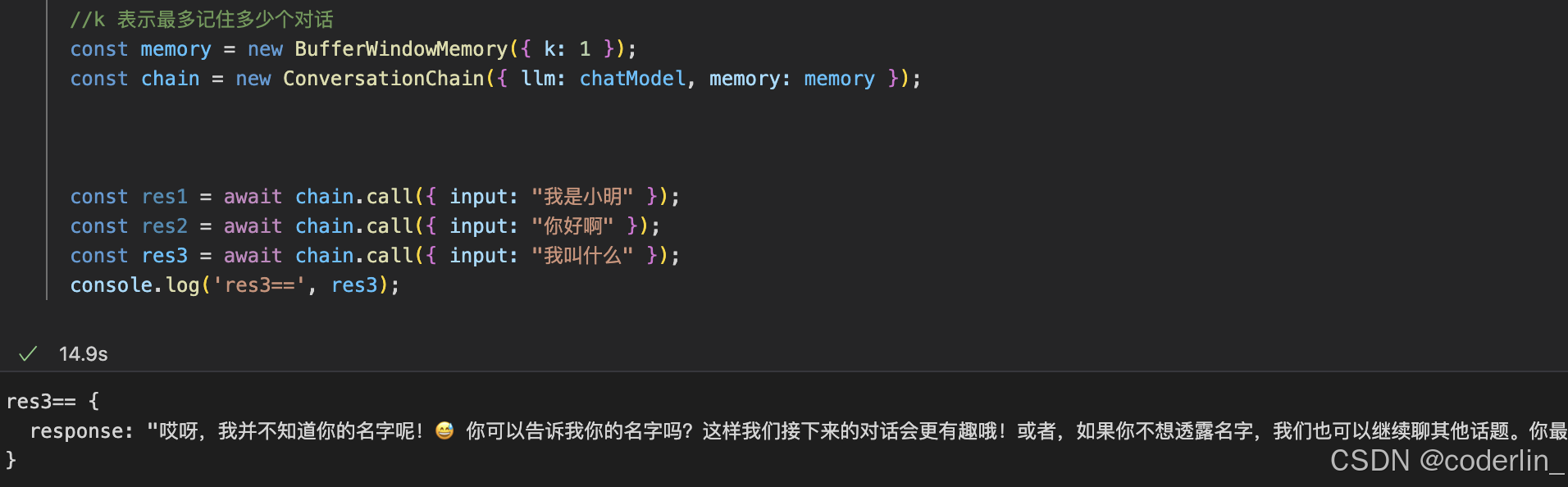
ConversationSummaryMemory
上面我们实现了类似于总结的 summary chain,而langchain也提供了类似的工具。
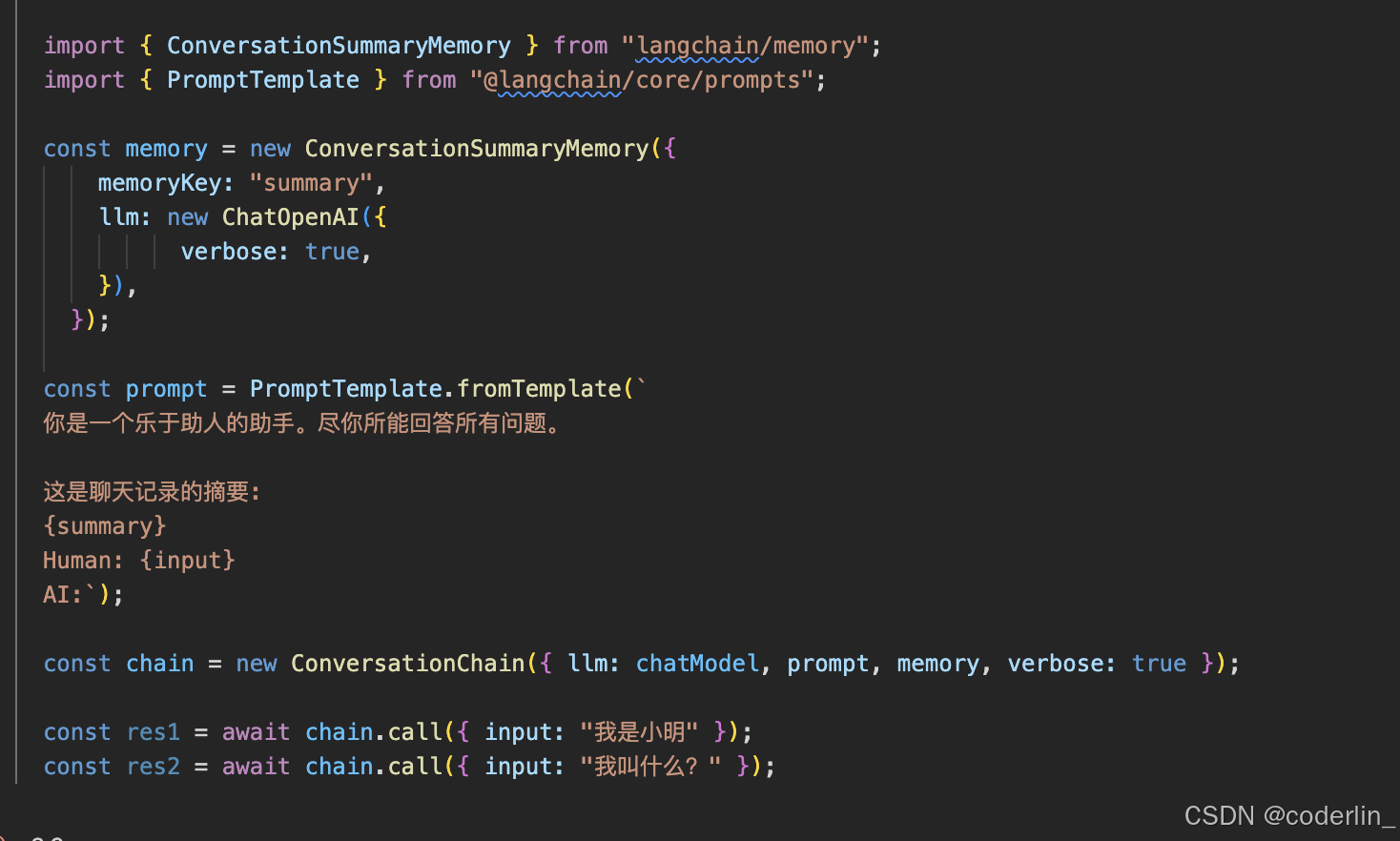
ConversationSummaryMemory使用llm渐进式的总结聊天记录生成summary,跟我们实现的类似。
"Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
Current summary:
The human introduces themselves as 小明 (Xiao Ming). The AI greets Xiao Ming and expresses pleasure in meeting them, asking if there is anything it can assist with.
New lines of conversation:
Human: 我叫什么?
AI: 你叫小明 (Xiao Ming)。
New summary:,
summary
:
"The human introduces themselves as 小明 (Xiao Ming). The AI greets Xiao Ming and expresses pleasure in meeting them, asking if there is anything it can assist with. The human then asks what their name is, and the AI confirms that their name is 小明 (Xiao Ming).",
跟我们的实现相似,但是langchain为了提升summary的效果,会在prompt中加入一些例子。
我们可以将BufferWindowMemory和ConverstionSumaryMeory结合起来,根据token数量,如果上下文大就切到summary,如果小就用原始聊天记录,也就有了ConversationSummaryBufferMemory
ConversationSummaryBufferMemory

maxTokenLimit,设置限制,当前聊天记录的token数超过设置的limit的时候,就会将聊天记录总结成sumary输入进去。
ConversationSummaryBufferMemory设计有点暴力,短对话就用BufferWindowMemory,长聊天就用ConversationSummaryMemory,没有特别的提升,最好是每次对话时,带上前k次对话的原始内容+一直持续更新的esummary,这样在长对话也能让LLM记忆最近的对话+长期对话总结的summary。
EntityMemory
import { ChatOpenAI } from "@langchain/openai";
import { EntityMemory, ENTITY_MEMORY_CONVERSATION_TEMPLATE } from "langchain/memory";
import { ConversationChain } from "langchain/chains";
const model = new ChatOpenAI();
const memory = new EntityMemory({
llm: new ChatOpenAI({
verbose: true
}),
chatHistoryKey: "history",
entitiesKey: "entities"
});
const chain = new ConversationChain({
llm: model,
prompt: ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory: memory,
verbose: true
});
ENTITY_MEMORY_CONVERSATION_TEMPLATE是langchain提供的默认用语EntityMemory chat的prompt。
进行对话
const res1 = await chain.call({ input: "我叫小明,今年 18 岁" });
const res2 = await chain.call({ input: "ABC 是一家互联网公司,主要是售卖方便面的公司" });
看一下EntityMemory的prompt
You are an AI assistant reading the transcript of a conversation between an AI and a
human. Extract all of the proper nouns from the last line of conversation. As a
guideline, a proper noun is generally capitalized. You should definitely extract all
names and places.
(你是一个人工智能助理,正在阅读一个人工智能和一个人类之间的对话记录。从对话的最后一行中提取所有的专有名词。作为指导原则,专有名词通常大写。你绝对应该提取所有的名字和地点。)
The conversation history is provided just in case of a coreference
(e.g. \"What do you know about him\" where \"him\" is defined in a previous line) --
ignore items mentioned there that are not in the last line.
Return the output as a single comma-separated list, or NONE if there is nothing of note to return (e.g. the user is just issuing a greeting or having a simple conversation).
(会话历史记录只是在共引用的情况下提供的 (例如 “ What do you know about him” 其中 “him” 在前一行中定义)—— 忽略那里提到的不在最后一行中的项目。以逗号分隔的列表形式返回输出,如果没有需要返回的内容 (例如,用户只是发出问候语或进行简单的会话) ,则返回 NONE。)
EXAMPLE
Conversation history:
Person #1: my name is Jacob. how's it going today?
AI: \"It's going great! How about you?\"
Person #1: good! busy working on Langchain. lots to do.
AI: \"That sounds like a lot of work! What kind of things are you doing to make Langchain better?\"
Last line:
Person #1: i'm trying to improve Langchain's interfaces, the UX, its integrations with various products the user might want ... a lot of stuff.
Output: Jacob,Langchain
END OF EXAMPLE
EXAMPLE
Conversation history:
Person #1: how's it going today?
AI: \"It's going great! How about you?\"
Person #1: good! busy working on Langchain. lots to do.
AI: \"That sounds like a lot of work! What kind of things are you doing to make Langchain better?\"
Last line:
Person #1: i'm trying to improve Langchain's interfaces, the UX, its integrations with various products the user might want ... a lot of stuff. I'm working with Person #2.
Output: Langchain, Person #2
END OF EXAMPLE
Conversation history (for reference only):
Human: 我叫小明,今年 18 岁
AI: 你好,小明!很高兴认识你。你今年18岁,正是年轻有活力的时候。有什么问题我能帮你解答,或者关于什么话题你想和我交谈呢?
Last line of conversation (for extraction):
Human: ABC 是一家互联网公司,主要是售卖方便面的公司
Output:
首先第一段介绍任务,表明当前的AI是一个从对话记录中,提取名次的AI智能助理。第二段强调聊天记录仅仅用于参考,强调只提取最后一次对话中出现的专有名词,并制定返回格式。
然后给出两个例子。
最后 Conversation history (for reference only) 再次强化 chat history 只是为了作为参考
Last line of conversation (for extraction) 这里才是作为提取的目标
最后LLM返回了"ABC",表示只提取了ABC,没有提取小明。
在聊天之后,EntityMemory 会提取对实体的描述,其中的 prompt 是:
You are an AI assistant helping a human keep track of facts about relevant people,
places, and concepts in their life. Update and add to the summary of the provided
entity in the \"Entity\" section based on the last line of your conversation with the
human. If you are writing the summary for the first time, return a single
sentence.
(你是一个人工智能助手,帮助人类记录生活中相关人物、地点和概念的事实。根据您与人类对话的最后一行,更新并添加到 “实体” 部分中提供的实体的摘要中。如果你是第一次写摘要,返回一个句子。)
The update should only include facts that are relayed in the last line of
conversation about the provided entity, and should only contain facts about the
provided entity.
(更新应该只包含在关于所提供实体的对话的最后一行中转发的事实,并且应该只包含关于所提供实体的事实。)
If there is no new information about the provided entity or the information is not worth noting (not an important or relevant fact to remember long-term), output the exact string \"UNCHANGED\" below.
如果没有关于所提供实体的新信息,或者该信息不值得注意 (不是一个需要长期记住的重要或相关事实) ,输出下面的确切字符串 “UNCHANGED”
// 下面作为上下文
Full conversation history (for context):
Human: 我叫小明,今年 18 岁
AI: 你好,小明!很高兴认识你。你今年18岁,正是年轻有活力的时候。有什么问题我能帮你解答,或者关于什么话题你想和我交谈呢?
Human: ABC 是一家互联网公司,主要是售卖方便面的公司
AI: ABC是一个非常有趣的公司,把互联网技术和方便面销售结合在一起。这两个领域似乎毫不相关,但在这个时代,创新的商业模式正在不断涌现。他们是否有使用特殊的营销策略或技术来提高销售或提高客户体验呢?
// 输出实体
Entity to summarize:
ABC
//实体总结
Existing summary of ABC:
No current information known.
// 最后的记录
Last line of conversation:
Human: ABC 是一家互联网公司,主要是售卖方便面的公司
Updated summary (or the exact string \"UNCHANGED\" if there is no new information about ABC above):
这一个部分的不睦,是根据上一个prompt提取出来的实体,去更新用户提供的实体信息。
- 第一段去强调 llm 的任务,是记录有关实体的信息
- 第二段是将范围控制在用户最新一条信息内,并且只包含跟目标实体有关的内容
- 第三段是指定如果没有更新或者更新并不值得长期记忆,则返回特殊字符 UNCHANGED
- 后面这是提供聊天记录、需要记录的实体、当前记录的实体信息,以及跟用户的最后一次聊天记录
然后LLM就会返回跟实体相关的信息
ABC is an internet company that primarily sells instant noodles.
经过上面两次沟通,再次询问时
const res3 = await chain.call({ input: "介绍小明和 ABC" });
EntityMemory会跟上面一样,提取实体列表,并返回相关信息,以及聊天记录传入到ConversationChain的ENTITY_MEMORY_CONVERSATION_TEMPLATE,解析一下
You are an assistant to a human, powered by a large language model trained by OpenAI.
You are designed to be able to assist with a wide range of tasks, from answering simple
questions to providing in-depth explanations and discussions on a wide range of topics.
As a language model, you are able to generate human-like text based on the input you
receive, allowing you to engage in natural-sounding conversations and provide responses
that are coherent and relevant to the topic at hand.
(您被设计成能够协助完成范围广泛的任务,从回答简单的问题到就广泛的主题提供深入的解释和讨论。作为一个语言模型,您可以根据所接收的输入生成类似于人类的文本,允许您参与听起来很自然的对话,并提供与当前主题相关的连贯性响应。)
You are constantly learning and improving, and your capabilities are constantly
evolving. You are able to process and understand large amounts of text, and can use
this knowledge to provide accurate and informative responses to a wide range of
questions. You have access to some personalized information provided by the human in
the Context section below. Additionally, you are able to generate your own text based
on the input you receive, allowing you to engage in discussions and provide
explanations and descriptions on a wide range of topics.
(你在不断地学习和提高,你的能力也在不断地进化。您能够处理和理解大量的文本,并可以使用这些知识来提供准确和信息丰富的答复范围广泛的问题。您可以访问下面关联部分中的人提供的一些个性化信息。此外,您还可以根据收到的输入生成自己的文本,从而可以参与讨论,并就广泛的主题提供解释和描述。)
Overall, you are a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether the human needs help with a specific question or just wants to have a conversation about a particular topic, you are here to assist.
(总的来说,您是一个强大的工具,可以帮助完成范围广泛的任务,并提供有价值的见解和信息的广泛的主题。无论人们是需要帮助解决某个特定的问题,还是只是想就某个特定的话题进行一次对话,你都可以在这里提供帮助。)
// 上下文信息,实体总结
Context:
小明: 小明是一个18岁的年轻人,正处在热血沸腾的年纪。他可能正在学习或已经步入职场,具有无限的潜力和可能性。他和ABC公司有某种连接,但具体细节尚未提供。
ABC: ABC is an Internet company that primarily sells instant noodles.
//当前对话
Current conversation:
Human: 我叫小明,今年 18 岁
AI: 很高兴认识你,小明。你今年18岁,正是年轻有力的时候。有什么我可以帮助你的吗?
Human: ABC 是一家互联网公司,主要是售卖方便面的公司
AI: 我明白了,ABC 是一家专注于售卖方便面的互联网公司。这是一个非常有趣的商业模式。你想知道更多关于这个公司的信息,还是有关于其它的问题需要我为你解答?
Last line:
Human: 介绍小明和 ABC
You:
这个prompt的目的性是构建一个通用型的chat bot。You have access to some personalized information provided by the human in the Context section below(您可以访问下面关联部分中的人提供的一些个性化信息)对 llm 指定了在 context 部分提供与上下文相关的背景信息供 llm 参考。
小结
所以 langchain 内部为了实现对实体的记忆,在一次沟通中使用了非常多次 llm 进行知识的总结和提取。
chat bot 不止是一个简单的调 API 的任务,而且通过管理 prompt、多 llm 协同而成的一个工程任务。
memory的底层是chat history,所有的memory支持在创建的时候传入任意的chat history,如果没有传入,则memory会自己创建一个存储在内存的chat history。
chat history是原封不动的记录用户和llm的聊天记录,memory是基于内部的chat history进行一些处理形成的记忆。
增加RAG能力
之前的chat bot没有记忆功能,只能获取向量数据库中的资料+根据返回的资料回答用户问题。
现在我们加入LLM改写和chat hisory,使其成为更成熟的LLM应用。
llm 改写提问
有时候用户的一些提问会跟上下文来联动,所以我们可以通过LLM改写用户的提问,使其在检索的时候,能获取更高质量的回答。
先定义prompt
const rephraseChainPrompt = ChatPromptTemplate.fromMessages([
[
"system",
"给定以下对话和一个后续问题,请将后续问题重述为一个独立的问题。请注意,重述的问题应该包含足够的信息,使得没有看过对话历史的人也能理解。",
],
new MessagesPlaceholder("history"),
["human", "将以下问题重述为一个独立的问题:\n{question}"],
]);
我们通过system prompt去给LLM确定任务,根据聊天记录把对话重新描述成一个独立的问题,并强调问题的目标。
以此我们构建一个专门用来改写提问的chain。
const rephraseChain = RunnableSequence.from([
rephraseChainPrompt,
new ChatOpenAI({
// // 数值越低,llm 会越忠于事实,减少自己的自由发挥。
temperature: 0.2,
}),
new StringOutputParser(),
]);
const historyMessages = [new HumanMessage("你好,我叫小明"), new AIMessage("你好小明")];
(async () => {
const question = "你觉得我的名字怎么样?";
const standaloneQuestion = await rephraseChain.invoke({ history: historyMessages, question });
console.log(standaloneQuestion);
})()
结果

可以看到,我们用了“我的名字”这个代词,而在LLm的重述下,替换成了小明,除了解决代词的问题,也可以解决一些自然语言灵活性带来的问题,保证etriver时的问题是高质量的。
构建完整的 RAG chain
首先我们改造一下上面骆驼祥子的bot
首先是chat bot 的prompt
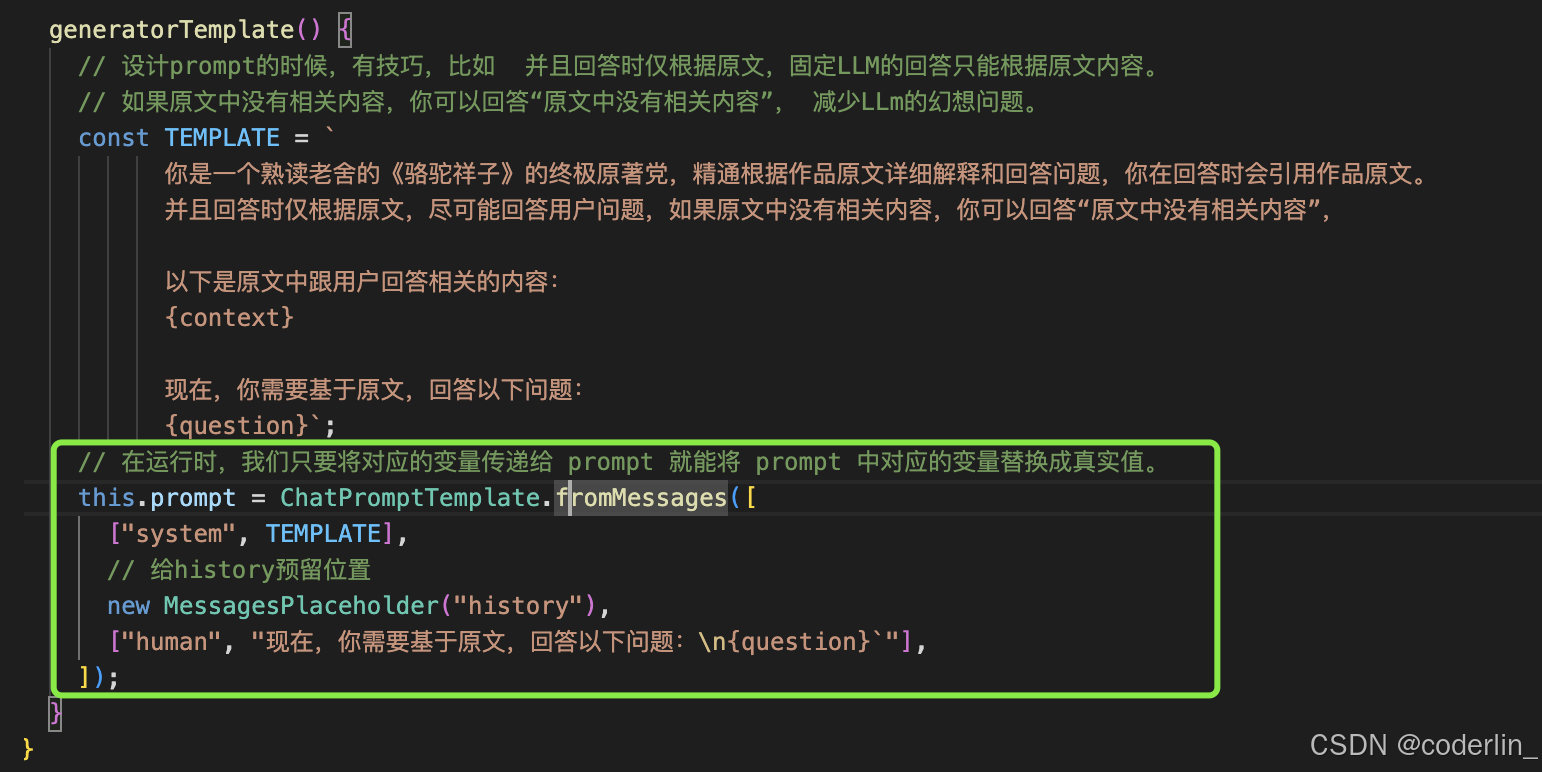
这里我们用hisotory占位符。
然后我们再创建一个改写提问的chain
/**生产 改写提问的chain */
async generatorQuestionTransformChain() {
// 提问的chain
const rephraseChainPrompt = ChatPromptTemplate.fromMessages([
[
"system",
"给定以下对话和一个后续问题,请将后续问题重述为一个独立的问题。请注意,重述的问题应该包含足够的信息,使得没有看过对话历史的人也能理解。",
],
new MessagesPlaceholder("history"),
["human", "将以下问题重述为一个独立的问题:\n{question}"],
]);
// 改写提问的chain
const rephraseChain = RunnableSequence.from([
rephraseChainPrompt,
chatModel,
new StringOutputParser(),
]);
return rephraseChain;
}
这个chain主要用来改写提问。
然后
async generatorChain() {
const contextRetriverChain = RunnableSequence.from([
// 1. 从输入中提取问题
(input) => input.question,
// 2. 从向量存储中检索文档
this.retriever,
// 3. 将文档转换为字符串
this.convertDocsToString,
]);
const ragChain = RunnableSequence.from([
// 第一个节点,将输入传给rephraseChain,让其改写提问
RunnablePassthrough.assign({
standalone_question: await this.generatorQuestionTransformChain(),
}),
// 第二个节点,将改写后的问题传给contextRetriverChain,检索向量数据库,返回相关的context
RunnablePassthrough.assign({
context: contextRetriverChain,
}),
// 传给prompt,生成提示
this.prompt,
// 传给llm
chatModel,
// 输出
new StringOutputParser(),
] as any);
// 使用RunnableWithMessageHistory增加聊天记录的功能
const ragChainWithHistory = new RunnableWithMessageHistory({
runnable: ragChain,
// 根据用户传入的 sessionId 去获取初始的 chat history
getMessageHistory: (sessionId) =>
new JSONChatHistory({ sessionId, dir: "../db/chatHistory" }),
// 设置聊天记录和输入文件的key
historyMessagesKey: "history",
inputMessagesKey: "question",
});
this.ragChain = ragChainWithHistory;
}
生成一个retriever chain用于在向量数据库中检索相关内容并返回。
然后生成一个ragChain,他有几个节点,将输入用llm改写,然后传给retriever chain,返回相关文档,key是context,然后传给prompt生成提示,最后给llm去输出。
但这个chain我们不直接用,而是用RunnableWithMessageHistory给其增加聊天记录的功能,如上。
JSONChatHistory是将chat history本地化的方法。
改写ark方法,
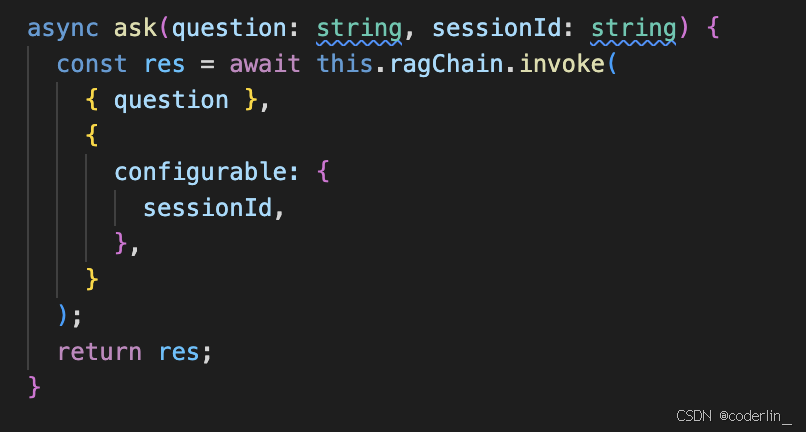
然后我们就可以使用了


第二个提问使用了他来做代词,然后chain因为有了历史记录的功能,加上自动改写提问,应该改成
“祥子”是做什么的。这样llm就能检索到正确的context,从而生成了完整的回答。
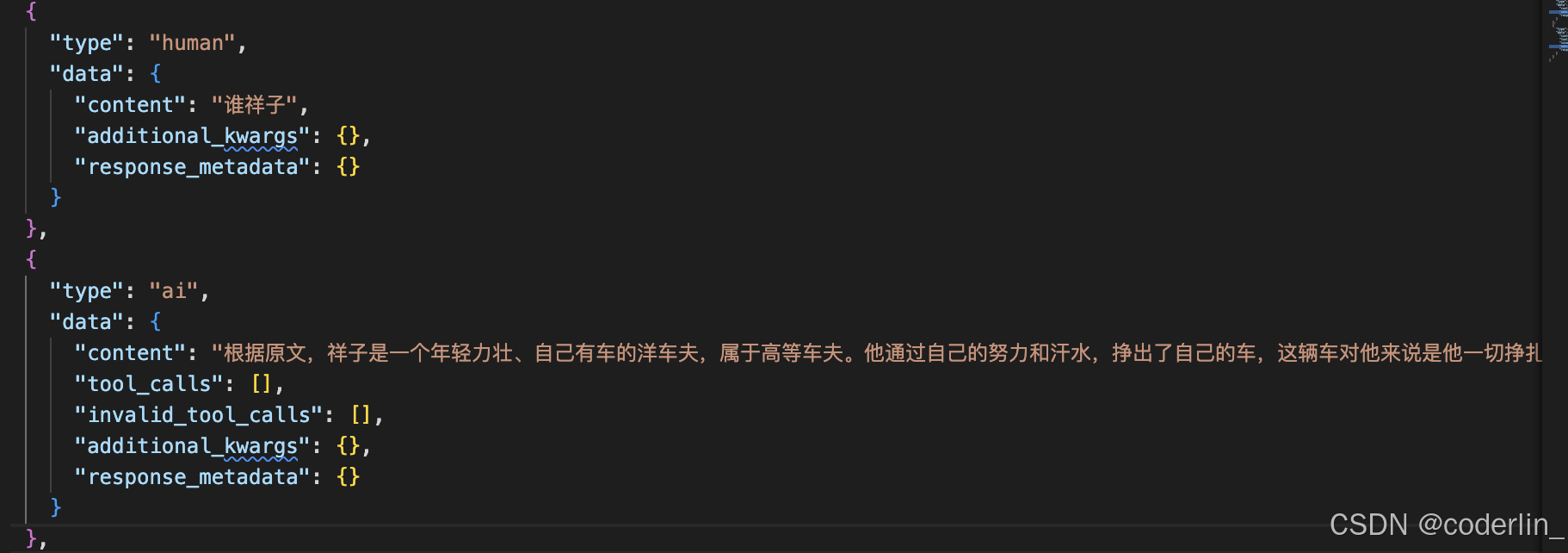

聊天记录本地化。
JSONChatHistory方法
import { BaseListChatMessageHistory } from "@langchain/core/chat_history";
import {
BaseMessage,
StoredMessage,
mapChatMessagesToStoredMessages,
mapStoredMessagesToChatMessages,
} from "@langchain/core/messages";
import fs from "node:fs";
import path from "node:path";
export interface JSONChatHistoryInput {
sessionId: string;
dir: string;
}
export class JSONChatHistory extends BaseListChatMessageHistory {
lc_namespace = ["langchain", "stores", "message"];
sessionId: string;
dir: string;
constructor(fields: JSONChatHistoryInput) {
super(fields);
this.sessionId = fields.sessionId;
this.dir = fields.dir;
}
async getMessages(): Promise<BaseMessage[]> {
const filePath = path.join(this.dir, `${this.sessionId}.json`);
try {
if (!fs.existsSync(filePath)) {
this.saveMessagesToFile([]);
return [];
}
const data = fs.readFileSync(filePath, { encoding: "utf-8" });
const storedMessages = JSON.parse(data) as StoredMessage[];
return mapStoredMessagesToChatMessages(storedMessages);
} catch (error) {
console.error(`Failed to read chat history from ${filePath}`, error);
return [];
}
}
async addMessage(message: BaseMessage): Promise<void> {
const messages = await this.getMessages();
messages.push(message);
await this.saveMessagesToFile(messages);
}
async addMessages(messages: BaseMessage[]): Promise<void> {
const existingMessages = await this.getMessages();
const allMessages = existingMessages.concat(messages);
await this.saveMessagesToFile(allMessages);
}
async clear(): Promise<void> {
const filePath = path.join(this.dir, `${this.sessionId}.json`);
try {
fs.unlinkSync(filePath);
} catch (error) {
console.error(`Failed to clear chat history from ${filePath}`, error);
}
}
private async saveMessagesToFile(messages: BaseMessage[]): Promise<void> {
const filePath = path.join(this.dir, `${this.sessionId}.json`);
const serializedMessages = mapChatMessagesToStoredMessages(messages);
try {
fs.writeFileSync(filePath, JSON.stringify(serializedMessages, null, 2), {
encoding: "utf-8",
});
} catch (error) {
console.error(`Failed to save chat history to ${filePath}`, error);
}
}
}
部署成API
用express起一个服务
import express from "express";
import { Bot } from "../node-copy/bot1";
const bot = new Bot();
const app = express();
const port = 8080;
app.use(express.json());
app.post("/", async (req, res) => {
const ragChain = bot.ragChain;
const body = req.body;
console.log('body==', body);
const result = await ragChain.stream(
{
question: body.question,
},
{ configurable: { sessionId: body.sessionId } }
);
res.set("Content-Type", "text/plain");
for await (const chunk of result) {
res.write(chunk);
}
res.end();
});
bot.init().then(() => {
app.listen(port, () => {
console.log(`Server is running on port ${port}`);
});
});
通过stream流的形式提问,然后通过流的形式返回。
如
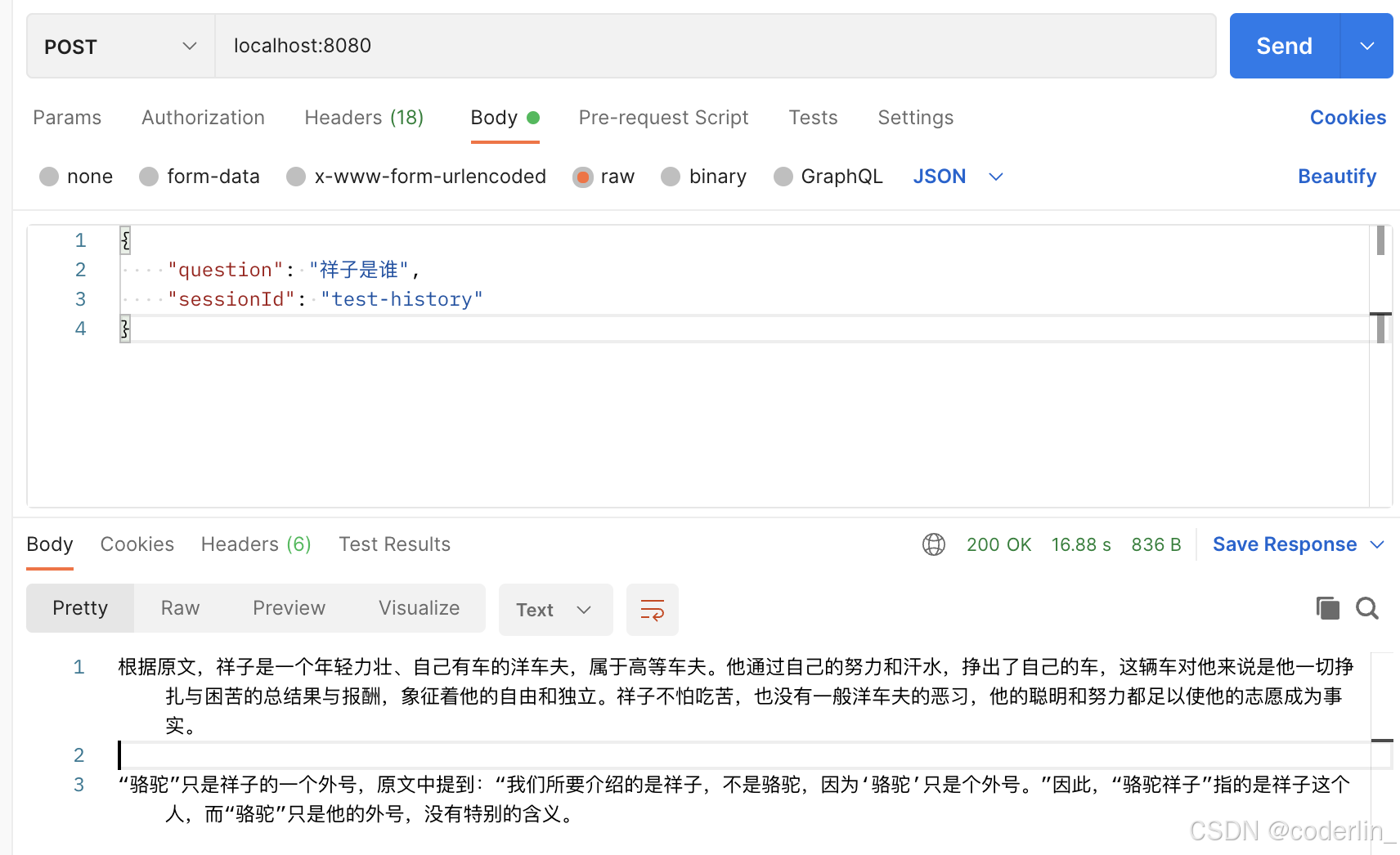
至此,我们就从0-1成功完成了一个rag chain。
对简单的业务,不需要记忆功能,用最简单的chat bot就行,每次提问都是独立的。
对于复杂点的bot,加入完整的chat history就意味着对llm上下文压力很大,每次消耗的token就会变多,不追求质量的话,基础的BufferWindowMemory,保留前两次聊天记录,然后用LLM改写提问节课。
如果是更复杂的chat bot,就要根据业务,文档资料,聊天的类型,选择合适的memory机制。


















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











