from numpy import *
def loadSimpData ( ) :
datMat = matrix(
[ [ 1 . , 2.1 ] ,
[ 2 . , 1.1 ] ,
[ 1.3 , 1 . ] ,
[ 1 . , 1 . ] ,
[ 2 . , 1 . ] ] )
classLabels = [ 1.0 , 1.0 , - 1.0 , - 1.0 , 1.0 ]
return datMat, classLabels
datMat, classLabels = loadSimpData( )
print ( datMat)
[[ 1. 2.1]
[ 2. 1.1]
[ 1.3 1. ]
[ 1. 1. ]
[ 2. 1. ]]
print ( classLabels)
[1.0, 1.0, -1.0, -1.0, 1.0]
math. log( 0.97 / 0.03 )
3.4760986898352733
math. log( 0.95 / 0.05 )
2.9444389791664403
math. log( 0.95 / 0.05 )
2.9444389791664403
def stumpClassify ( dataMatrix, dimen, threshVal, threshIneq) :
retArray = ones( ( shape( dataMatrix) [ 0 ] , 1 ) )
if threshIneq == 'lt' :
retArray[ dataMatrix[ : , dimen] <= threshVal] = - 1.0
else :
retArray[ dataMatrix[ : , dimen] > threshVal] = - 1.0
return retArray
def buildStump ( dataArr, classLabels, D) :
dataMatrix = mat( dataArr) ; labelMat = mat( classLabels) . T
m, n = shape( dataMatrix)
numSteps = 10.0
bestStump = { }
bestClasEst = mat( zeros( ( m, 1 ) ) )
minError = inf
for i in range ( n) :
rangeMin = dataMatrix[ : , i] . min ( ) ; rangeMax = dataMatrix[ : , i] . max ( )
print ( rangeMin)
print ( rangeMax)
stepSize = ( rangeMax - rangeMin) / numSteps
print ( stepSize)
for j in range ( - 1 , int ( numSteps) + 1 ) :
for inequal in [ 'lt' , 'gt' ] :
print ( j)
threshVal = ( rangeMin + float ( j) * stepSize)
print ( threshVal)
predictedVals = stumpClassify( dataMatrix, i, threshVal, inequal)
errArr = mat( ones( ( m, 1 ) ) )
errArr [ predictedVals == labelMat] = 0
weightedError = D. T* errArr
print ( "split:dim %d,thresh %.2f,thresh inequal: %s,the weighted error is %.3f" % ( i, threshVal, inequal, weightedError) )
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals. copy( )
bestStump[ 'dim' ] = i
bestStump[ 'thresh' ] = threshVal
bestStump[ 'ineq' ] = inequal
return bestStump, minError, bestClasEst
D = mat( ones( ( 5 , 1 ) ) / 5 )
print ( D)
[[ 0.2]
[ 0.2]
[ 0.2]
[ 0.2]
[ 0.2]]
buildStump( datMat, classLabels, D)
1.0
2.0
0.1
-1
0.9
({'dim': 0, 'ineq': 'lt', 'thresh': 1.3}, matrix([[ 0.2]]), array([[-1.],
[ 1.],
[-1.],
[-1.],
[ 1.]]))
def adaBoostTrainDS ( dataArr, classLabels, numIt = 40 ) :
weakClassArr = [ ]
m = shape( dataArr) [ 0 ]
D = mat( ones( ( m, 1 ) ) / m)
aggClassEst = mat( zeros( ( m, 1 ) ) )
for i in range ( numIt) :
bestStump, error, classEst = buildStump( dataArr, classLabels, D)
print ( "D:" , D. T)
alpha = float ( 0.5 * log( ( 1.0 - error) / max ( error, 1e - 16 ) ) )
bestStump[ 'alpah' ] = alpha
weakClassArr. append( bestStump)
print ( "classEst:" , classEst. T)
print ( classLabels)
print ( "classLabels:" , - 1 * alpha* mat( classLabels) . T)
expon = multiply( - 1 * alpha* mat( classLabels) . T, classEst)
print ( "expon:" , exp( expon) )
print ( "shapeD" , shape( D) )
print ( "shapeE" , shape( exp( expon) ) )
D = multiply( D, exp( expon) )
print ( D)
D = D/ D. sum ( )
aggClassEst += alpha * classEst
print ( "aggClassEst:" , aggClassEst. T)
aggErrors = multiply( sign( aggClassEst) != mat( classLabels) . T, ones( ( m, 1 ) ) )
errorRate = aggErrors. sum ( ) / m
print ( "total Error:" , errorRate, "\n" )
if errorRate == 0.0 : break
return weakClassArr
classifyArray = adaBoostTrainDS( datMat, classLabels, 9 )
1.0
2.0
0.1
-1
0.9
D: [[ 0.2 0.2 0.2 0.2 0.2]]
classEst: [[-1. 1. -1. -1. 1.]]
[1.0, 1.0, -1.0, -1.0, 1.0]
classLabels: [[-0.69314718]
[-0.69314718]
[ 0.69314718]
[ 0.69314718]
[-0.69314718]]
expon: [[ 2. ]
[ 0.5]
[ 0.5]
[ 0.5]
[ 0.5]]
shapeD (5, 1)
shapeE (5, 1)
[[ 0.4]
[ 0.1]
[ 0.1]
[ 0.1]
[ 0.1]]
aggClassEst: [[-0.69314718 0.69314718 -0.69314718 -0.69314718 0.69314718]]
total Error: 0.2
1.0
2.0
0.1
-1
0.9
shapeD (5, 1)
shapeE (5, 1)
[[ 0.11664237]
[ 0.02916059]
[ 0.17496355]
[ 0.17496355]
[ 0.20412415]]
aggClassEst: [[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]]
total Error: 0.0
def adaBoostTrainDS ( dataArr, classLabels, numIt = 40 ) :
weakClassArr = [ ]
m = shape( dataArr) [ 0 ]
D = mat( ones( ( m, 1 ) ) / m)
aggClassEst = mat( zeros( ( m, 1 ) ) )
for i in range ( numIt) :
bestStump, error, classEst = buildStump( dataArr, classLabels, D)
print ( "D:" , D. T)
alpha = float ( 0.5 * log( ( 1.0 - error) / max ( error, 1e - 16 ) ) )
bestStump[ 'alpha' ] = alpha
weakClassArr. append( bestStump)
print ( "classEst:" , classEst. T)
print ( classLabels)
print ( "classLabels:" , - 1 * alpha* mat( classLabels) . T)
expon = multiply( - 1 * alpha* mat( classLabels) . T, classEst)
print ( "expon:" , exp( expon) )
print ( "shapeD" , shape( D) )
print ( "shapeE" , shape( exp( expon) ) )
D = multiply( D, exp( expon) )
print ( D)
D = D/ D. sum ( )
aggClassEst += alpha * classEst
print ( "aggClassEst:" , aggClassEst. T)
aggErrors = multiply( sign( aggClassEst) != mat( classLabels) . T, ones( ( m, 1 ) ) )
errorRate = aggErrors. sum ( ) / m
print ( "total Error:" , errorRate, "\n" )
if errorRate == 0.0 : break
return weakClassArr, aggClassEst
classifyArray, aggClassEst = adaBoostTrainDS( datMat, classLabels, 9 )
1.0
2.0
0.1
-1
0.9
aggClassEst: [[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]]
total Error: 0.0
classifyArray
[{'alpha': 0.6931471805599453, 'dim': 0, 'ineq': 'lt', 'thresh': 1.3},
{'alpha': 0.9729550745276565, 'dim': 1, 'ineq': 'lt', 'thresh': 1.0},
{'alpha': 0.8958797346140273,
'dim': 0,
'ineq': 'lt',
'thresh': 0.90000000000000002}]
def adaClassify ( datToClass, classifierArr) :
dataMatrix = mat( datToClass)
m = shape( dataMatrix) [ 0 ]
aggClassEst = mat( zeros( ( m, 1 ) ) )
for i in range ( len ( classifierArr) ) :
classEst = stumpClassify( dataMatrix, classifierArr[ i] [ 'dim' ] , classifierArr[ i] [ 'thresh' ] , classifierArr[ i] [ 'ineq' ] )
aggClassEst += classifierArr[ i] [ 'alpha' ] * classEst
print ( aggClassEst)
return sign( aggClassEst)
datArr, labelArr = loadSimpData( )
classifierArr, aggClassEst = adaBoostTrainDS( datArr, labelArr, 30 )
1.0
2.0
0.1
-1
0.9
aggClassEst: [[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]]
total Error: 0.0
adaClassify( [ 0 , 0 ] , classifierArr)
[[-0.69314718]]
[[-1.66610226]]
[[-2.56198199]]
matrix([[-1.]])
def loadDataSet ( fileName) :
numFeat = len ( open ( fileName) . readline( ) . split( '\t' ) )
dataMat = [ ] ; labelMat = [ ]
fr = open ( fileName)
for line in fr. readlines( ) :
lineArr = [ ]
curLine = line. strip( ) . split( '\t' )
for i in range ( numFeat - 1 ) :
lineArr. append( float ( curLine[ i] ) )
dataMat. append( lineArr)
labelMat. append( float ( curLine[ - 1 ] ) )
return dataMat, labelMat
datArr, labelArr = loadDataSet( 'horseColicTraining2.txt' )
classifierArray = adaBoostTrainDS( datArr, labelArr, 10 )
testArr, testLabelArr = loadDataSet( 'horseColicTest2.txt' )
prediction10 = adaClassify( testArr, classifierArray)
errArr = mat( ones( ( 67 , 1 ) ) )
su = errArr[ prediction10 != mat( testLabelArr) . T] . sum ( )
print ( su)
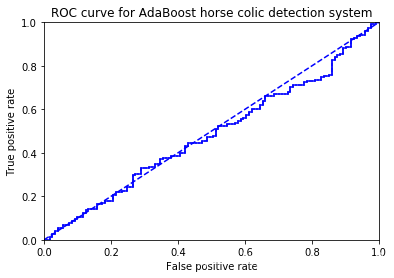
# ROC曲线绘制
def plotROC(predStrengths, classLabels):# 预测强度向量,样本标签
import matplotlib.pyplot as plt # 导入库
cur = (1.0,1.0) #cursor
ySum = 0.0 #variable to calculate AUC
numPosClas = sum(array(classLabels)==1.0)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
#draw line from cur to (cur[0]-delX,cur[1]-delY)
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show()
print("the Area Under the Curve is: ",ySum*xStep)
dataArr, labelArr = loadDataSet("horseColicTraining.txt")
classifierArray,aggClassEst = adaBoostTrainDS(dataArr, labelArr,10)
plotROC(aggClassEst.T,labelArr)







 本文介绍了AdaBoost的学习流程,包括数据收集、准备、分析和训练。重点讲解了如何基于单层决策树构建弱分类器,并提供了完整的AdaBoost算法伪代码,涵盖训练过程和分类函数。此外,还提及了ROC曲线的绘制和AUC计算。
本文介绍了AdaBoost的学习流程,包括数据收集、准备、分析和训练。重点讲解了如何基于单层决策树构建弱分类器,并提供了完整的AdaBoost算法伪代码,涵盖训练过程和分类函数。此外,还提及了ROC曲线的绘制和AUC计算。

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









