



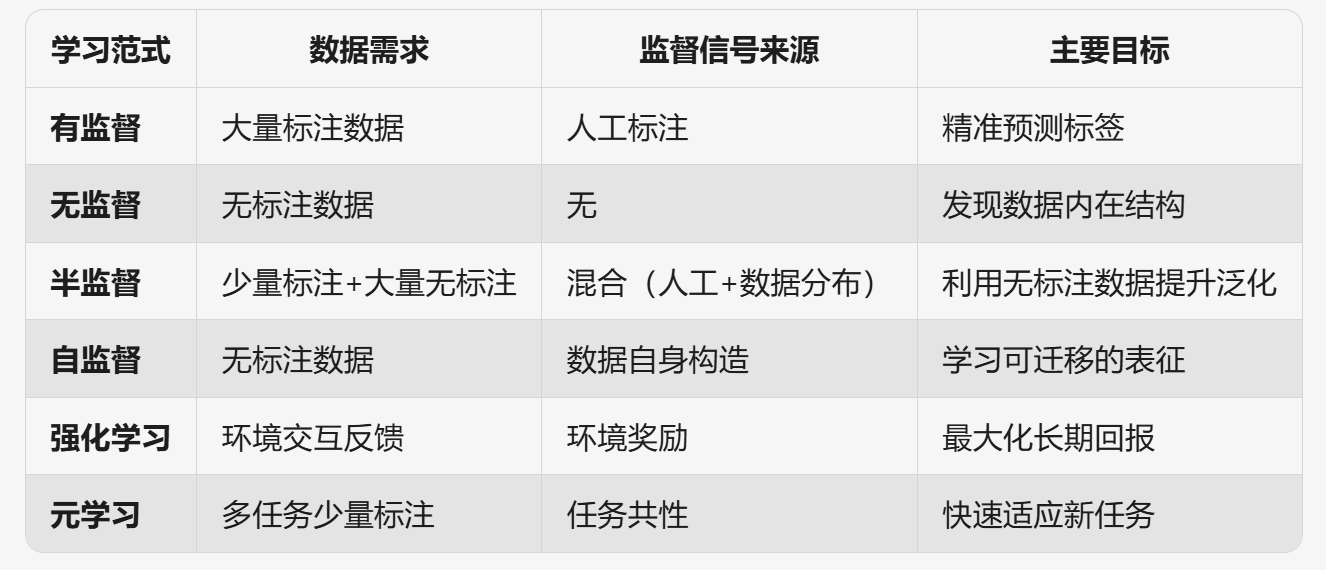
在机器学习领域,不同的学习范式具有各自独特的特点和应用场景。
强化学习的核心在于智能体通过与环境的交互来学习最优策略。它不依赖预先标注的数据,而是通过试错机制获取反馈信号(如奖励或惩罚),并以此调整行为以最大化长期累积回报。这种方法特别适用于需要序列决策的任务,例如机器人控制、游戏AI或自动驾驶,其中动态调整策略是关键。
元学习则关注“学会如何学习”,旨在训练模型快速适应新任务,尤其是在数据稀缺的情况下。它通过在多任务环境中学习共性知识,使模型在面对新问题时能够基于少量样本高效调整参数。这种能力使其在小样本分类或跨领域迁移任务(如医疗诊断)中表现出色。
有监督学习是最经典的范式,依赖大量标注数据来训练模型。其目标是学习输入特征与输出标签之间的映射关系,从而对新数据进行预测。无论是分类(如图像识别)还是回归(如房价预测),有监督学习在需要高精度预测的场景中占据主导地位。
无监督学习则无需任何标注数据,专注于挖掘数据的内在结构。通过聚类、降维或生成模型,它可以发现隐藏的模式或异常点,常用于客户细分、推荐系统或数据预处理。
半监督学习介于有监督和无监督之间,利用少量标注数据和大量无标注数据共同训练模型。其核心思想是通过无标注数据的分布信息增强模型的泛化能力,适用于标注成本高昂的领域,如医学影像分析或文本分类。
自监督学习通过设计辅助任务从无标注数据中自动生成监督信号。例如,在自然语言处理中,模型通过预测被遮蔽的词语来学习语言表征;在计算机视觉中,对比学习框架通过区分相似与不相似的图像来提取特征。这种范式在预训练模型中广泛应用(如BERT或MoCo),为下游任务提供强大的迁移学习基础。
下图进行了总结:

















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









