






0. 摘要
本文介绍了哈夫曼编码的原理及其在信息编码中的应用。通过分析和实现,展示了如何构建哈夫曼树和生成哈夫曼编码,同时计算编码的效率指标。
1. 引言
信息编码是信息技术中的核心问题之一,而哈夫曼编码作为一种无损数据压缩技术,被广泛应用于数据传输和存储中。本文将深入探讨哈夫曼编码的基本原理及其实现方式,并通过具体案例展示其应用和效果。
2. 哈夫曼编码的原理
2.1 基本概念
哈夫曼编码是一种可变长度编码,通过根据字符出现频率不同而分配不同长度的编码来实现数据压缩。频率高的字符使用较短的编码,频率低的字符使用较长的编码,以此来减少总体编码长度。
2.2 构建哈夫曼树
哈夫曼树是基于字符频率构建的二叉树,通过最小堆实现。频率越高的字符越接近根部,频率越低的字符越靠近叶子节点。
算法步骤
- 将所有字符视为单独的树节点,根据频率构建最小堆。
- 反复从堆中取出两个频率最小的节点,创建一个新的父节点作为它们的父节点,将其频率设置为子节点频率之和。
- 将新的父节点重新插入堆中,直到堆中只剩下一个节点为止,这个节点即为哈夫曼树的根节点。
2.3 生成哈夫曼编码
通过递归遍历哈夫曼树,从根节点到每个叶子节点,分配编码。左子树赋值为0,右子树赋值为1,最终得到每个字符的哈夫曼编码。
3. 代码实现与分析
本文使用 C++ 语言实现了哈夫曼编码的生成和编码效率计算。以下是关键代码片段:
3.1 结构定义和比较器
// 定义树节点结构
struct Node {
char ch;
double prob;
Node* left, * right;
Node(char ch, double prob) : ch(ch), prob(prob), left(nullptr), right(nullptr) {}
};
// 比较节点概率以创建最小堆的比较器
struct compare {
bool operator()(Node* left, Node* right)
{
return left->prob > right->prob; // 最小堆:按概率从小到大排序
}
};3.2 哈夫曼编码生成
// 递归地存储每个字符的哈夫曼编码
void storeCodes(struct Node* root, std::string str, std::unordered_map<char, std::string>& huffmanCode)
{
if (root == nullptr)
return;
if (!root->left && !root->right)
{
huffmanCode[root->ch] = str; // 叶子节点存储字符及其编码
}
// 左子树编码为0,右子树编码为1
storeCodes(root->left, str + "0", huffmanCode);
storeCodes(root->right, str + "1", huffmanCode);
}3.3 构建哈夫曼树
// 构建哈夫曼树并返回根节点
Node* buildHuffmanTree(char data[], double prob[], int size)
{
struct Node* left, * right, * top;
// 创建优先队列(最小堆),用于存储节点并按照概率排序
std::priority_queue<Node*, std::vector<Node*>, compare> minHeap;
// 初始化队列,将每个字符作为独立节点插入堆中
for (int i = 0; i < size; ++i)
{
minHeap.push(new Node(data[i], prob[i]));
}
// 构建哈夫曼树的过程
while (minHeap.size() != 1)
{
// 从堆中提取两个最小概率的节点作为左右子节点
left = minHeap.top();
minHeap.pop();
right = minHeap.top();
minHeap.pop();
// 创建一个新的内部节点,其字符为'$',概率为左右子节点概率之和
top = new Node('$', left->prob + right->prob);
top->left = left; // 将原来的最小概率节点作为新节点的左子树
top->right = right; // 将次小概率节点作为新节点的右子树
minHeap.push(top); // 将新节点插入堆中
}
return minHeap.top(); // 返回堆顶,即哈夫曼树的根节点
}3.4 哈夫曼编码和树的打印
// 打印哈夫曼树,用于调试和可视化
void printTree(Node* root, std::string indent = "", bool isLast = true)
{
if (root != nullptr)
{
std::cout << indent;
if (isLast)
{
std::cout << "R----"; // 右子树
indent += " ";
}
else
{
std::cout << "L----"; // 左子树
indent += "| ";
}
std::cout << root->ch << "(" << root->prob << ")" << std::endl; // 打印节点字符和概率
printTree(root->left, indent, false); // 递归打印左子树
printTree(root->right, indent, true); // 递归打印右子树
}
}3.5 输出哈夫曼编码,平均编码长度和编码效率计算
(1) 平均编码长度:平均编码长度是指每个字符的编码长度乘以其出现概率的总和
其中,Pi 是第 i 个字符的出现概率,Li是第 i 个字符的编码长度。
(2) 编码效率:编码效率是指信息熵与平均编码长度的比值。信息熵 H 的公式如下:
(3)编码效率 η 的公式如下:
// 生成哈夫曼编码并计算编码效率
void HuffmanCodes(Node* root, const std::vector<char>& chars, const std::vector<double>& probs)
{
// 存储每个字符的哈夫曼编码
std::unordered_map<char, std::string> huffmanCode;
storeCodes(root, "", huffmanCode);
// 输出每个字符的哈夫曼编码
std::cout << "哈夫曼编码为:\n";
for (auto pair : huffmanCode)
{
std::cout << pair.first << ": " << pair.second << "\n";
}
// 输出哈夫曼树结构
std::cout << "\n哈夫曼树为:\n";
printTree(root);
// 计算平均编码长度和信息熵
double avgLength = 0.0;
double entropy = 0.0;
for (size_t i = 0; i < chars.size(); ++i) {
avgLength += probs[i] * huffmanCode[chars[i]].length(); // 计算加权平均编码长度
entropy -= probs[i] * std::log2(probs[i]); // 计算信息熵
}
double efficiency = entropy / avgLength; // 计算编码效率
// 输出平均编码长度和编码效率
std::cout << "\n平均编码长度: " << avgLength << "\n";
std::cout << "编码效率: " << efficiency << "\n";
}
3.6 主函数逻辑实现
// 测试哈夫曼编码函数
int main() {
std::string inputChars, inputProbs;
// 输入字符及其概率
std::cout << "请输入字符(用空格分隔): ";
std::getline(std::cin, inputChars);
std::cout << "请输入对应的概率(用空格分隔): ";
std::getline(std::cin, inputProbs);
// 解析输入,分别存储字符和概率
std::vector<char> chars;
std::istringstream charStream(inputChars);
char ch;
while (charStream >> ch)
{
chars.push_back(ch);
}
std::vector<double> probs;
std::istringstream probStream(inputProbs);
double prob;
while (probStream >> prob)
{
probs.push_back(prob);
}
// 检查输入的字符和概率是否匹配
if (chars.size() != probs.size())
{
std::cerr << "字符和概率的数量不匹配!" << std::endl;
return 1;
}
// 构建哈夫曼树并生成编码
Node* root = buildHuffmanTree(chars.data(), probs.data(), chars.size());
HuffmanCodes(root, chars, probs);
return 0;
}3.7 代码运行结果
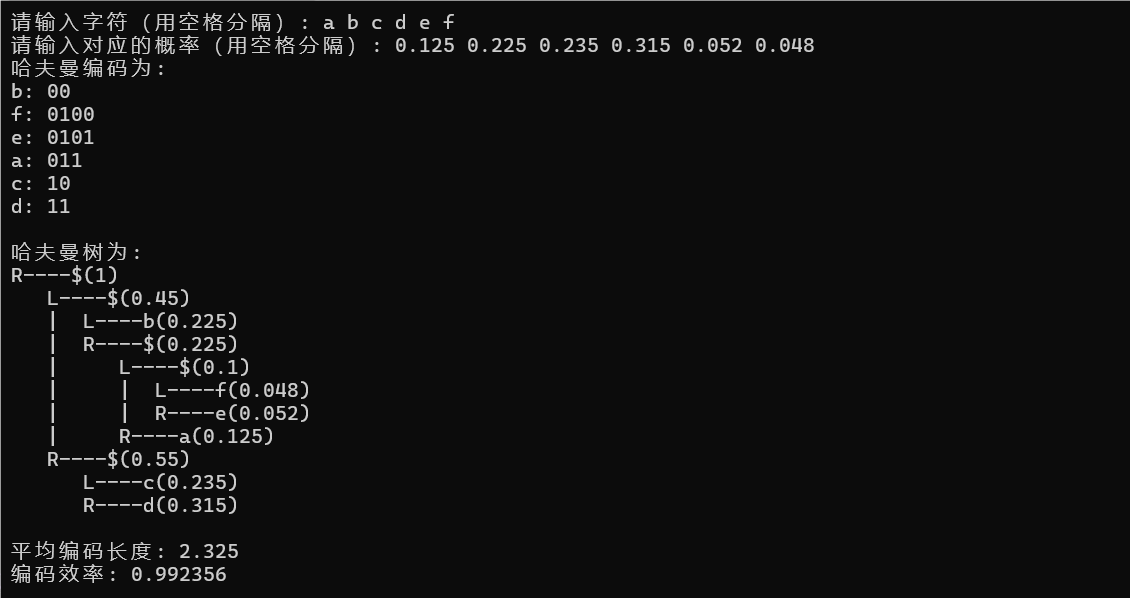
4. 总结
-
哈夫曼编码原理:
- 基本思想: 使用变长编码表示不同字符,使得出现频率高的字符具有较短的编码,从而减少总体编码长度。
- 优势: 哈夫曼编码能够根据字符出现的频率,生成最优的编码方案,使得平均编码长度接近信息熵,从而实现最佳的数据压缩效果。在数据传输和存储中,哈夫曼编码可以有效减少数据量,节省带宽和存储空间,提高数据传输效率和速度。哈夫曼编码的算法相对简单,通过优先队列的使用可以高效地构建编码树,并生成编码。
-
代码实现功能:
- 构建哈夫曼树: 使用优先队列构建最小堆,通过合并两个最小概率的节点构建哈夫曼树。
- 生成编码: 递归地存储每个字符的哈夫曼编码,并输出到控制台。
- 打印哈夫曼树: 以可视化形式打印出构建的哈夫曼树结构。
- 计算编码效率: 计算平均编码长度和信息熵,进而计算编码效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









