







目录
当Python无法多线程:深入探讨GIL的影响
如果你曾经听说过Python在多线程方面表现不佳,原因在于Python的全局解释器锁(Global Interpreter Lock,简称GIL)。随着计算机核心速度的增长不再像过去那样快,现代计算机通常通过增加多个CPU核心来弥补,允许多个线程并行运行计算。即使没有多个核心,你也可以实现并发,例如一个线程在等待磁盘操作时,另一个线程可以在CPU上运行代码。使用并行能力对于扩展应用程序或加速数据处理至关重要。
不幸的是,在许多情况下,由于Python的全局解释器锁(GIL),你的代码一次只能运行一个线程。 其他时候,它可以很好地运行多个线程——这完全取决于具体的使用模式。
但哪些使用模式允许并行,哪些不允许呢? 简单的思维模型会给你不准确的答案。因此,在本文中,你将构建一个关于GIL如何工作的实用思维模型:
- 我们将从一系列逐渐更准确的GIL工作原理的思维模型开始。
- 然后,我们将看到这个新的、更准确的思维模型如何帮助你预测并行性瓶颈会在哪里出现。
什么时候Python线程需要持有GIL?
GIL是CPython解释器的一个实现细节,它是一个线程锁:任何时候只有一个线程可以持有这个锁。因此,要理解GIL如何影响Python在多线程中并行运行代码的能力,我们需要回答一个关键问题:什么时候Python线程需要持有GIL?
为了理解这一点,我们将构建一系列逐渐更准确的GIL工作原理的思维模型。
模型1:一次只能有一个线程运行Python代码
考虑以下代码;它在两个线程中运行go()函数:
import threading
import time
def go():
start = time.time()
while time.time() < start + 0.5:
sum(range(10000))
def main():
threading.Thread(target=go).start()
time.sleep(0.1)
go()
main()
当我们使用Sciagraph性能分析器运行它时,执行时间线如下:
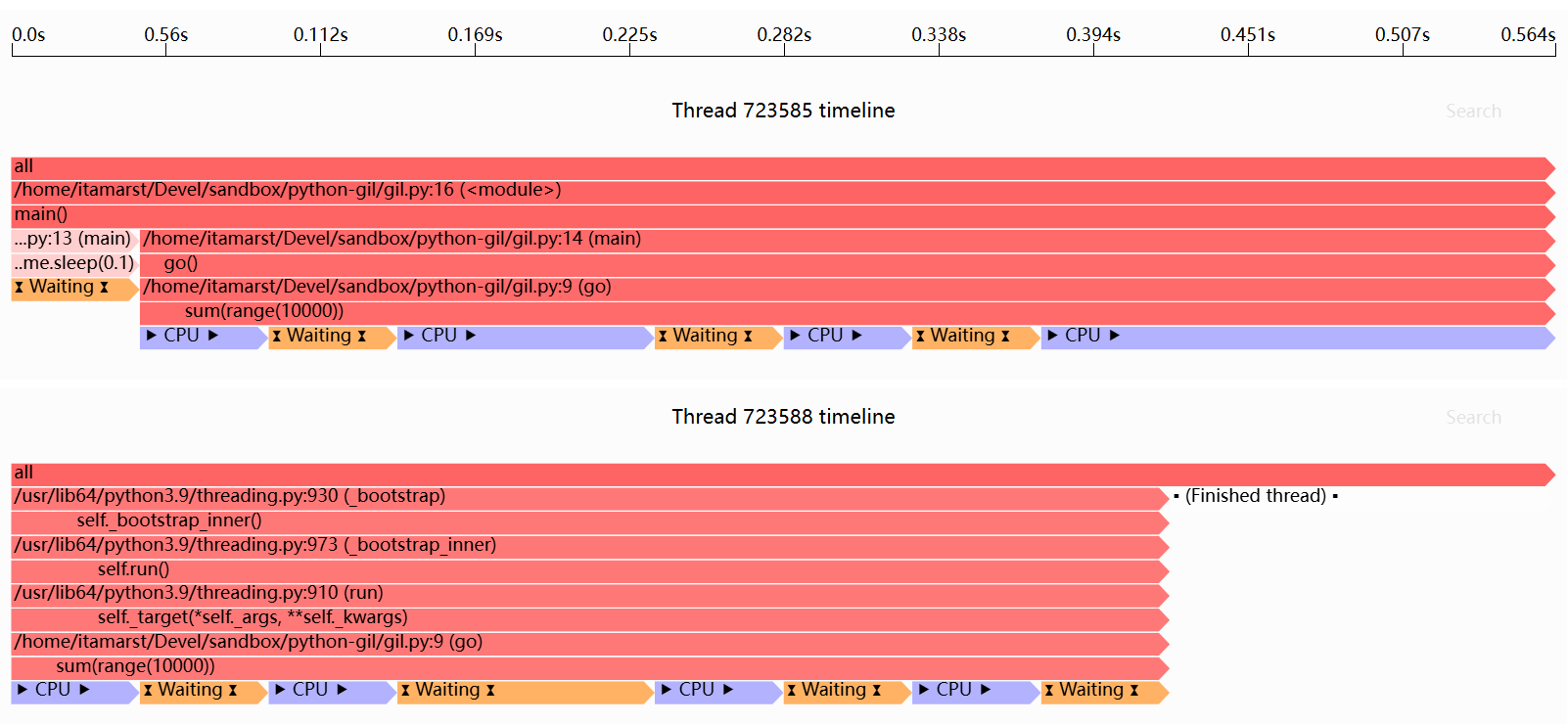
注意线程如何在等待和运行之间切换:运行的代码持有GIL,等待的线程正在等待GIL。
如果GIL在5ms(或其他可配置的间隔)内没有被释放,Python会告诉当前运行的线程释放GIL。然后,下一个线程可以运行。在两个线程的情况下,我们看到它在来回切换;实际显示的间隔比5ms长,因为这是一个采样分析器,大约每47ms采样一次。
所以这是我们的初始思维模型:
- 线程必须持有GIL才能运行Python代码。
- 其他线程无法获取GIL,因此无法运行,直到当前运行的线程释放它,这每5ms自动发生一次。
模型2:每5ms释放GIL并不是保证的
在Python 3.7到3.10中,GIL默认每5ms释放一次(未来可能会改变),允许其他线程运行:
>>> import sys
>>> sys.getswitchinterval()
0.005
但这种GIL释放是尽力而为的,并不是保证的。考虑一个伪代码的简单解释器循环;Python的实现有所不同,但原理相同:
while True:
if time_to_release_gil():
temporarily_release_gil()
run_next_python_instruction()
只要run_next_python_instruction()没有完成,temporarily_release_gil()就不会被调用。大多数情况下,这不会发生,因为单个操作(如两个整数相加、向列表追加等)很快完成。因此,解释器可以频繁检查是否该释放GIL。
也就是说,长时间运行的操作可能会阻止GIL自动释放。让我们编写一个小的Cython扩展,这是一个类似Python的语言,编译为C。它调用标准C库中的sleep()函数:
cdef extern from "unistd.h":
unsigned int sleep(unsigned int seconds)
def c_sleep(unsigned int seconds):
sleep(seconds)
我们可以使用Cython附带的cythonize工具将其编译为可导入的Python扩展:
$ cythonize -i c_sleep.pyx
...
$ ls c_sleep*.so
c_sleep.cpython-39-x86_64-linux-gnu.so
我们将从一个Python程序中调用它,该程序尝试在一个线程中并行调用c_sleep(),同时在主线程中进行CPU计算:
import threading
import time
from c_sleep import c_sleep
def thread():
c_sleep(2)
threading.Thread(target=thread).start()
start = time.time()
while time.time() < start + 2:
sum(range(10000))
以下是Sciagraph性能分析器的运行输出:
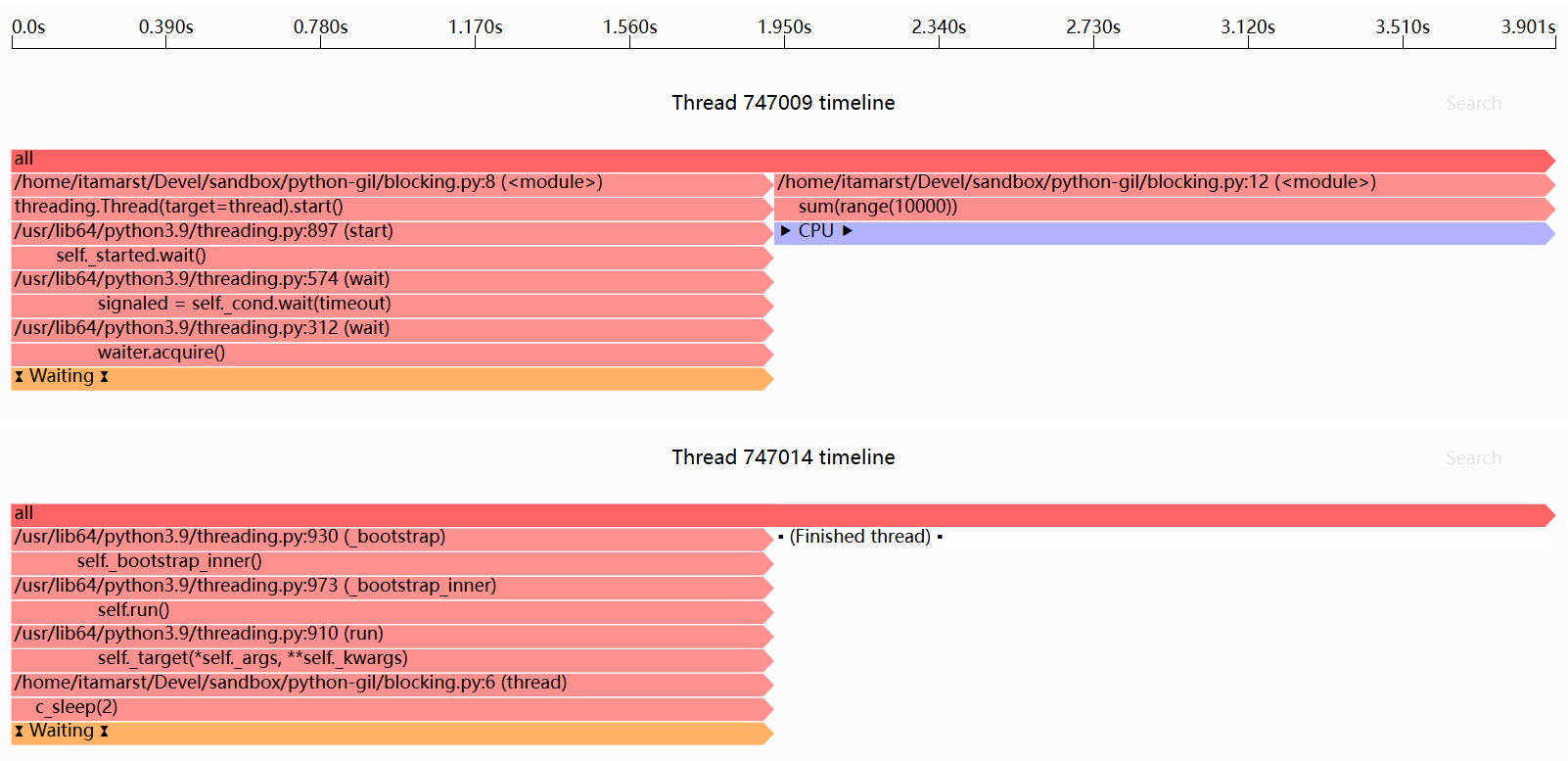
主线程在睡眠线程完成之前无法运行;似乎睡眠线程根本没有释放GIL。这是因为c_sleep(2)调用在2秒内不会返回。在这2秒内,Python解释器循环没有运行,因此不会检查是否应该自动释放GIL。
这是我们的更新思维模型:
- Python线程必须持有GIL才能运行代码。
- 其他Python线程无法获取GIL,因此无法运行,直到当前运行的线程释放它,这每5ms自动发生一次。
- 长时间运行的(“阻塞”)扩展代码会阻止自动切换。
模型3:非Python代码可以显式释放GIL
如果我们运行time.sleep(3),它将在3秒内什么都不做。我们上面看到,长时间运行的扩展代码可能会阻止GIL在线程之间自动切换。那么这是否意味着其他线程不能在time.sleep()的同时运行呢?
让我们尝试以下代码,它尝试在主线程中并行运行一个3秒的睡眠和一个5秒的计算:
import threading
from time import time, sleep
program_start = time()
def thread():
sleep(3)
print("Sleep thread done, elapsed:", time() - program_start)
threading.Thread(target=thread).start()
# 在主线程中进行5秒计算:
calc_start = time()
while time() < calc_start + 5:
sum(range(10000))
print("Main thread done, elapsed:", time() - program_start)
如果我们运行它,会看到:
$ time python gil2.py
Sleep thread done, elapsed: 3.0081260204315186
Main thread done, elapsed: 5.000330924987793
real 0m5.068s
user 0m4.977s
sys 0m0.011s
如果只有一个线程在运行,我们预计程序需要8秒,3秒用于睡眠,5秒用于计算。这意味着睡眠线程和主线程是并行运行的!
以下是Sciagraph性能分析器的输出:
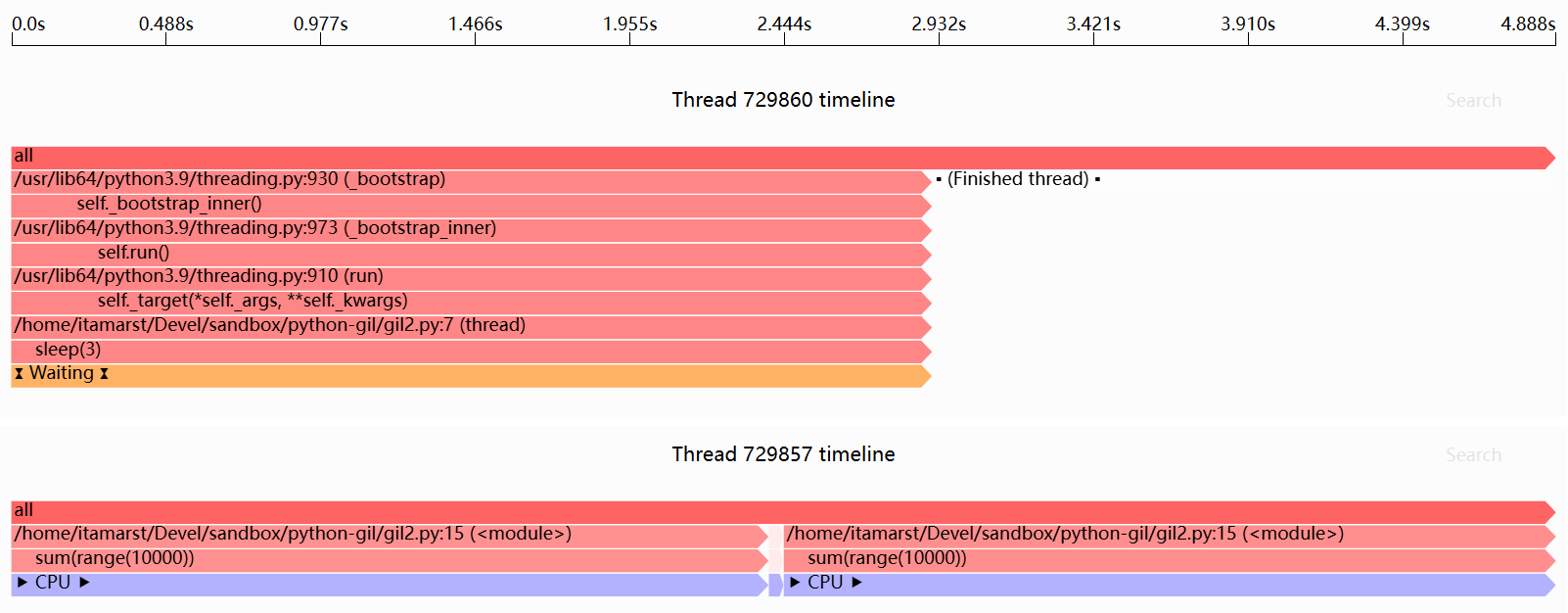
如果我们深入研究time.sleep的实现,我们可以看到发生了什么:
int ret;
Py_BEGIN_ALLOW_THREADS
#ifdef HAVE_CLOCK_NANOSLEEP
ret = clock_nanosleep(CLOCK_MONOTONIC, TIMER_ABSTIME, &timeout_abs, NULL);
err = ret;
#elif defined(HAVE_NANOSLEEP)
ret = nanosleep(&timeout_ts, NULL);
err = errno;
#else
ret = select(0, (fd_set *)0, (fd_set *)0, (fd_set *)0, &timeout_tv);
err = errno;
#endif
Py_END_ALLOW_THREADS
如果我们查看PY_BEGIN/END_ALLOW_THREADS的文档,我们会发现这是释放GIL的一种方式。C实现显式释放了GIL,同时调用了底层操作系统的睡眠函数。这是另一种释放GIL的方式,与我们之前看到的每5ms自动切换不同。
任何已经释放GIL并且不试图获取它的代码——在这种情况下是睡眠期间——不会阻塞其他想要GIL的线程。因此,我们可以并行运行任意数量的线程,只要它们显式释放GIL。
所以这是我们的新思维模型:
- 线程必须持有GIL才能运行Python代码。
- 其他线程无法获取GIL,因此无法运行,直到当前运行的线程释放它,这每5ms自动发生一次。
- 长时间运行的(“阻塞”)扩展代码会阻止自动切换。
- 用C(或其他低级语言)编写的Python扩展可以显式释放GIL,允许一个或多个线程与持有GIL的线程并行运行。
模型4:调用Python C API需要GIL
到目前为止,我们已经说过C代码在某些情况下能够释放GIL,但我们还没有说什么时候。由于GIL需要保护对CPython解释器内部实现细节的访问,答案大致是:每当调用CPython C API时,你必须持有GIL。
例如,假设你想使用C(或Rust,或Cython)构造一个Python dict对象。如果你查看创建字典的CPython C API,你会看到你将使用像PyDict_New和PyDict_SetItem这样的函数。如果你在写C代码,你会直接调用它们;在Rust和Cython的情况下,PyO3库或生成的代码最终会调用这些API。
几乎每个CPython C API都要求调用线程持有GIL,只有少数例外。
所以这是我们的最终思维模型:
- 线程必须持有GIL才能调用CPython C API。
- 在解释器中运行的Python代码,如
x = f(1, 2),使用这些API。每个==比较、每个整数加法、每个list.append:都是对Python C API的调用。因此,运行Python代码的线程在运行时必须持有锁。 - 其他线程无法获取GIL,因此无法运行,直到当前运行的线程释放它,这每5ms自动发生一次。
- 长时间运行的(“阻塞”)扩展代码会阻止自动切换。
- 用C(或其他低级语言)编写的Python扩展可以显式释放GIL,允许一个或多个线程与持有GIL的线程并行运行。
GIL的并行性影响
那么这一切如何影响Python在多线程中并行运行代码的能力呢?这取决于你考虑的代码类型。
好的场景:长时间运行的C API释放GIL
并行性的最佳情况是长时间运行的C/C++/Rust等代码,大部分时间不使用CPython C API。它可以释放GIL并允许其他线程运行。但即使在这里,也有一些限制需要注意。
例如,考虑一个用C或Rust编写的扩展模块,允许你与PostgreSQL数据库服务器通信。
从概念上讲,使用这个库处理SQL查询将经历三个步骤:
- 从Python反序列化到库的内部表示。由于这将读取Python对象,因此需要持有GIL。
- 将查询发送到数据库服务器,并等待响应。这不需要GIL。
- 将响应转换为Python对象。这需要GIL。
如你所见,你能获得多少并行性取决于每个步骤花费的时间。如果大部分时间花在步骤2上,你将在那里获得并行性。但是,如果你运行一个SELECT并返回大量行,库将需要创建许多Python对象,步骤3将不得不长时间持有GIL。
坏场景1:“纯”Python代码
“纯”Python代码,与内置的Python对象(如字典、整数、列表等)交互,并且没有调用阻塞的低级代码,将不断使用Python C API:
l = []
for i in range(i):
l.append(i * i)
因此,你不会获得任何并行性。但你将看到线程每5ms左右切换一次,因此至少所有线程都会取得进展。
坏场景2:长时间运行的C/Rust API,但作者忘记释放GIL
即使有可能释放GIL,低级C/Rust/Cython等库的作者可能忘记这样做。在这种情况下,你将不会获得任何并行性。更糟糕的是,如果代码运行时间超过5ms,你也不会获得自动切换,因此其他线程不会取得任何进展。
如果你怀疑这是一个问题,例如基于分析输出,你可以通过以下方式识别这些问题:
- 使用
gil_load工具来确定GIL是否真的是瓶颈。 - 阅读扩展的源代码,寻找缺少GIL释放的地方,或使用《追踪Python GIL》文章中描述的技术。
坏场景3:广泛使用Python C API的低级代码
另一个你不会获得太多并行性的情况是C/Rust扩展中广泛使用Python C API。例如,考虑一个读取以下字符串的JSON解析器:
[1, 2, 3]
解析器将:
- 读取几个字节,然后创建一个Python列表。
- 然后读取更多字节,然后创建一个Python整数并将其附加到列表中。
- 继续直到数据用完。
创建所有这些Python对象需要使用CPython C API,因此需要持有GIL。反复打开和关闭GIL,或按某种计划打开和关闭,会有性能成本,而且大多数JSON文档可以非常快速地解析。鉴于上述情况,JSON解析器的作者自然选择从不释放GIL。
让我们通过观察Python内置的JSON解析器在两个线程中读取两个大文档时如何影响并行性来验证这一假设。以下是代码:
import json
import threading
def load_json():
with open("large.json") as f:
return json.load(f)
threading.Thread(target=load_json).start()
load_json()
以下是执行时间线:
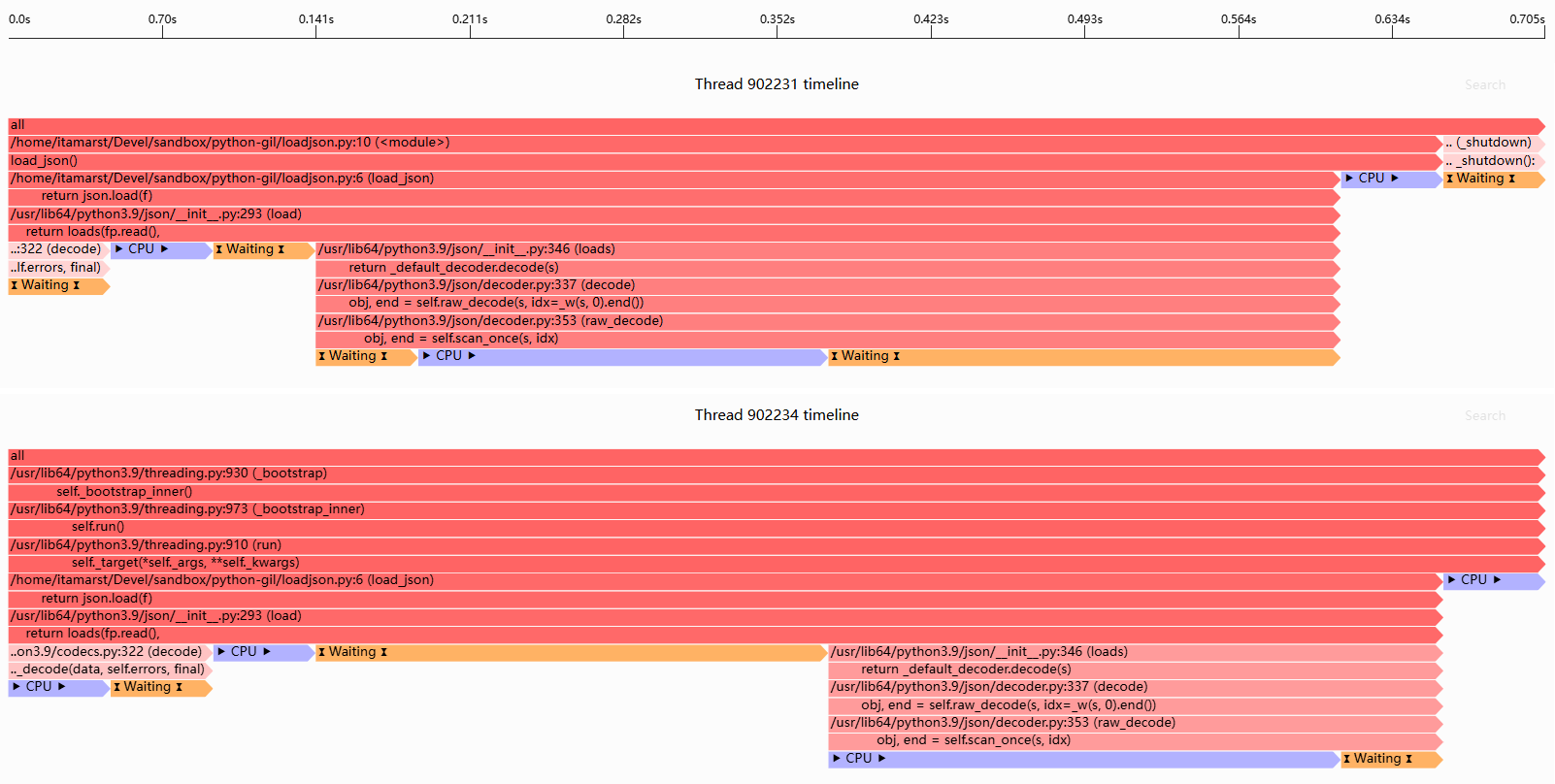
遗憾的是,没有并行性:两个JSON加载基本上没有(也不能)并行运行。
避免GIL
正如你在上面的示例场景中所看到的,即使在可以释放GIL的情况下,当你需要与Python对象交互时,你仍然会遇到并行性限制。如果你将SQL响应转换为Python对象,大量响应意味着在没有并行性的情况下花费大量时间。如果这成为瓶颈,一个选择是切换到多进程。
或者,如果你正在编写自己的Python低级扩展,你可以采用像NumPy和Pandas这样的库中的设计模式。尽可能使用不由Python对象组成的内部数据表示。
NumPy的整数数组与包含Python整数的Python列表非常不同;它是一种更高效的表示,不需要使用Python C API,更不用说使用更少的内存。通过最小化与Python对象的交互,并且只暴露一个Python对象(例如NumPy数组),GIL可以尽可能长时间地释放。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











