







CRF简介
CRF++是著名的条件随机场的开源工具,也是目前综合性能最佳的CRF工具。
CRF 的工具有两种,一种是支持Linux环境的,一种是支持Windows环境的,大家可以自行根据自己的系统进行下载。(在此我下载的是CRF++ -0.58)
linu的安装应该简单些,几行命令就能搞定,而windows下其实严格来讲不能说是安装。我们解压我们下载的压缩包文件到某一个目录下面即可。CRF同时也提供了python接口,可以通过接口直接加载模型,自定义函数,我这里目前是windows的环境,暂且先用命令行。
CRF解压后的包:
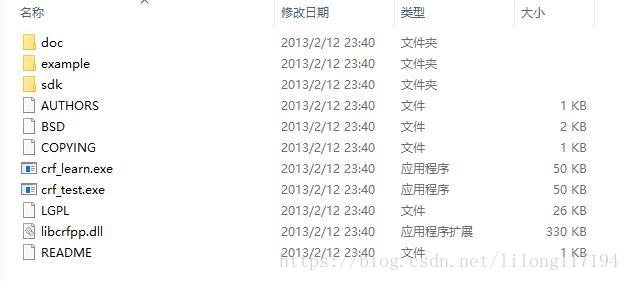
这里很有必要对几个目录介绍下:
- doc文件夹:官方主页的内容
- example文件夹:有四个数据包,每个数据包有四个文件:
训练数据(test.data)、测试数据(train.data)、模板文件(template)、执行脚本文件exec.sh。 - sdk文件夹:CRF++的头文件和静态链接库。
- clr_learn.exe:CRF++的训练程序
- crl_test.exe:CRF++的测试程序
- libcrffpp.dll:训练程序和测试程序需要使用的静态链接库。
实际上,需要使用的就是crf_learn.exe,crf_test.exe和libcrfpp.dll,这三个文件。
这里直接使用CRF自带的例子进行试验一下:
在example中的某个例子做一下测试。例如:example中chunking文件夹,其中原有4个文件:exec.sh;template;test.data;train.data。将crf_learn.exe;crf_test.exe;libcrfpp.dll三个文件复制到这个文件夹(chunking)底下。
然后使用命令行cd到chunking目录下,这里我用的是 Anaconda prompt 的命令行:
(base) C:\Users\LiLong>cd C:\CRF++-0.58\example\chunking
模型训练:
在命令窗口中,cd到该文件夹后,然后输入以下命令进行训练模型。
模板:crf_learn template_file train_file model_file
输入如下:
(base) C:\CRF++-0.58\example\chunking>crf_learn template train.data model
你可以看到控制台上打印处的信息,并会产生一个新的文件:model。
CRF++: Yet Another CRF Tool Kit
Copyright (C) 2005-2013 Taku Kudo, All rights reserved.
reading training data:
Done!0.03 s
Number of sentences: 77
Number of features: 153482
Number of thread(s): 4
Freq: 1
eta: 0.00010
C: 1.00000
shrinking size: 20
iter=0 terr=0.98629 serr=1.00000 act=153482 obj=5003.65270 diff=1.00000
iter=1 terr=0.38449 serr=1.00000 act=153482 obj=4082.64911 diff=0.18407
iter=2 terr=0.38449 serr=1.00000 act=153482 obj=1974.35839 diff=0.51640
iter=3 terr=0.19937 serr=0.93506 act=153482 obj=1323.56081 diff=0.32962
iter=4 terr=0.14030 serr=0.92208 act=153482 obj=826.22783 diff=0.37575
iter=5 terr=0.08333 serr=0.71429 act=153482 obj=573.51229 diff=0.30587
iter=6 terr=0.03692 serr=0.44156 act=153482 obj=388.80427 diff=0.32206
iter=7 terr=0.01266 serr=0.20779 act=153482 obj=310.94172 diff=0.20026
iter=8 terr=0.00158 serr=0.03896 act=153482 obj=285.42807 diff=0.08205
iter=9 terr=0.00105 serr=0.02597 act=153482 obj=273.98088 diff=0.04011
iter=10 terr=0.00000 serr=0.00000 act=153482 obj=266.16068 diff=0.02854
iter=11 terr=0.00000 serr=0.00000 act=153482 obj=260.00330 diff=0.02313
...
...
iter=26 terr=0.00000 serr=0.00000 act=153482 obj=253.78214 diff=0.00004
iter=27 terr=0.00000 serr=0.00000 act=153482 obj=253.77759 diff=0.00002
Done!1.02 s
首先说下输出参数的意思:
- iter:迭代次数。当前迭代次数达到maxiter时,迭代终止。
- terr:标记错误率
- serr:句子错误率
- obj:当前对象的值。当这个值收敛到一个确定的值的时候,训练完成。
- diff:与上一个对象之间的相对差。当此值低于eta时,训练完成。
这个训练过程的时间、迭代次数等信息就会输出到控制台上,如果想要保存这些信息到一个文件里,命令格式模板:
crf_learn template_file train_file model_file >> train_info_file
例如:crf_learn template train.data model >> model_out.txt
这时chunking文件夹下就会多一个model_out.txt文件,而文件里存储的就是上面控制平台输出的内容。
在模型训练和测试中的命令参数是以下的形式:
crf_learn -f 3 -p 8 -c 3 template train.data model
其中主要的参数有以下几个:
- -a -algorithm=CRF-L2 or CRF-L1
规范化算法的选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。 - -f -freq=NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少出现NUM次的特征。默认值为1。当使用CRF++到大规模数据的时候,只出现一次的特征可能会有百万个,这个选项就会在这样的情况下起作用了。 - -p -thread=NUM
如果电脑有多个CPU ,那么可以通过多线程提升训练速度。NUM是线程数量。 - -c -cost=float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。 - -m -maxiter=int
设置最大的迭代次数(默认为10k) - -e -eta=float
设置终止标准(默认为0.0001)
模型测试:
输入命令进行测试数据,测试程序的命令为:
模板:crf_test -m model_file test_file
eg: crf_test -m model test.data
同上,也可以把输出结果导入到一个文件里保存起来。
预测参数有两个-v 和-n,都是用来显示一些信息的。
-v :可以用来预测标签概率值
-n:可以显示不同可能序列的概率值
训练语料库格式:
训练语料至少应该具有两列,列间由空格或者制表位间隔,且所有行(空行除外)必须具有相同的列,句子间使用空行间隔。
特征选取及模板的编写:
特征选取的行是相对的,列数绝对的,一般选取相对行前后m行,选取n-1列(假设语料总共有n列),特征表示方法为:%x[行,列],行列的初始位置都为0。
这里可采用的模板是:
# Unigram
U00:%x[-1,0]
U01:%x[0,0]
U02:%x[1,0]
U03:%x[2,0]
U04:%x[-2,0]
U05:%x[1,0]/%x[2,0]
U06:%x[0,0]/%x[-1,0]/%x[-2,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]U10:%x[-1,0]/%x[1,0]

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









