



研究背景
- 研究问题:这篇文章要解决的问题是如何从稀疏多视图视频中联合学习动态神经辐射场(NeRF)和相关骨骼模型,以实现高质量的新视角合成和可重定位的3D重建。
- 研究难点:该问题的研究难点包括:反向变形场的逆映射问题、现有动态模型的视觉保真度低、重建时间长以及应用域狭窄。
- 相关工作:该问题的研究相关工作有:动态NeRF模型、对象重定位技术、基于点云的神经表示等。具体来说,动态NeRF模型通过时间编码或时间依赖插值来捕捉场景的时间变化;对象重定位技术通常依赖于参数模板或几何部件的集合;基于点云的神经表示结合了神经功能和显式几何的灵活性。
研究方法
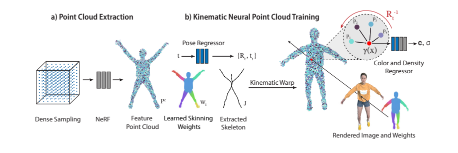
这篇论文提出了一种基于点云和线性混合蒙皮(LBS)的前向变形方法,用于解决动态对象的NeRF学习和重定位问题。具体来说
- 初始特征点云提取:首先,使用TiNeuVox模型预训练一个骨干网络,并在一个选定的规范时间点采样特征点云P={pi∣i=1,…,N}P={pi∣i=1,…,N},并提取每个点的特征向量fi。
-
骨骼模型初始化:不依赖于特定类别的模板,而是通过中轴变换(MAT)提取初始骨骼树,并在训练过程中进行优化。
-
混合蒙皮权重初始化:每个点的初始蒙皮权重向量w^iw^i通过距离到每条骨骼线的指数衰减函数初始化,并通过全局可学习参数α进行缩放和应用softmax函数得到最终的混合蒙皮权重向量wiwi。
-
点云前向变形:通过LBS将规范点云Pc前向变形到观测空间的时间戳t,每个骨骼的局部变换矩阵T^btT^bt由其父关节的旋转RbtRbt定义,点picpic通过骨骼变换的线性组合进行变形:
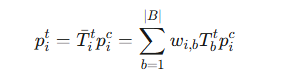
- 动态点云渲染:采用点云渲染方法,并扩展其以显式建模辐射场的旋转不变性。对于每个采样点x,找到最多8个最近的观测特征点pitpit,并将它们旋转平移到其规范框架中,通过特征嵌入MLPΦpΦp学习姿态不变的坐标框架中的空间关系。
- 损失函数:除了光度损失LphotoLphoto外,还使用了2D chamfer损失来惩罚投影到训练视图的点云与相应的2D地面真实对象掩码之间的差异LmaskLmask,以及最小化骨骼从中轴M发散过多的chamfer损失LskelLskel、变换角度和根平移LtranfLtranf、局部刚度正则化LarapLarap、混合蒙皮权重的平滑度损失LsmoothLsmooth和稀疏度损失LsparseLsparse。
实验设计
- 数据集选择:选择了三个常用的多视图视频数据集进行评估,包括Robots数据集、Blender数据集和ZJU-MoCap数据集。
-
实现细节:使用PyTorch实现该方法,并在多个GPU上进行了训练。具体来说,TiNeuVox骨干网络使用作者的实现和一个额外的失真损失进行预训练,神经点云使用Adam优化器训练160k(Blender和Robots)或320k(ZJU-MoCap)迭代,批量大小为8192射线。
-
对比方法:与现有的非关节和关节方法进行对比,包括D-NeRF、TiNeuVox-B、Hexplane、K-Planes、WIM等方法。
结果与分析
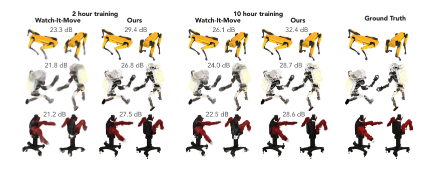
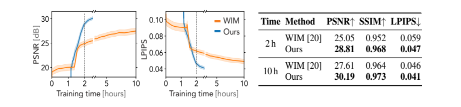
- 新视角合成质量:在Robots数据集上,该方法在2.5小时内达到了与WIM方法在10小时内相当的质量水平。在Blender数据集上,该方法的平均图像得分在2小时训练后超过了WIM方法在10小时后的得分。
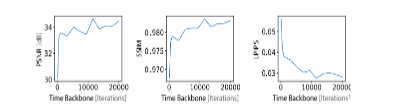
- 重定位能力:该方法能够在没有对象特定模板的情况下实现可重定位的3D重建,并且在ZJU-MoCap数据集上能够恢复3D形状和骨骼运动。

- 组件贡献分析:通过消融实验分析了各个损失函数的贡献,发现平滑度损失LsmoothLsmooth和改进的部分分割、骨骼正则化LskelLskel、变换正则化LtranfLtranf和稀疏度损失LsparseLsparse在不同场景下的效果。

优点与创新
- 提出了一种新颖的方法,利用点云表示和线性混合蒙皮(LBS)联合学习动态NeRF及其相关的骨骼模型,从稀疏多视图视频中学习。
- 前向变形方法在合成新视图和姿态时实现了最先进的视觉保真度,同时显著减少了与现有工作相比所需的学习时间。
- 在多种关节物体上展示了表示的多样性,并在不需要对象特定骨骼模板的情况下获得了可复用的3D重建。
- 通过自动提取和联合优化的LBS骨骼姿态参数化,实现了更快的训练和更高的图像合成质量。
- 提供了轻松重新定位学习表示的方法,通过直接编辑前向LBS模型的关节角度来实现。

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









