




 该项目使用Python实现BiliBili漫画的多线程下载,每话漫画导出为PDF,并能合并为Kindle兼容格式。详细分析了漫画详情获取与单集漫画下载的步骤,通过分析网络请求获取所需数据。提供了GitHub链接以供查看完整代码。
该项目使用Python实现BiliBili漫画的多线程下载,每话漫画导出为PDF,并能合并为Kindle兼容格式。详细分析了漫画详情获取与单集漫画下载的步骤,通过分析网络请求获取所需数据。提供了GitHub链接以供查看完整代码。
本项目实现了以下功能
- 多线程下载漫画
- 每一话导出PDF
- 合并PDF 并加入Kindle能解析的标签
GitHub链接: GitHub传送门
下面开始分析环节
1. 漫画详情获取
要下载漫画,首先需要获取全部章节
打开漫画详情页,可以看到漫画详情URL由这几部分构成
https://manga.bilibili.com/detail/mc25493
无用部分 [ https://manga.bilibili.com/detail/ ] 漫画ID [ mc25493 ]因此,在bilibili漫画中,漫画ID用于标识漫画
下一步就是获取全部章节,打开浏览器网络调试,由于bilibili漫画是前后端分离的结构,所以请求类别里面选XHR。

我们在请求列表里可以看到一个 “ComicDetail“ 的请求,点开发现这个请求的epi_list中包含了每一集漫画的”id“,和更多信息。我们现在即可获取每一集的名字,是否购买等方便进一步开发的信息。
2. 下载每一集漫画
获取到漫画ID后,我们可以进行下载,首先打开漫画阅读界面,再开网络调试,选XHR
一个叫做 ’GetImageIndex‘的请求可以引起我们的注意。
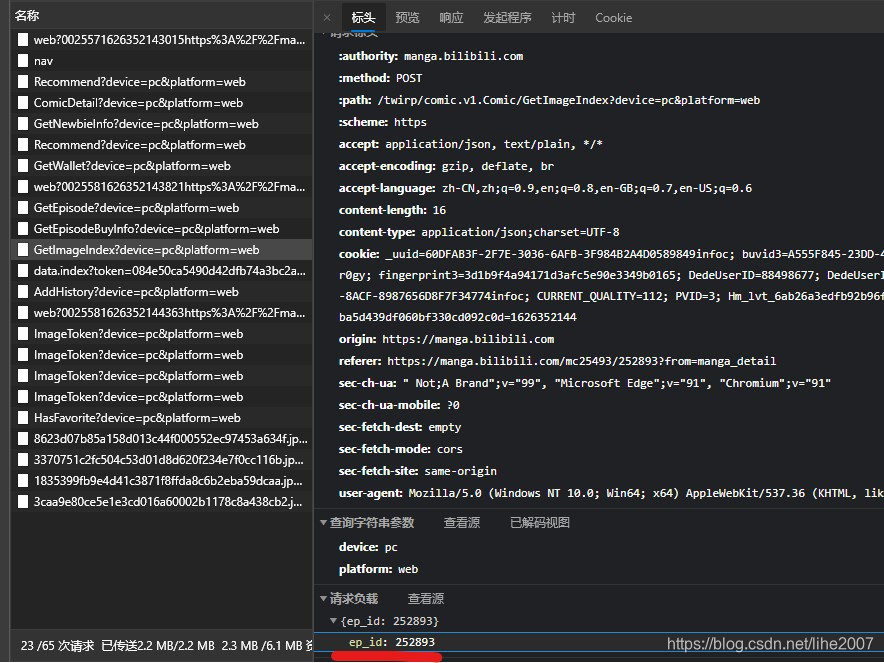
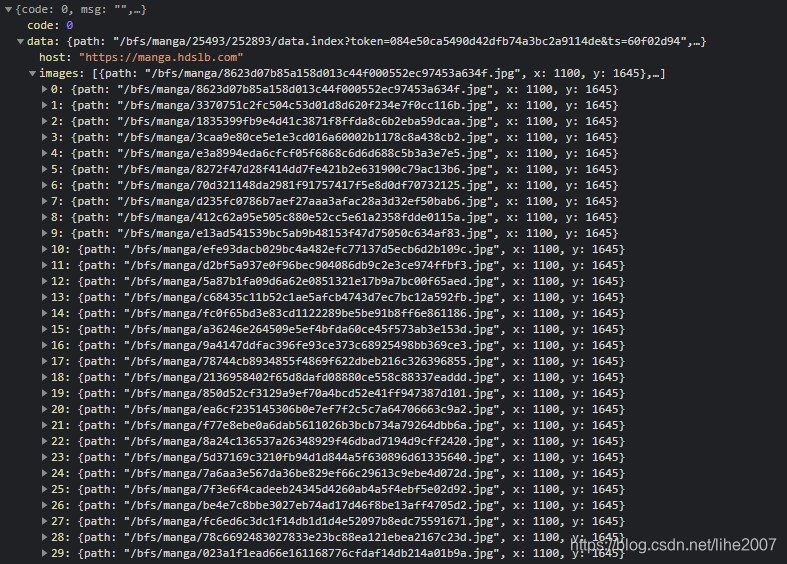
这个请求接受ep_id 也就是这一集的id,返回每一张图片的url,通过这个api,我们可以轻易下载每一张图片,再加入多线程下载,即可实现批量下载啦!
如果喜欢这个程序,就点个star吧!


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









