







然后我们再来看一下,我们使用LlamaIndex来做一个完整的项目:
基于LlamaIndex实现一个完整的RAG系统.
## 8、基于 LlamaIndex 实现一个功能较完整的 RAG 系统
功能要求:
- 加载指定目录的文件
- 支持 RAG-Fusion
- 使用 Qdrant 向量数据库,并持久化到本地
- 支持检索后排序
- 支持多轮对话
<div class="alert alert-danger">
以下代码不要在服务器上运行,会死机!可下载左侧 rag_demo.py 在自己本地运行。
</div>
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
EMBEDDING_DIM = 512
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"
client = QdrantClient(path=PATH)
这里我们使用的是Qdrant这个向量数据库,然后当我们指定一个./qdrant_db这个目录以后
他会把数据持久化到硬盘上.
当然我们也可以指定使用

chromadb这个向量数据库.
from llama_index.core import VectorStoreIndex, KeywordTableIndex, SimpleDirectoryReader
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.readers.file import PyMuPDFReader
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import SentenceTransformerRerank
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
import time
# 1. 指定全局llm与embedding模型
# 这里指定了使用gpt-4o模型,然后同时指定了使用text-embedding-3-small向量化模型,
#然后指定了生成的向量要是512维度的EMBEDDING_DIM是上面定义的.
Settings.llm = OpenAI(temperature=0, model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBEDDING_DIM)
# 2. 指定全局文档处理的 Ingestion Pipeline
#然后我们使用Ingestion Pipeline来进行灌库之前的文档处理,这里
#SentenceSplitter还是用这个来进行切分,300字符一个段,并且100溢出用来判断切分自动调节边界
Settings.transformations = [SentenceSplitter(chunk_size=300, chunk_overlap=100)]
# 3. 加载本地文档
#然后再来去加载文档,这里指定了pdf文件使用,PyMuPDFReader这个加载器来加载,其他的
#文件使用默认加载器加载.
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data()
#这里判断使用Qdrant向量数据库,检测一下有没有一个叫COLLECTION_NAME的集合如果有,先删除
#删除以后后面再去创建.
if client.collection_exists(collection_name=COLLECTION_NAME):
client.delete_collection(collection_name=COLLECTION_NAME)
# 4. 创建 collection
#去创建Qdrant的集合,然后指定向量化维度512维,然后向量空间计算距离用COSINE距离
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)
# 5. 创建 Vector Store
#然后就可以去灌库了.
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)
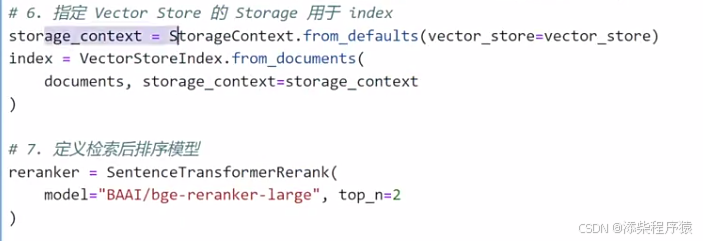
# 6. 指定 Vector Store 的 Storage 用于 index
#灌库以后,然后再来获取查询用的索引.
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
# 7. 定义检索后排序模型
#然后经过上面的操作,文档就灌入向量库了,然后再对查询结果进行后排序.
#这里定义一下后排序,使用的模型BAAI/bge-reranker-large,以及获取前两个结果
reranker = SentenceTransformerRerank(
model="BAAI/bge-reranker-large", top_n=2
)
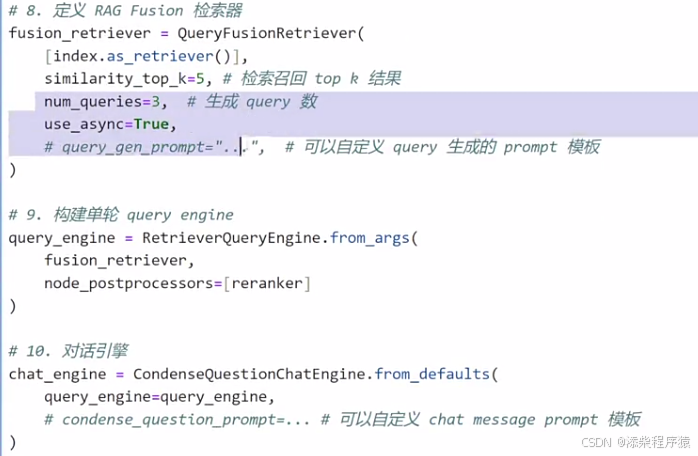
# 8. 定义 RAG Fusion 检索器
#然后再去定义检索器,这里使用RAG Fusion也就是,它可以把我们的检索,一个检索分成多个
#去检索,然后把检索结果,再进行合起来
fusion_retriever = QueryFusionRetriever(
[index.as_retriever()],
similarity_top_k=5, # 检索召回 top k 结果
num_queries=3, # 生成 query 数
use_async=False,
# query_gen_prompt="...",
# 可以自定义 query 生成的 prompt 模板 ,这里可以定义拆分检索的模板,
#让他根据我们的规则去拆分检索
)
# 然后去构建单轮对话.
# 9. 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever, #指定了大模型查询器
node_postprocessors=[reranker] #然后指定后处理,查询后的处理,就是上面定义的ranker
)
# 10. 对话引擎
# 多轮对话引擎,其实里面套了一个单轮对话引擎.
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
# condense_question_prompt=... # 可以自定义 chat message prompt 模板
)
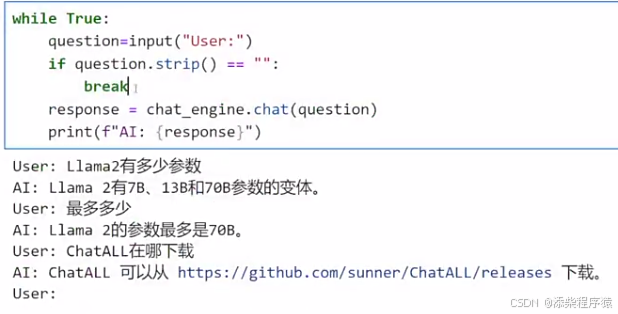
while True:
question=input("User:")
if question.strip() == "":
break
response = chat_engine.chat(question)
print(f"AI: {response}")
然后就可以写代码去测试了
可以看到其实就是,用户输入,然后使用chat_engine上面定义的多轮对话引擎去回答就可以了.

可以看到执行后就可以进行正常使用了.
## LlamaIndex 的更多功能
- 智能体(Agent)开发框架:https://docs.llamaindex.ai/en/stable/module_guides/deploying/agents/
- RAG 的评测:https://docs.llamaindex.ai/en/stable/module_guides/evaluating/
- 过程监控:https://docs.llamaindex.ai/en/stable/module_guides/observability/
以上内容涉及较多背景知识,暂时不在本课展开,相关知识会在后面课程中逐一详细讲解。
此外,LlamaIndex 针对生产级的 RAG 系统中遇到的各个方面的细节问题,
总结了很多高端技巧([Advanced Topics](https://docs.llamaindex.ai/en/stable/optimizing/production_rag/)),
对实战很有参考价值,非常推荐有能力的同学阅读。
另外LlamaIndex还支持智能体开发框架,RAG评测框架,还有过程监控工具也有,
需要的话可以自己去查阅文档.
另外对于RAG开发中遇到的一些,比较复杂的问题,比如如果解析表格等等,
以上地址,有很多人碰到,并提出了解决方案,可以去查阅.
下面这个是一份比较完整的代码:
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.readers.file import PyMuPDFReader
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.core.postprocessor import SentenceTransformerRerank
from llama_index.core.retrievers import QueryFusionRetriever
# from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import CondenseQuestionChatEngine
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
import time
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
EMBEDDING_DIM = 512
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"
# 创建 Qdrant 向量数据库,并持久化到本地
client = QdrantClient(path=PATH)
# 指定全局llm与embedding模型
Settings.llm = OpenAI(temperature=0, model="gpt-4o")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=EMBEDDING_DIM)
splitter = SentenceSplitter(chunk_size=300, chunk_overlap=100)
# 加载 pdf 文档
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data()
# 切分nodes
nodes = splitter.get_nodes_from_documents(documents)
if client.collection_exists(collection_name=COLLECTION_NAME):
client.delete_collection(collection_name=COLLECTION_NAME)
# 新建 collection
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)
# 创建 Vector Store
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)
# 指定 Vector Store 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes, storage_context=storage_context
)
# 使用混合检索
# bm25_retriever = BM25Retriever.from_defaults(nodes=nodes)
# 检索后排序模型
reranker = SentenceTransformerRerank(
model="BAAI/bge-reranker-large", top_n=2
)
# RAG Fusion
fusion_retriever = QueryFusionRetriever(
[
index.as_retriever(),
# bm25_retriever # 使用混合检索
],
similarity_top_k=5,
num_queries=3, # 生成 query 数
use_async=False,
# query_gen_prompt="...", # 可以自定义 query 生成的 prompt 模板
)
# 构建单轮 query engine
query_engine = RetrieverQueryEngine.from_args(
fusion_retriever,
node_postprocessors=[reranker]
)
# 对话引擎
chat_engine = CondenseQuestionChatEngine.from_defaults(
query_engine=query_engine,
# condense_question_prompt=... # 可以自定义 chat message prompt 模板
)
while True:
question=input("User:")
if question.strip() == "":
break
response = chat_engine.chat(question)
print(f"AI: {response}")
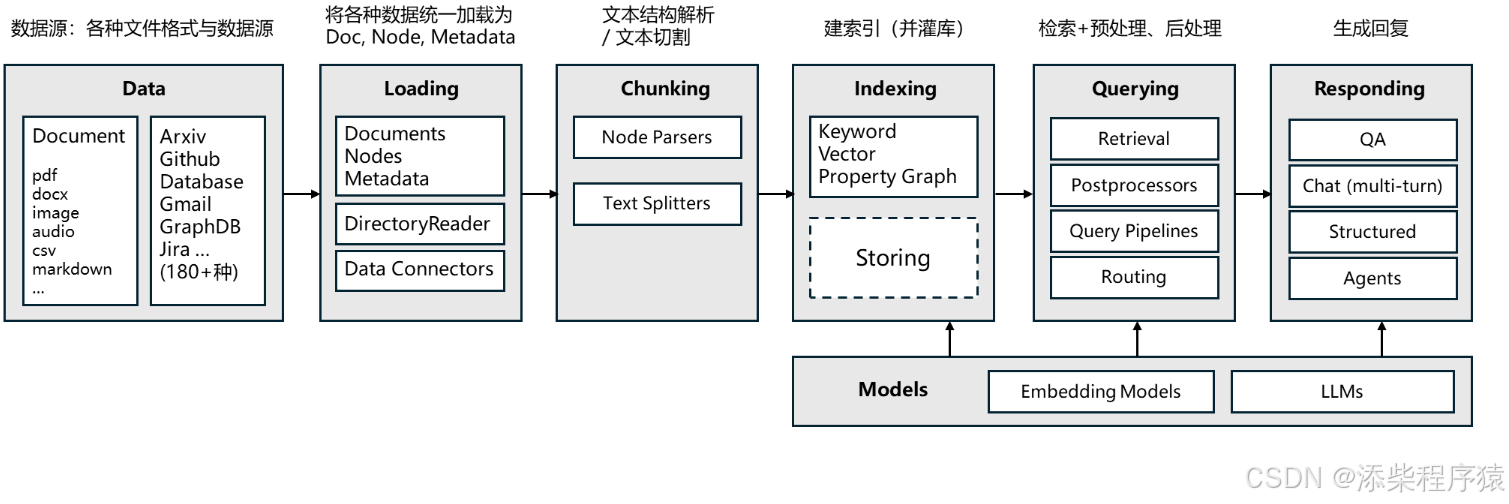
这个是LlamaIndex的大模型开发框架的一个架构图.
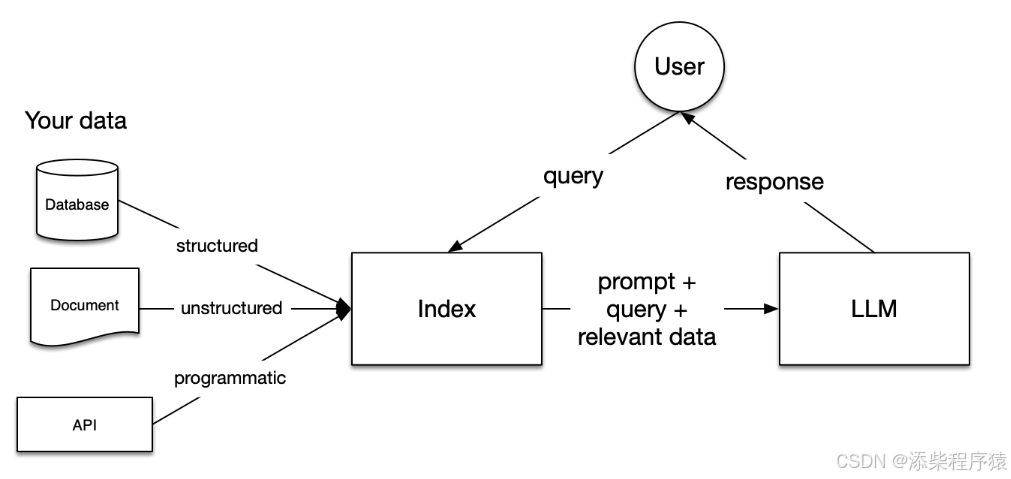
这个是RAG开发的架构图.
aiohappyeyeballs==2.4.0
aiohttp==3.10.5
aiosignal==1.3.1
annotated-types==0.7.0
anyio==4.4.0
asgiref==3.8.1
attrs==24.2.0
backoff==2.2.1
bcrypt==4.2.0
beautifulsoup4==4.12.3
build==1.2.1
cachetools==5.5.0
certifi==2024.7.4
charset-normalizer==3.3.2
chroma-hnswlib==0.7.6
chromadb==0.5.5
click==8.1.7
coloredlogs==15.0.1
dataclasses-json==0.6.7
Deprecated==1.2.14
dirtyjson==1.0.8
distro==1.9.0
fastapi==0.112.2
filelock==3.15.4
flatbuffers==24.3.25
frozenlist==1.4.1
fsspec==2024.6.1
google-auth==2.34.0
googleapis-common-protos==1.63.2
greenlet==3.0.3
grpcio==1.66.0
h11==0.14.0
httpcore==1.0.5
httptools==0.6.1
httpx==0.27.0
huggingface-hub==0.24.6
humanfriendly==10.0
idna==3.8
importlib_metadata==8.0.0
importlib_resources==6.4.4
Jinja2==3.1.4
jiter==0.5.0
joblib==1.4.2
kubernetes==30.1.0
llama-cloud==0.0.15
llama-index==0.11.1
llama-index-agent-openai==0.3.0
llama-index-cli==0.3.0
llama-index-core==0.11.1
llama-index-embeddings-openai==0.2.3
llama-index-indices-managed-llama-cloud==0.3.0
llama-index-legacy==0.9.48.post3
llama-index-llms-openai==0.2.0
llama-index-multi-modal-llms-openai==0.2.0
llama-index-program-openai==0.2.0
llama-index-question-gen-openai==0.2.0
llama-index-readers-file==0.2.0
llama-index-readers-llama-parse==0.2.0
llama-index-vector-stores-chroma==0.2.0
llama-parse==0.5.0
markdown-it-py==3.0.0
MarkupSafe==2.1.5
marshmallow==3.22.0
mdurl==0.1.2
mmh3==4.1.0
monotonic==1.6
mpmath==1.3.0
multidict==6.0.5
mypy-extensions==1.0.0
nest-asyncio==1.6.0
networkx==3.3
nltk==3.9.1
numpy==1.26.4
oauthlib==3.2.2
onnxruntime==1.19.0
openai==1.42.0
opentelemetry-api==1.26.0
opentelemetry-exporter-otlp-proto-common==1.26.0
opentelemetry-exporter-otlp-proto-grpc==1.26.0
opentelemetry-instrumentation==0.47b0
opentelemetry-instrumentation-asgi==0.47b0
opentelemetry-instrumentation-fastapi==0.47b0
opentelemetry-proto==1.26.0
opentelemetry-sdk==1.26.0
opentelemetry-semantic-conventions==0.47b0
opentelemetry-util-http==0.47b0
orjson==3.10.7
overrides==7.7.0
packaging==24.1
pandas==2.2.2
pillow==10.4.0
posthog==3.5.2
protobuf==4.25.4
pyasn1==0.6.0
pyasn1_modules==0.4.0
pydantic==2.8.2
pydantic_core==2.20.1
Pygments==2.18.0
PyMuPDF==1.24.9
PyMuPDFb==1.24.9
pypdf==4.3.1
PyPika==0.48.9
pyproject_hooks==1.1.0
python-dateutil==2.9.0.post0
python-dotenv==1.0.1
pytz==2024.1
PyYAML==6.0.2
regex==2024.7.24
requests==2.32.3
requests-oauthlib==2.0.0
rich==13.7.1
rsa==4.9
safetensors==0.4.4
scikit-learn==1.5.1
scipy==1.14.1
sentence-transformers==3.0.1
shellingham==1.5.4
six==1.16.0
sniffio==1.3.1
soupsieve==2.6
SQLAlchemy==2.0.32
starlette==0.38.2
striprtf==0.0.26
sympy==1.13.2
tenacity==8.5.0
threadpoolctl==3.5.0
tiktoken==0.7.0
tokenizers==0.19.1
torch==2.4.0
tqdm==4.66.5
transformers==4.44.2
typer==0.12.5
typing-inspect==0.9.0
typing_extensions==4.12.2
tzdata==2024.1
urllib3==2.2.2
uvicorn==0.30.6
uvloop==0.20.0
watchfiles==0.23.0
websocket-client==1.8.0
websockets==13.0
wrapt==1.16.0
yarl==1.9.4
zipp==3.20.0
这个是requirements.txt 是开发中使用的各个工具的版本.
另外如果要使用chromaDB向量数据库,来做一个RAG系统的话可以下面这样,其实跟使用
Qdrant向量数据库,其实是差不多的.





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











