







然后我们再来看一下我们使用LlamaIndex框架进行开发了RAG以后
我们可以看一下步骤:
1.对文档进行处理比如切分.
2.然后将切分后的结果,存入到向量数据库
3.然后再对向量数据库中的文档进行检索。
在检索之后,我们还可以做一些处理,比如说对检索的结果进行排序。为什么要这样做,
是因为在检索之后,有可能有些我们想要的结果没有排在我们拿到的Top几之内。
比如我们指定了要结果的top2,但是实际上准确的结果在第3个中.
### 5.4、检索后处理
LlamaIndex 的 `Node Postprocessors` 提供了一系列检索后处理模块。
例如:我们可以用不同模型对检索后的 `Nodes` 做重排序
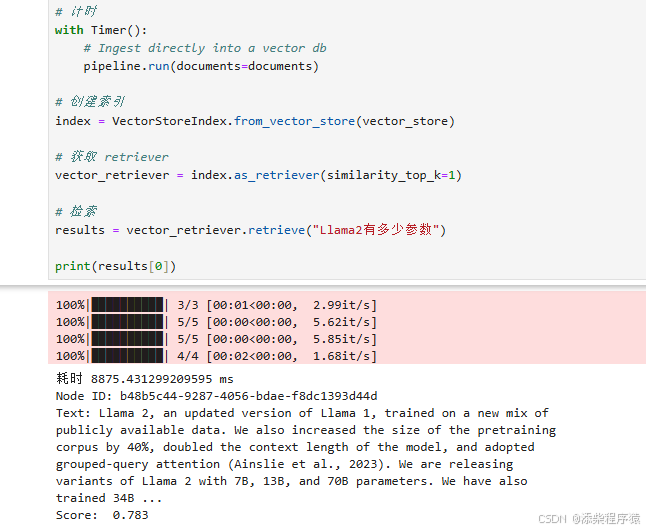
# 获取 retriever
vector_retriever = index.as_retriever(similarity_top_k=5)
# 检索
nodes = vector_retriever.retrieve("Llama2 有商用许可吗?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}\n")
比如我们接着之前的代码。拿到检索器。然后进行检索。并且打印出所有的结果。
上面我们指定了获取Top5。
[0] Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also
increased the size of the pretraining corpus by 40%, doubled the context length of the model, and
adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with
7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper
but are not releasing.§
2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021;
Solaiman et al., 2023).
[1] We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021;
Solaiman et al., 2023). Testing conducted to date has been in English and has not — and could not — cover
all scenarios. Therefore, before deploying any applications of Llama 2-Chat, developers should perform
safety testing and tuning tailored to their specific applications of the model. We provide a responsible use
guide¶ and code examples‖ to facilitate the safe deployment of Llama 2 and Llama 2-Chat. More details of
our responsible release strategy can be found in Section 5.3.
[2] Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich
Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra
Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi
Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang
Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang
Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic
Sergey Edunov
Thomas Scialom∗
GenAI, Meta
Abstract
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned
large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.
Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases.
[3] These closed product LLMs are heavily fine-tuned to align with human
preferences, which greatly enhances their usability and safety. This step can require significant costs in
compute and human annotation, and is often not transparent or easily reproducible, limiting progress within
the community to advance AI alignment research.
In this work, we develop and release Llama 2, a family of pretrained and fine-tuned LLMs, Llama 2 and
Llama 2-Chat, at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested,
Llama 2-Chat models generally perform better than existing open-source models. They also appear to
be on par with some of the closed-source models, at least on the human evaluations we performed (see
Figures 1 and 3). We have taken measures to increase the safety of these models, using safety-specific data
annotation and tuning, as well as conducting red-teaming and employing iterative evaluations. Additionally,
this paper contributes a thorough description of our fine-tuning methodology and approach to improving
LLM safety.
[4] Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed-
source models. Human raters judged model generations for safety violations across ~2,000 adversarial
prompts consisting of both single and multi-turn prompts. More details can be found in Section 4.4. It is
important to caveat these safety results with the inherent bias of LLM evaluations due to limitations of the
prompt set, subjectivity of the review guidelines, and subjectivity of individual raters. Additionally, these
safety evaluations are performed using content standards that are likely to be biased towards the Llama
2-Chat models.
We are releasing the following models to the general public for research and commercial use‡:
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also
increased the size of the pretraining corpus by 40%, doubled the context length of the model, and
adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with
7B, 13B, and 70B parameters.
可以看到正确的结果,实际上是在第3段中:
Llama 2 and Llama 2-Chat, at scales up to 70B parameters
那么这个时候如果我们去Top2的话,实际上就取不到了。
这个时候我们就需要对结果进行重排。也就是把相似度更高的结果排在最前面。
这个时候我们就用到了LlamaIndex 的 `Node Postprocessors` 提供了一系列检索后处理模块。
from llama_index.core.postprocessor import SentenceTransformerRerank
# 检索后排序模型
postprocessor = SentenceTransformerRerank(
model="BAAI/bge-reranker-large", top_n=2
)
nodes = postprocessor.postprocess_nodes(nodes, query_str="Llama2 有商用许可吗?")
for i, node in enumerate(nodes):
print(f"[{i}] {node.text}")
可以看到它的用法,实际上就是。在这个postprocessor 包中,导入需要用到的SentenceTransformerRerank检索后重排序的模块
然后这里是加载了一个模型,然后通过模型进行的重新排序。这一次获取的是top2
[0] Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed-
source models. Human raters judged model generations for safety violations across ~2,000 adversarial
prompts consisting of both single and multi-turn prompts. More details can be found in Section 4.4. It is
important to caveat these safety results with the inherent bias of LLM evaluations due to limitations of the
prompt set, subjectivity of the review guidelines, and subjectivity of individual raters. Additionally, these
safety evaluations are performed using content standards that are likely to be biased towards the Llama
2-Chat models.
We are releasing the following models to the general public for research and commercial use‡:
1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also
increased the size of the pretraining corpus by 40%, doubled the context length of the model, and
adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with
7B, 13B, and 70B parameters.
[1] Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also
increased the size of the pretraining corpus by 40%, doubled the context length of the model, and
adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with
7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper
but are not releasing.§
2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021;
Solaiman et al., 2023).
这个时候我们再去看结果,可以看到正确的结果已经被排在了第2个结果中。
更多的 Rerank 及其它后处理方法,参考官方文档:[Node Postprocessor Modules](https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/node_postprocessors/)
当然咱们的LlamaIndex还为我们提供了很多其他的检索以后,再去处理结果的方法,具体的可以参考官方文档。
然后我们再来看LlamaIndex对生成回复的封装。
## 6、生成回复(QA & Chat)
### 6.1、单轮问答(Query Engine)
qa_engine = index.as_query_engine()
response = qa_engine.query("Llama2 有多少参数?")
print(response)
Llama 2有7B, 13B, 和70B参数。
可以看到首先对单轮式的回答。
可以看到,其实就是用索引获取到查询引擎,然后直接去对查询引擎进行提问就可以了。
#### 流式输出
qa_engine = index.as_query_engine(streaming=True)
response = qa_engine.query("Llama2 有多少参数?")
response.print_response_stream()
Llama 2有7B, 13B, 和70B参数。
6.2、多轮对话(Chat Engine)
chat_engine = index.as_chat_engine()
response = chat_engine.chat("Llama2 有多少参数?")
print(response)
response = chat_engine.chat("How many at most?")
print(response)
Llama2 最多有70B参数。
当然也可以进行流式的输出。
可以看到上面的代码,这个时候需要添加一个参数就是 streaming=true
可以看到获取到response以后。 print_response_stream 就可以流式的输出结果了.
然后还可以进行多轮对话。可以看到多轮对话的时候直接调用。
index.as_chat_engine() 这里是chat_engine 而单轮对话这里是:index.as_query_engine()
#### 流式输出
chat_engine = index.as_chat_engine()
streaming_response = chat_engine.stream_chat("Llama 2有多少参数?")
# streaming_response.print_response_stream()
for token in streaming_response.response_gen:
print(token, end="", flush=True)
可以看到,在多轮对话中也可以进行流式输出。
然后我们再来看下一个知识点。
LlamaIndex其实也可以对比较底层的,比如说Prompt,LLM以及Embedding模型进行自定义。
## 7、底层接口:Prompt、LLM 与 Embedding
### 7.1、Prompt 模板
#### `PromptTemplate` 定义提示词模板
from llama_index.core import PromptTemplate
prompt = PromptTemplate("写一个关于{topic}的笑话")
prompt.format(topic="小明")
'写一个关于小明的笑话'
上面这个例子就是对prompt进行了一个自定义
可以看到自定义完了以后prompt.format(topoic="小明")进行格式化,
格式化以后输出,其实就是把格式化的时候,需要的内容自动填充到了提示词模板中,然后做出了输出。
输出了一个填充了关键词的,模板内容.
#### `ChatPromptTemplate` 定义多轮消息模板
from llama_index.core.llms import ChatMessage, MessageRole
from llama_index.core import ChatPromptTemplate
chat_text_qa_msgs = [
ChatMessage(
role=MessageRole.SYSTEM,
content="你叫{name},你必须根据用户提供的上下文回答问题。",
),
ChatMessage(
role=MessageRole.USER,
content=(
"已知上下文:\n" \
"{context}\n\n" \
"问题:{question}"
)
),
]
text_qa_template = ChatPromptTemplate(chat_text_qa_msgs)
print(
text_qa_template.format(
name="瓜瓜",
context="这是一个测试",
question="这是什么"
)
)
system: 你叫瓜瓜,你必须根据用户提供的上下文回答问题。 user: 已知上下文: 这是一个测试 问题:这是什么 assistant:
LlamaIndex也支持对多轮对话进行,提示词的自定义,比如上面就是对多轮对话中的提示词模板进行了自定义.
看到上面对多轮对话的提示词模板进行自定义,然后格式化以后输出了结果。
### 7.2、语言模型
from llama_index.llms.openai import OpenAI
llm = OpenAI(temperature=0, model="gpt-4o")
response = llm.complete(prompt.format(topic="小明"))
print(response.text)
小明有一天去参加一个智力竞赛,主持人问他:“小明,请用‘因为’和‘所以’造一个句子。”
小明想了想,说:“因为今天我没带作业,所以我来参加比赛了。”
然后我们再来看一下LlamaIndex也支持修改默认支持的大模型。
在临时使用的时候,可以通过上面的方式修改模型。
可以看到上面如果是加载指定的openai的模型,那么就需要
llm = OpenAI(temperature=0, model="gpt-4o") 就可以了
加载了以后,就可以用这个模型,进行llm,进行回答提示词中的问题了.
上面是用的我们上面定义的,单轮对话的prompt提示词.
response = llm.complete(
text_qa_template.format(
name="瓜瓜",
context="这是一个测试",
question="你是谁,我们在干嘛"
)
)
print(response.text)
我是瓜瓜,你的智能助手。根据你提供的上下文,我们正在进行一个测试。请让我知道如果你有其他问题或需要进一步的帮助!
然后我们再来看一下:
临时修改完要是用的大模型以后,我们使用之前我们定义的多轮对话的提示模板
再去打印一下结果.看看
#### 设置全局使用的语言模型
from llama_index.core import Settings
Settings.llm = OpenAI(temperature=0, model="gpt-4o")
上面我们设置了大模型,只是临时的时候可以使用,也就是在当前对话中可以使用,
如果我们想要设置的大模型在LlamaIndex框架中的所有地方都可以使用,那么需要使用上面的设置方法。
除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,
详见官方文档:[Available LLM integrations]
(https://docs.llamaindex.ai/en/stable/module_guides/models/llms/modules/)
当然,现在除了openai以外,LlamaIndex框架已经可以支持大部分的大语言模型,包括国内的一些语言模型。
具体的可以参考,具体的文档.
### 7.3、Embedding 模型
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# 全局设定
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512)
然后我们还可以在LlamaIndex框架中去替换所使用的向量化的模型。
具体的替换方法可以参考上面的代码。
比如说这里我们用了text-embedding-3-small这个向量化模型进行替换他原来支持的默认的向量化模型,并且
然后我们给指定的这个text-embedding-3-small向量化模型,在对内容进行向量化的时候,使用512维进行向量化.。
下面的内容不用看,下一节继续:
下一节我们将使用LlamaIndex开发框架来开发一个比较完整的支持RAG功能的应用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











