







 超级会员免费看
超级会员免费看
 本文通过实例展示了在天池工业蒸汽量项目中,如何使用sklearn库进行最大最小值归一化和Z-Score归一化的实战过程。归一化对预测结果的影响被探讨,指出仅对X_train进行归一化是不够的,X_test和y_train也需要进行相同处理。归一化后,模型预测的损失值减小,表明归一化能提升模型性能。
本文通过实例展示了在天池工业蒸汽量项目中,如何使用sklearn库进行最大最小值归一化和Z-Score归一化的实战过程。归一化对预测结果的影响被探讨,指出仅对X_train进行归一化是不够的,X_test和y_train也需要进行相同处理。归一化后,模型预测的损失值减小,表明归一化能提升模型性能。
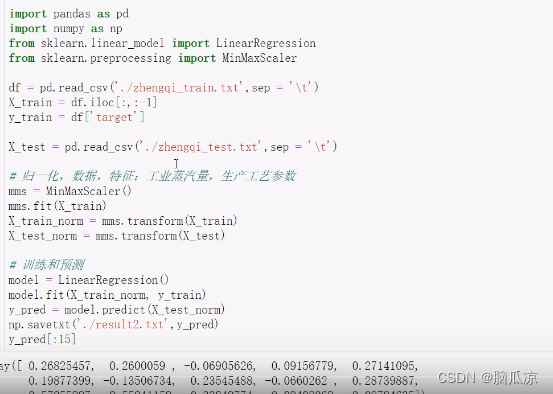
我们先来看一下使用最大最小值归一化,以后再去进行预测,然后看结果
上一节我们发现,进行归一化和不进行归一化得到的,预测结果得到的评分一样对吧,我们看看怎么回事.
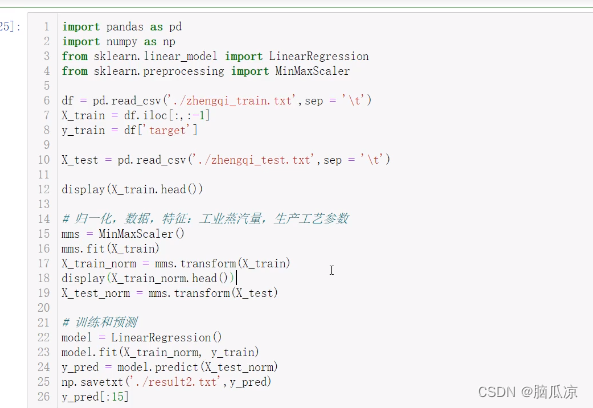
import pandas as pd 读取csv文件
import numpy as np 数学计算
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler
df=pd.readcsv('./zhengqi_train.txt',sep='\t')
X_train=df.iloc[:,:1] X_train数据从第一列截取到前一列,其实就是x数据
y_train=df[target'] y_train 获取最后一列数据也就是目标数据
X_test = pd.read_csv('./zhengqi_test.txt' , sep = '\t' ) 获取测试数据
display

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











