







 超级会员免费看
超级会员免费看
 本文介绍了Flink在Yarn和K8s上的部署方式,包括session-cluster模式和per-job-cluster模式的详细步骤。在session-cluster模式中,所有任务共享资源,适合小型短期任务;而在per-job-cluster模式中,每个任务独享资源,适合大型长期任务。此外,还简述了在K8s上搭建Flink集群的过程。
本文介绍了Flink在Yarn和K8s上的部署方式,包括session-cluster模式和per-job-cluster模式的详细步骤。在session-cluster模式中,所有任务共享资源,适合小型短期任务;而在per-job-cluster模式中,每个任务独享资源,适合大型长期任务。此外,还简述了在K8s上搭建Flink集群的过程。
上一节我们已经学习了,怎么使用命令行来提交job集群,但是这样是有问题的。
因为在上一节中,我们为了要运行一个我们写的WordCountStream这个任务。由于资源不够了,我们主动去终止了之前上传的另外一个资源。释放了资源以后,有4个资源了,这个任务才能运行起来。
在实际的应用当中,我们肯定不能这样做,如果每次都需要主动去终止其他任务来获取资源,这样太繁琐了,我们需要的是当我们有任务需要运行的时候。他立刻就能获取资源,然后进行运行。所以我们一般把flink和hadoop k8s yarn一块来使用。
嗯。所以接下来我们要说flink和k8s以及yarn的集成。
首先如果我们让flink和yarn集成的话,我们一定要下载带有hadoop集成包的flink安装包,但是最新的flink版本的安装包已经不和hadoop一起打包了,需要我们自己去下载了hadoop支持的插件,然后放到安装后的flink都对应的目录中对吧,这个之前我们说过了。
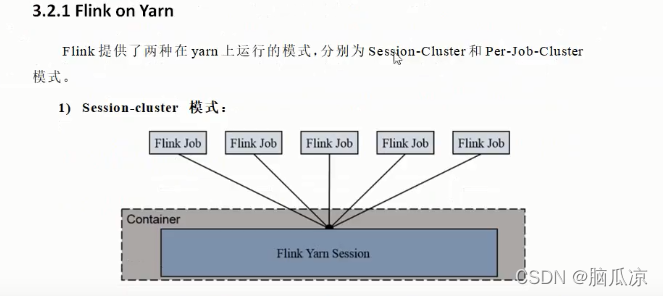
可以看到session-cluster模式,这种模式就是创建了一个flink yarn session的会话
然后所有的任务来了以后都会提交到这个会话中,当这个flink yarn session会话的资源满了以后。
剩下的来执行的job任务就需要等待。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











