







 超级会员免费看
超级会员免费看
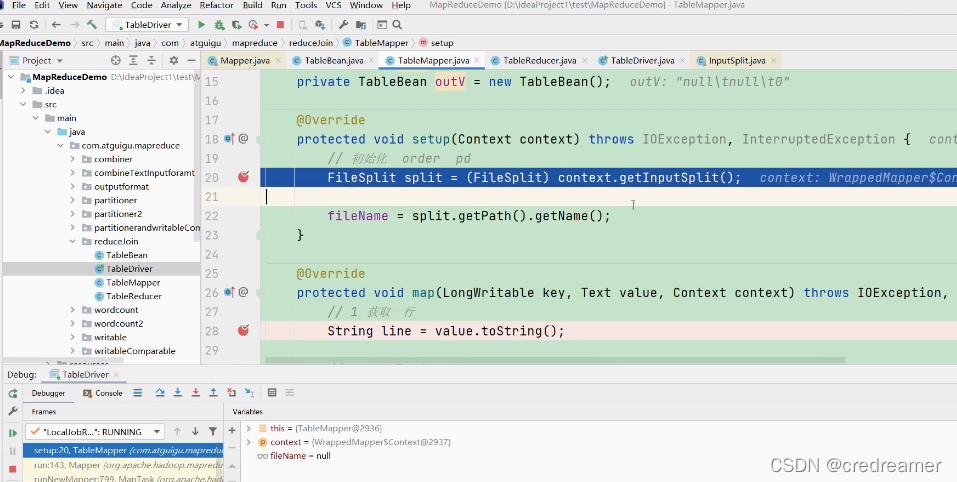
程序我们已经写完了,然后我们去调试一下,执行首先走到mapper中去
可以看到获取了分片信息 split,然后通过split获取文件名
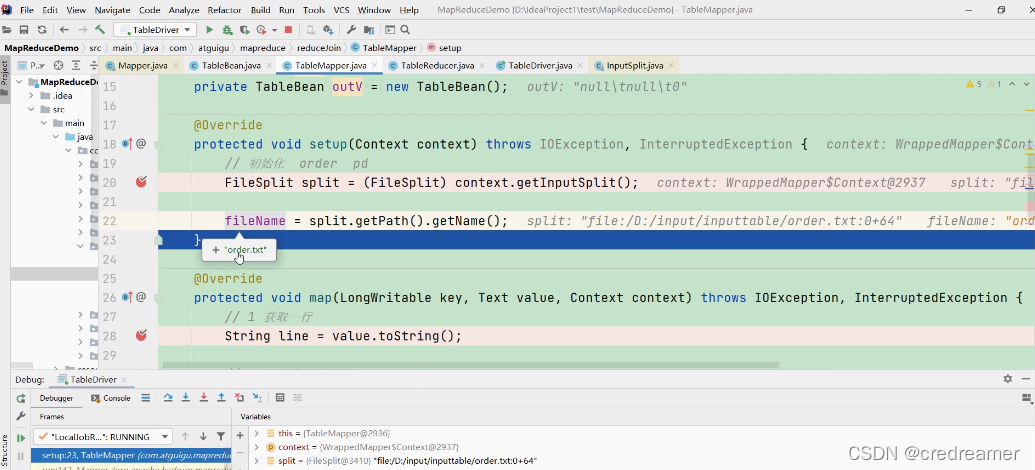
可以看到文件名已经获取了
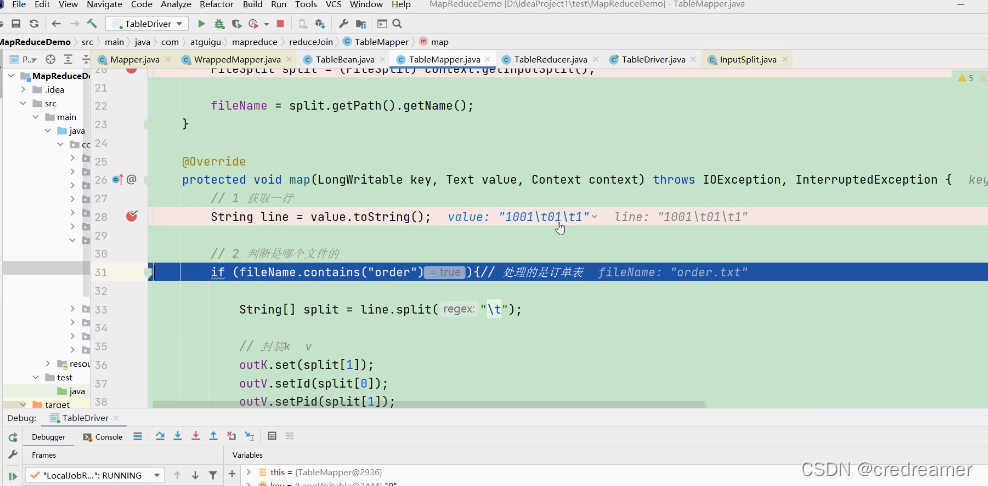
然后走完setup以后,就走入这个map方法了,然后
判断这里是order,所以
填充order的数据
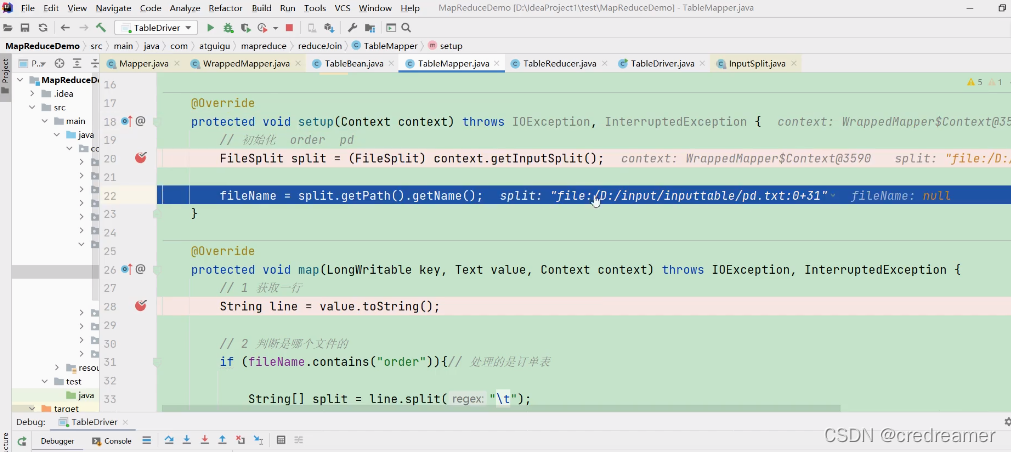
order.txt文件处理完了以后,可以看到又去处理pd.txt文件了,这个时候走处理pd.txt的分支
程序我们已经写完了,然后我们去调试一下,执行首先走到mapper中去
可以看到获取了分片信息 split,然后通过split获取文件名
可以看到文件名已经获取了
然后走完setup以后,就走入这个map方法了,然后
判断这里是order,所以
填充order的数据
order.txt文件处理完了以后,可以看到又去处理pd.txt文件了,这个时候走处理pd.txt的分支

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























