







 超级会员免费看
超级会员免费看
 这篇博客介绍了Hadoop3.x中MapReduce的ReduceJoin案例,讲解了如何使用TableMapper处理订单(order.txt)和产品(pid.txt)数据。在Mapper阶段,通过FileSplit获取文件名,并在setup方法中获取一次,避免在map方法中重复获取。内容包括设置全局变量fileName,解析数据,创建key-value对,区分order和pd数据,设置不同的数据字段并输出。
这篇博客介绍了Hadoop3.x中MapReduce的ReduceJoin案例,讲解了如何使用TableMapper处理订单(order.txt)和产品(pid.txt)数据。在Mapper阶段,通过FileSplit获取文件名,并在setup方法中获取一次,避免在map方法中重复获取。内容包括设置全局变量fileName,解析数据,创建key-value对,区分order和pd数据,设置不同的数据字段并输出。
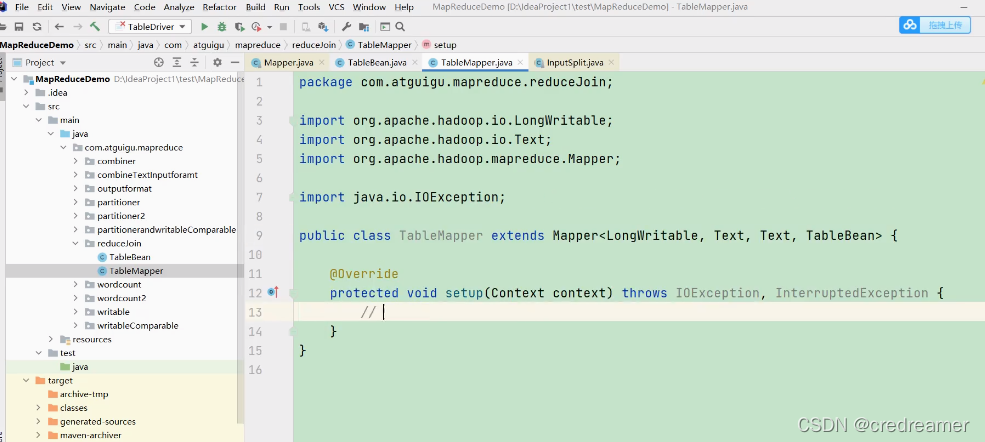
然后我们再去开始写mapper,可以看到
TableMapper,写这个类,然后继承Mapper
然后去看看我们准备的这两个文件
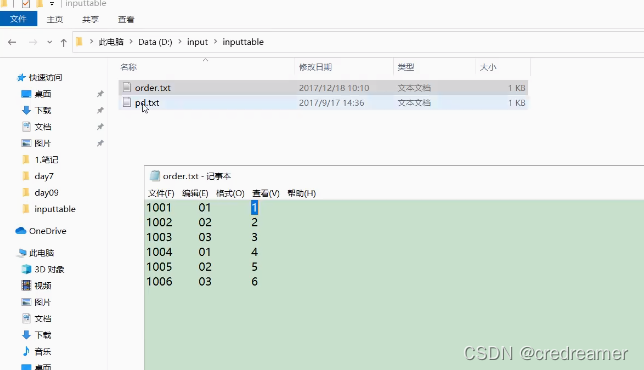
文件内容很简单,这个是order,是
订单id 产品pid 数量 对吧
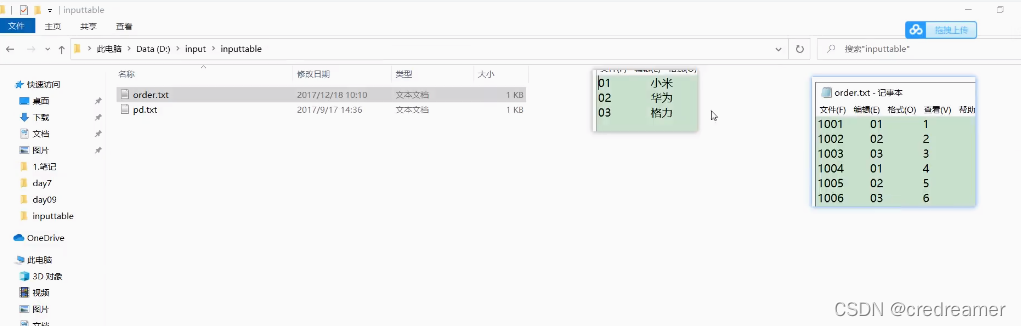
然后再看看,这个pd.txt可以看到是
产品pid 还有产品名称
然后我们再去开始写mapper,可以看到
TableMapper,写这个类,然后继承Mapper
然后去看看我们准备的这两个文件
文件内容很简单,这个是order,是
订单id 产品pid 数量 对吧
然后再看看,这个pd.txt可以看到是
产品pid 还有产品名称

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























