







 超级会员免费看
超级会员免费看
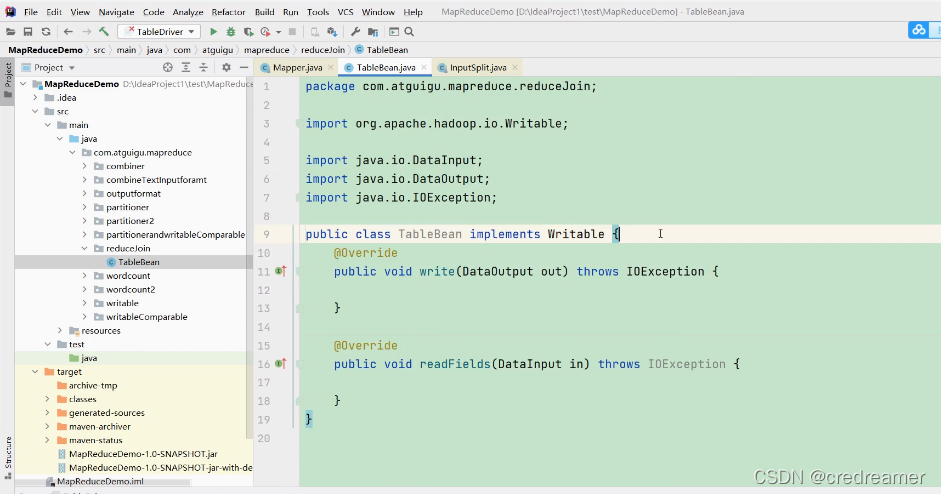
可以看到我们去创建了一个package,是reducejoin,然后我们创建了一个类TableBean
这个Bean实现了Writable这个接口,表示,可写的也就是实现序列化
然后write 就是序列化方法,然后readFields就是反序列化方法对吧.
写出去有可能需要通过网络传输,这个是序列化的,然后readFields就是,从序列化数据中
解析出具体的数据来就是反序列化.
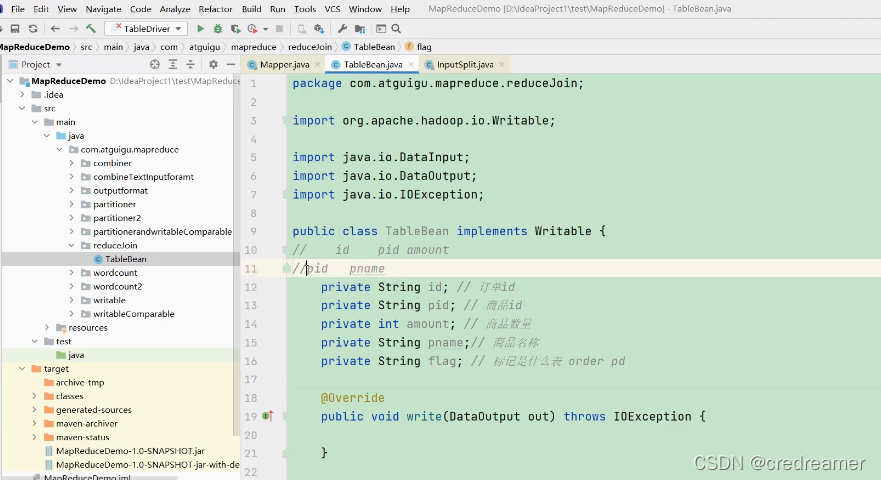
然后我们去实现这个TableBean这个类,先根据上一节我们的分写,写上,属性
id pid amount pname flag 这几个属性
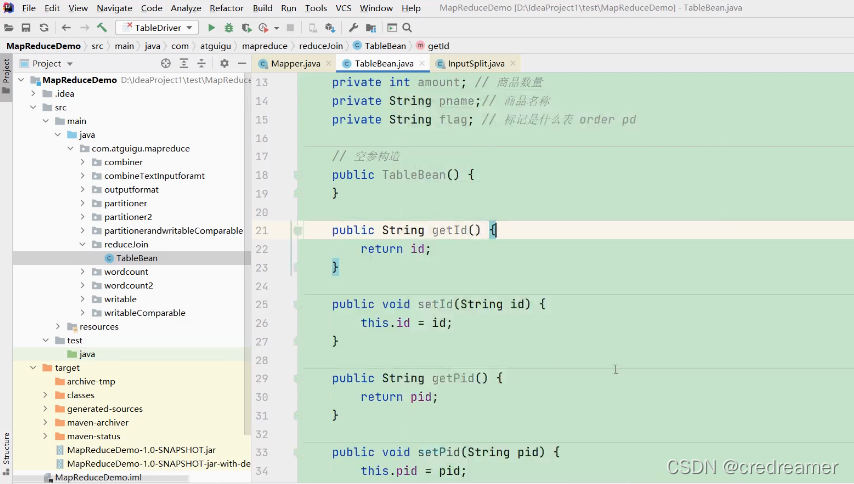
然后生成get,set方法,并且一定要提供空参构造方法,这个之前咱们也说过了.

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











