







 超级会员免费看
超级会员免费看
 本文介绍了Hadoop3.x中的MapReduce排序过程,包括Map阶段的分区快排、溢写前的排序,以及Reduce阶段的归并排序。默认情况下,MapReduce会对数据进行字典顺序的快速排序,确保每个分区文件内部有序。通过设置reduceTask数量为1可实现全排序。此外,还讨论了辅助排序和二次排序的概念,允许自定义排序规则。最后提到了重写compareTo接口以实现特定排序需求,并推荐了技术交流平台。
本文介绍了Hadoop3.x中的MapReduce排序过程,包括Map阶段的分区快排、溢写前的排序,以及Reduce阶段的归并排序。默认情况下,MapReduce会对数据进行字典顺序的快速排序,确保每个分区文件内部有序。通过设置reduceTask数量为1可实现全排序。此外,还讨论了辅助排序和二次排序的概念,允许自定义排序规则。最后提到了重写compareTo接口以实现特定排序需求,并推荐了技术交流平台。
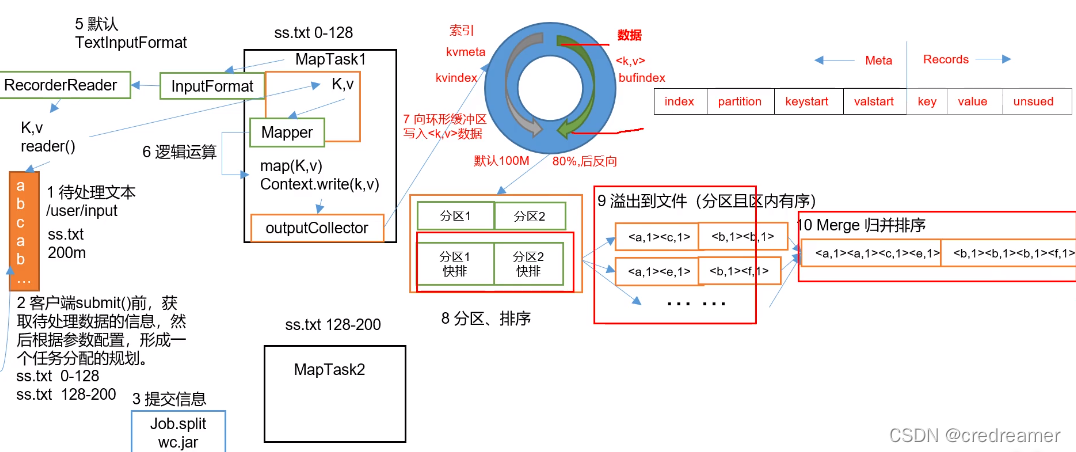
1.看MapReduce的排序,我们先看一下,map方法之后 ,数据整理以后会,进入环形缓冲区,然后
环形缓冲区中的数据满了以后,多于百分之80的时候,会进行数据溢写,数据溢写之前会进行排序对吧,可以看到分区内的数据会进行分区快排,快排以后,然后会一些到文件,然后会再对这个区内有序的文件会再进行归并排序.上面的map阶段的排序.
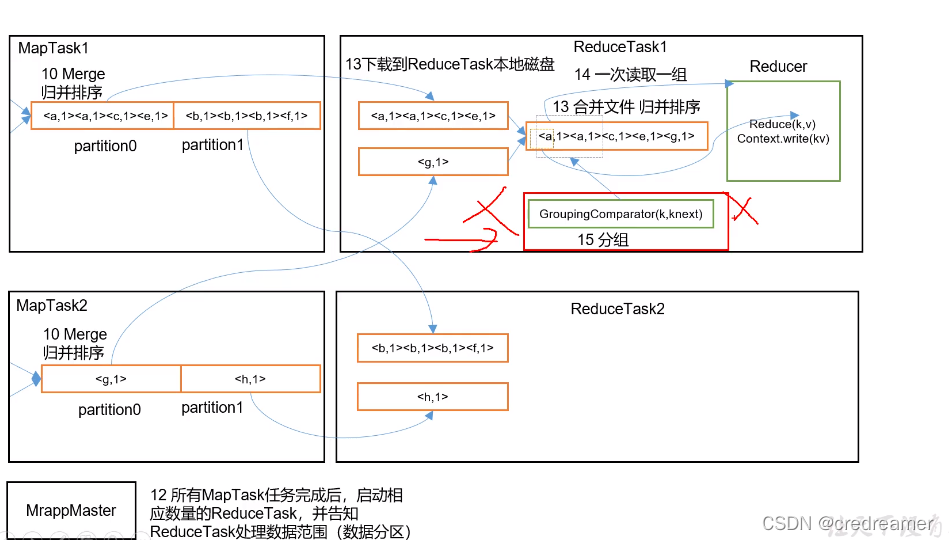
2.然后我们再看在reduce阶段,会先把map阶段整理好的数据,拉取过来,然后,拉取的动作是reduceTask完成的,然后拉取以后,因为有可能是从不同的分区,也就是不同的mapTask中拉取
过来的,所以,reduceTask又对拉取过来的数据进行了一次归并排序,当然归并排序以后,还可以对数据进行一次分组排序, 也可以我们自定义分组排序,这个后面再说吧.经过这些排序就可以交给reducer进行数据处理了.

3

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











