







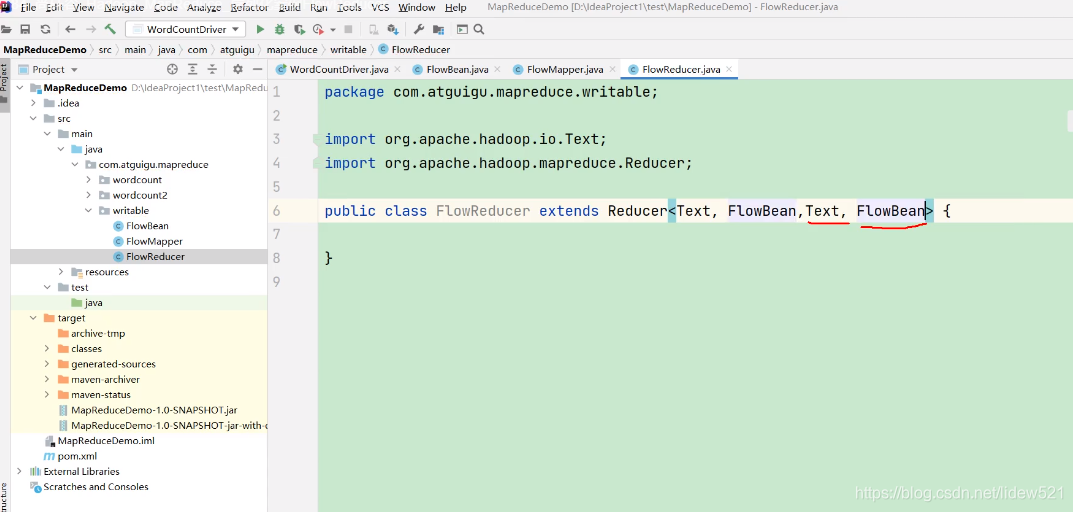
然后我们接着去写hadoop这个序列化案例,统计手机号使用流量情况的
reducer类去,我们起个名字叫
FlowReducer类,可以看到这个类的泛型参数,Reducer的输入,就是
mapper类的输出,就是Text,FlowBean 对吧Text是手机号,然后FlowBean是对一行数据的封装.
然后reducer的输出我们说也是手机号,和一个FlowBean对象对吧,所以输出的key,value类型也是
Text,FlowBean对吧
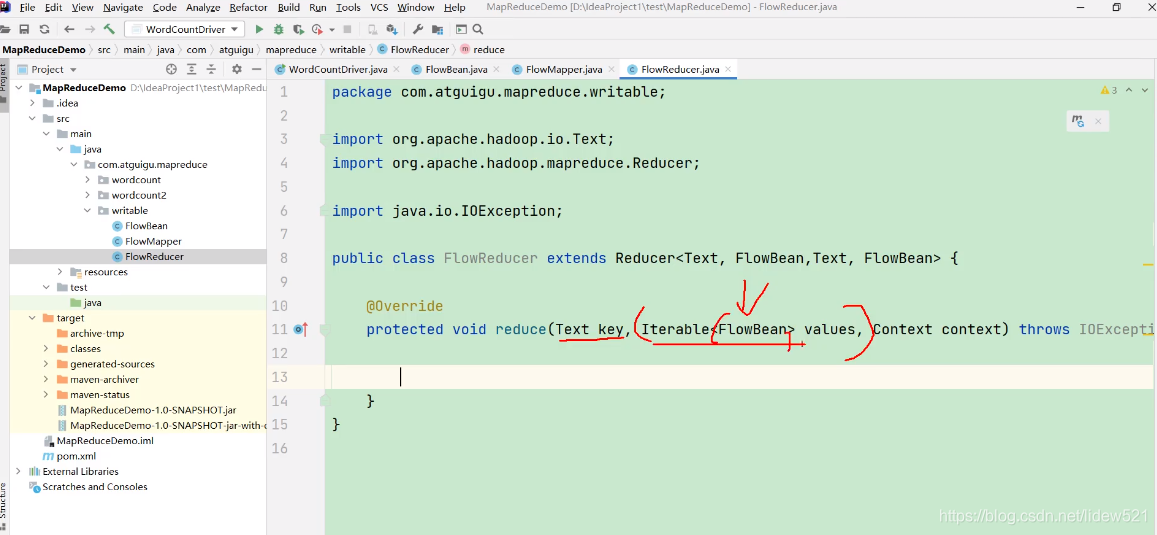
然后我们去重写reduce方法,可以看到
reduce方法中,reduce方法的输入,是一个key,value, key是Text类型的,这里是手机号,然后
value是集合类型的,对于我们来说就是,对应的同一个手机号,对应的,所有的上行流量,下行流量,的集合,每一行都对应
一个手机号的上行流量,下行流量对吧.
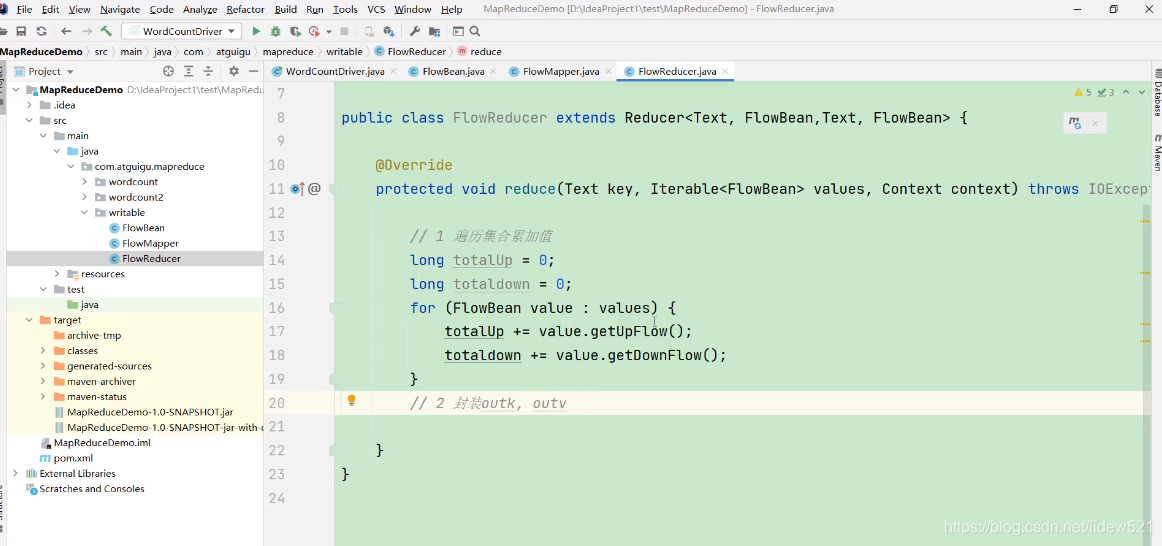
然后我们去遍历,去执行统计就可以了
可以看到,因为reduce方法,针对每个key,会执行一次,可以看到,我们的key是一个手机号
这样就会每一个手机号,就会执行一次这个reduce方法,而每个手机号,又可能对应的多组数据
比如:
13256716166,((FlowBean1,FlowBean2,......))
这样的,可以看到我们把每个手机号的,对应的所有的FlowBean都进行了加算,这样就得到了
这个手机号对应的,上行流量的总和,下行流量的总和
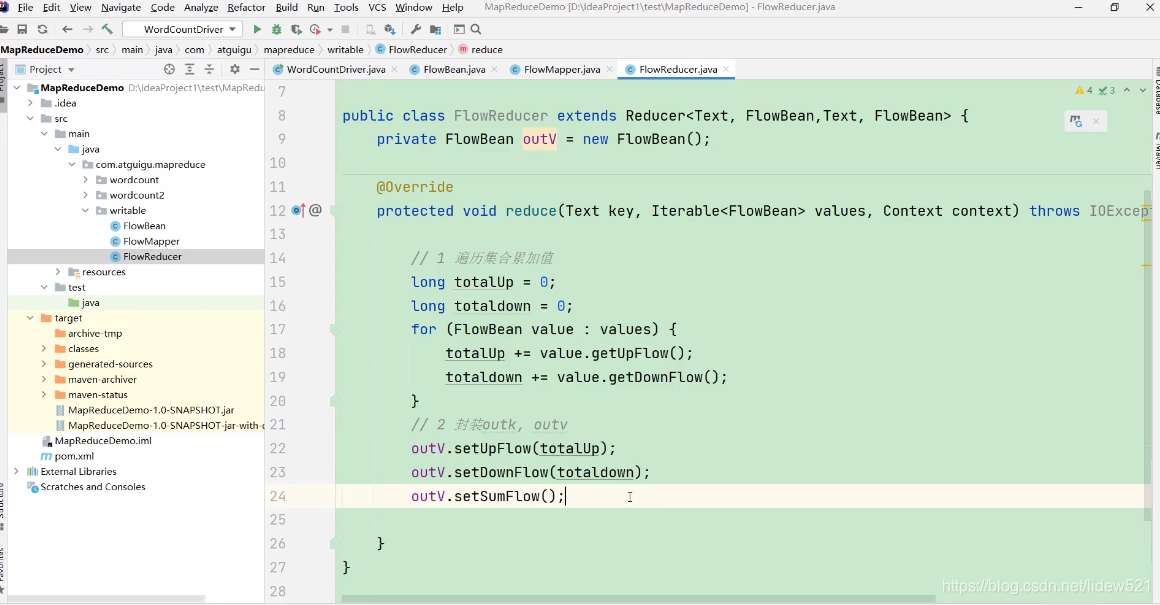
然后我们再去声明一个FlowBean 是outV这个变量.
可以看到这个变量是reducer输出的那个value的值,我们把加算后的上行流量,下行流量
最后,我们outV.setSumFlow这个又进行了这个手机号对应的,总流量的计算
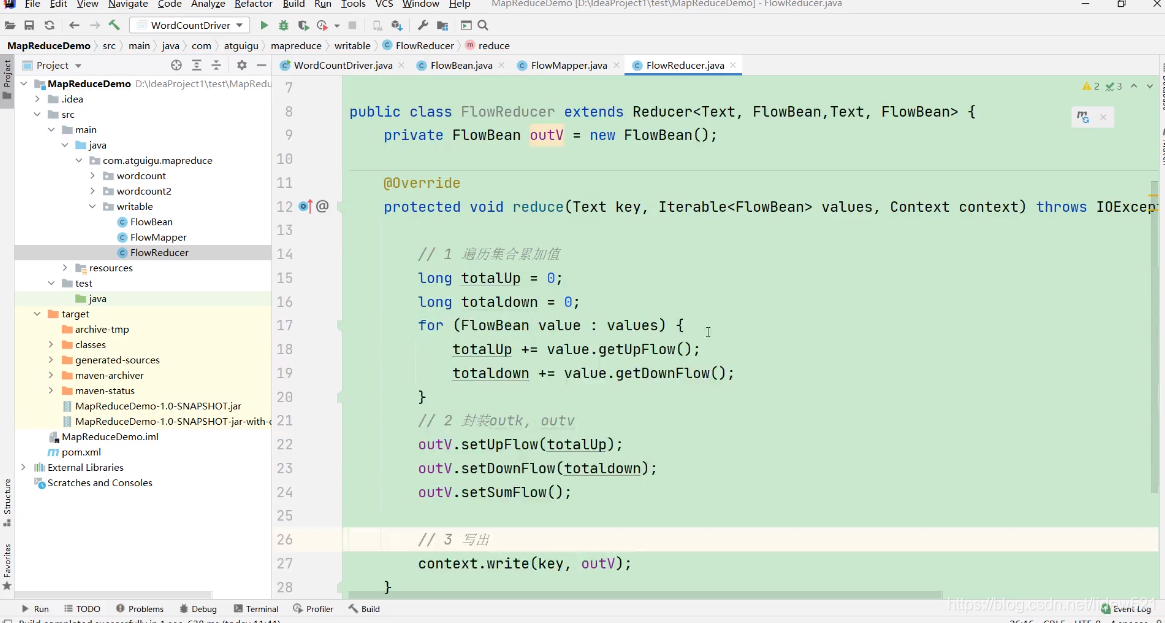
最后我们把reducer的输出key,value,写入到context上下文中去就可以了这样就可以了
这样我们就完成了reducer的编写了.
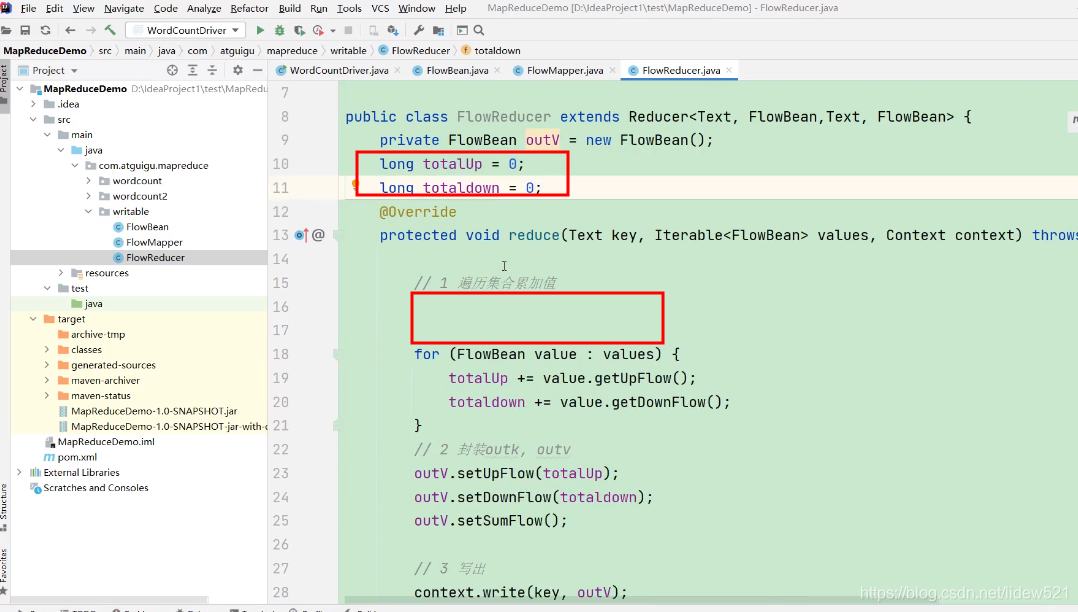
有同学说把,这个定义的totalUp down这两个变量放到reduce方法外面这样可以吗?
不可以对吧,因为我们知道reduce,是每个key会调用一次,也就是每个手机号,会调用一次
所以每个手机号,统计完上行,下行流量以后,都需要清空一下
如果不清空,就变成所有手机号的,总的上行,下行流量了计算的就不对了.
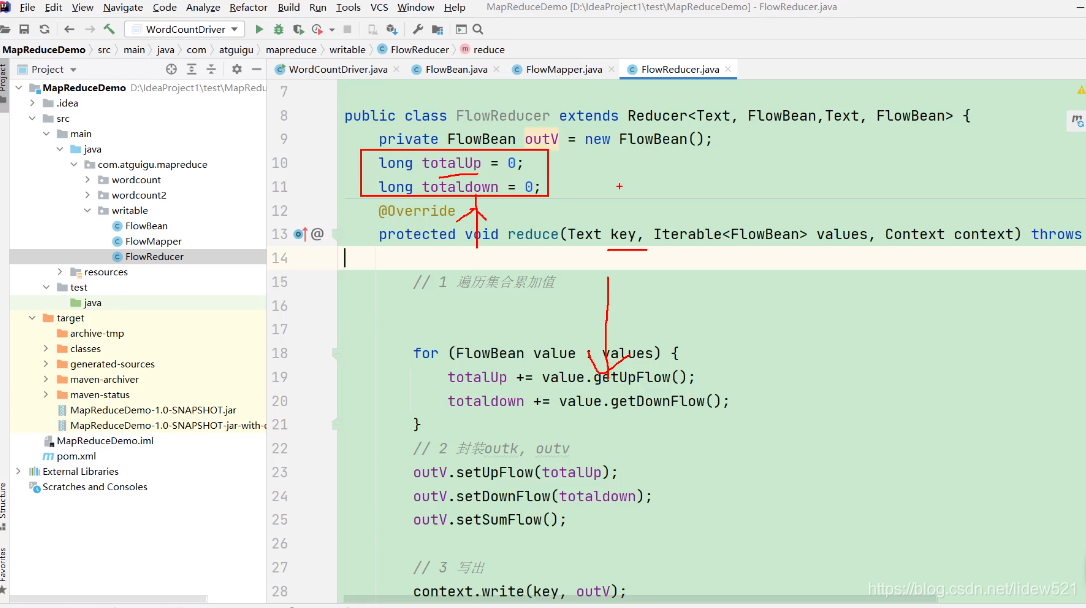
那么这个两个变量totalUp,totaldown
放到for循环里面可以吗?
不可以对吧,这样每次循环都把totalUp down统计的流量给清空了,这样是不对的对吧.
技术交流QQ群【JAVA,C++,Python,.NET,BigData,AI】:170933152
优快云账号:credreamer
开通了个人技术微信公众号:credream,有需要的朋友可以添加相互学习




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











