







 超级会员免费看
超级会员免费看
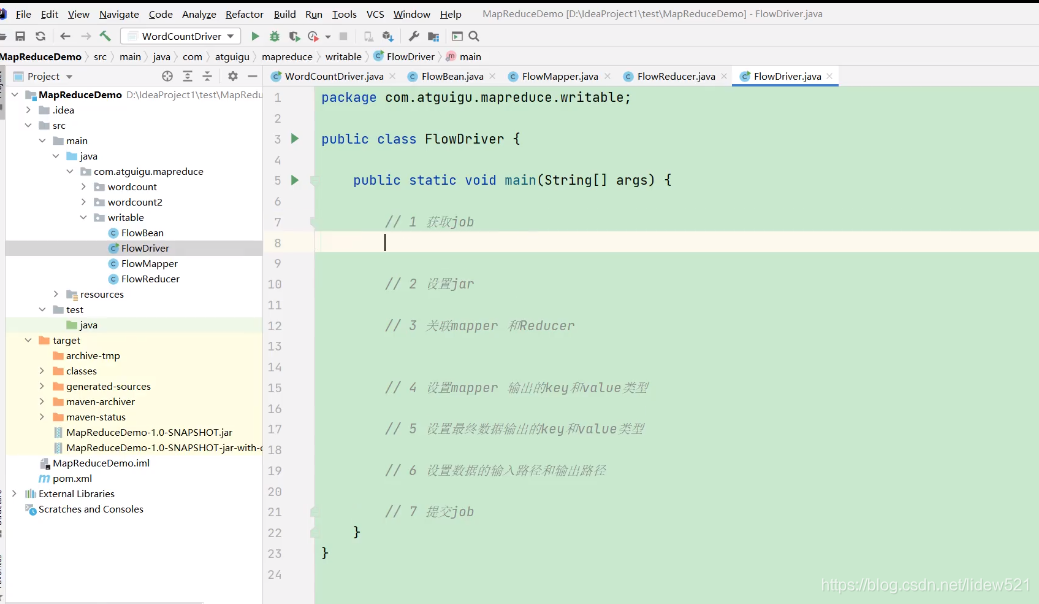
然后我们再去写那个FlowDriver,去看看,还是那7个步骤对吧.
首先去获取job
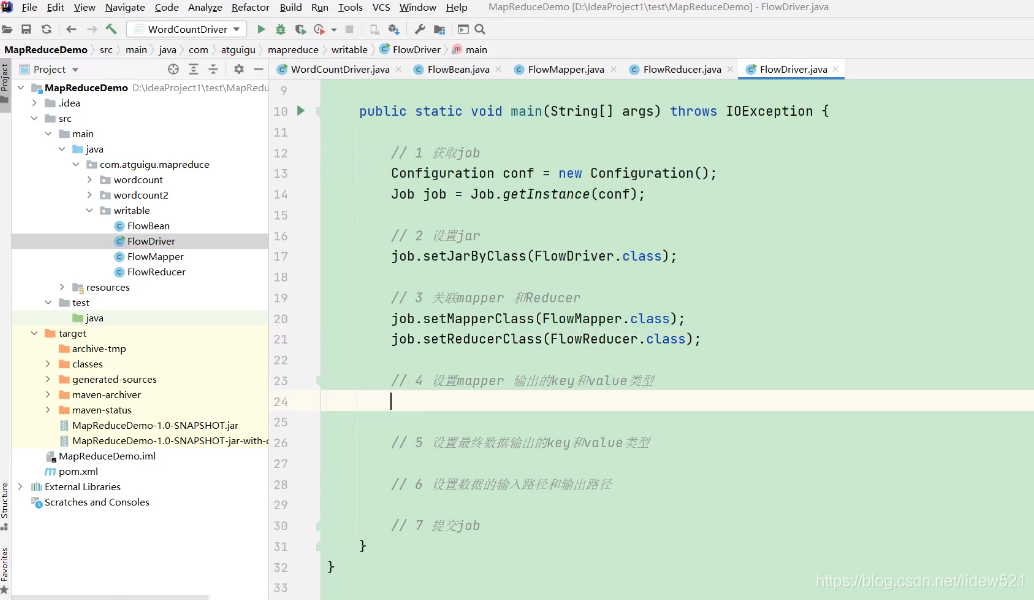
然后设置jar,然后再去
设置mapper和reducer的关联
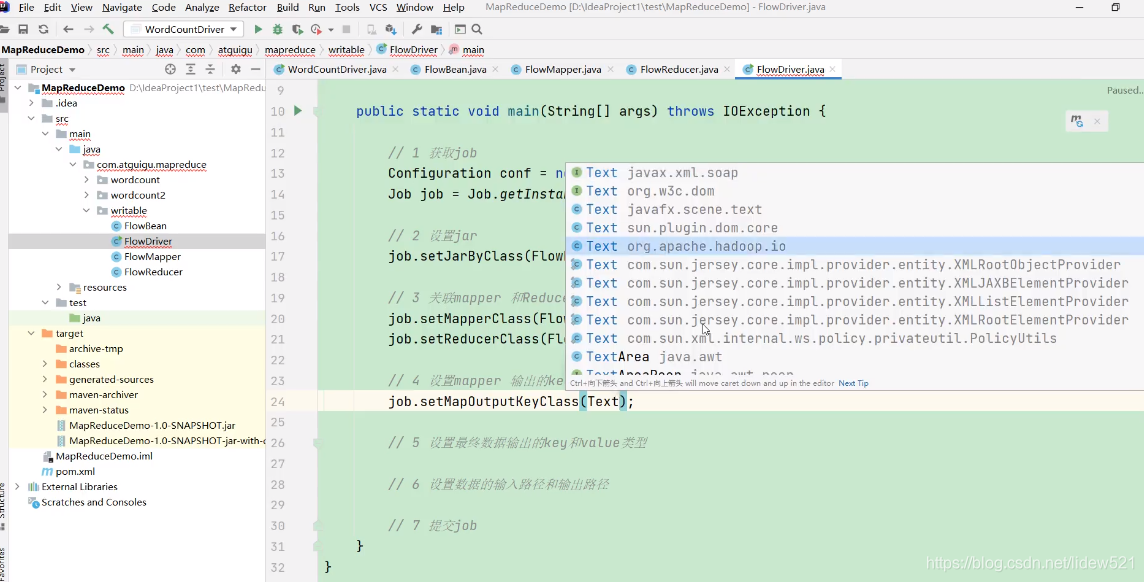
然后再去设置mapper输出的key,value的类型,可以看到是
Text,对应的手机号,然后
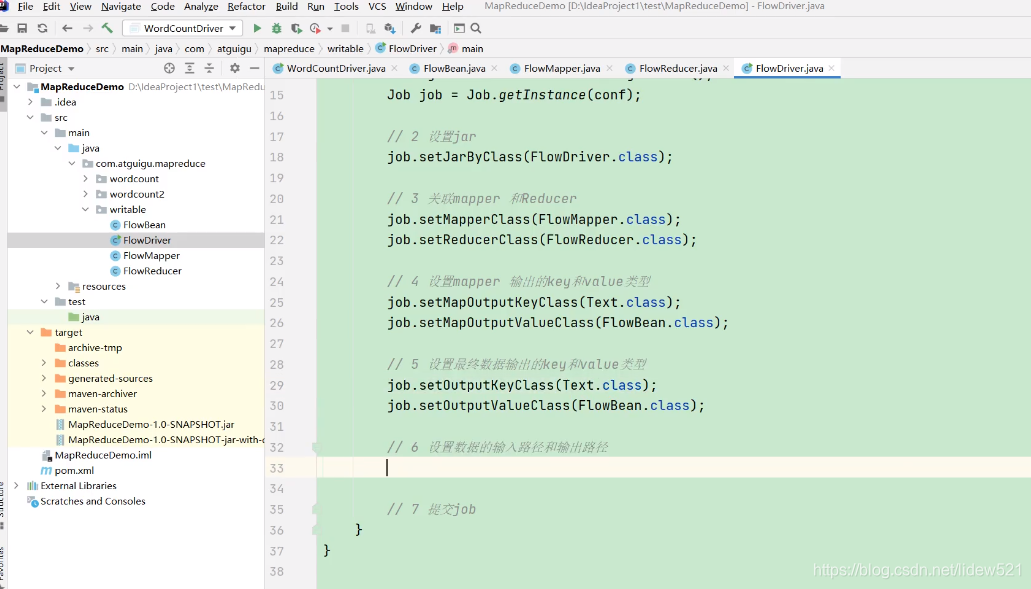
FlowBean对应的,输出的value.
然后再去设置reducer输出的,key,value的类型
可以看到Text对应的是key是手机号
然后我们再去写那个FlowDriver,去看看,还是那7个步骤对吧.
首先去获取job
然后设置jar,然后再去
设置mapper和reducer的关联
然后再去设置mapper输出的key,value的类型,可以看到是
Text,对应的手机号,然后
FlowBean对应的,输出的value.
然后再去设置reducer输出的,key,value的类型
可以看到Text对应的是key是手机号

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























