







 超级会员免费看
超级会员免费看
 本文介绍了如何配置Hadoop的日志聚集服务,以显示MapReduce程序的详细执行信息。首先,需要停止historyserver、nodemanager和resourcemanager,然后在`yarn-site.xml`中开启日志聚集功能并设置保留时间。启动相关服务后,删除之前的output文件夹,重新运行wordcount案例,即可在YARN后台查看带有详细日志的执行历史,这对于调试MapReduce程序非常有帮助。
本文介绍了如何配置Hadoop的日志聚集服务,以显示MapReduce程序的详细执行信息。首先,需要停止historyserver、nodemanager和resourcemanager,然后在`yarn-site.xml`中开启日志聚集功能并设置保留时间。启动相关服务后,删除之前的output文件夹,重新运行wordcount案例,即可在YARN后台查看带有详细日志的执行历史,这对于调试MapReduce程序非常有帮助。

上一节我们配置了执行MapReduce程序后的,我们希望显示我们执行的MapReduce程序的详细信息,
所以我们配置了,历史服务器,接下来为了显示我们MapReduce程序执行中的,更详细的信息,我们来配置
日志聚集服务,
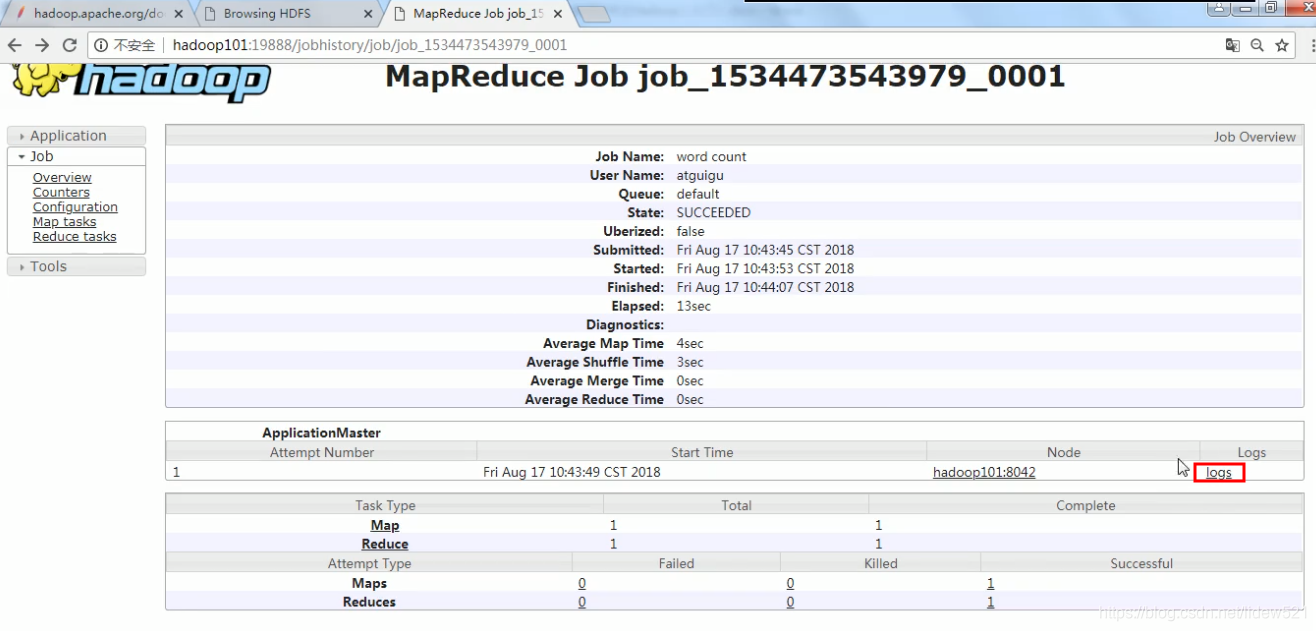
可以看到我们配置日志聚集服务之前,点击logs,在历史服务,的overview页面中,点击
logs
会报错
到时候,我们聚集了日志信息,会上传到我们的hdfs上
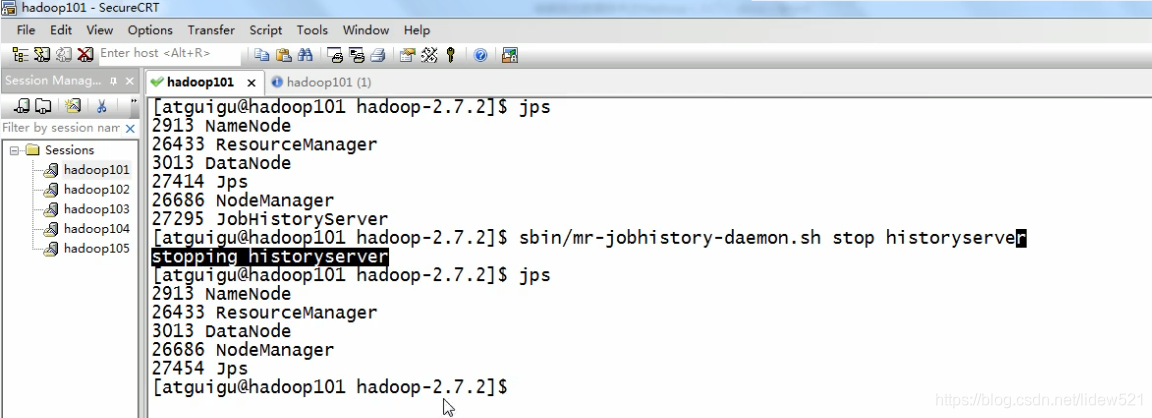
注意要配置日志聚集服务,首先要停
上一节我们配置了执行MapReduce程序后的,我们希望显示我们执行的MapReduce程序的详细信息,
所以我们配置了,历史服务器,接下来为了显示我们MapReduce程序执行中的,更详细的信息,我们来配置
日志聚集服务,
可以看到我们配置日志聚集服务之前,点击logs,在历史服务,的overview页面中,点击
logs
会报错
到时候,我们聚集了日志信息,会上传到我们的hdfs上
注意要配置日志聚集服务,首先要停

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























