







 超级会员免费看
超级会员免费看
 本文档介绍了如何在Hadoop本地模式下运行官方的WordCount案例。首先创建输入文件夹wcinput,写入内容,然后在hadoop-2.7.2根目录下运行`hadoop jar`命令执行wordcount。执行后,查看结果文件part-r-00000,显示了单词计数。最后讨论了如何获取统计结果的前10个词。
本文档介绍了如何在Hadoop本地模式下运行官方的WordCount案例。首先创建输入文件夹wcinput,写入内容,然后在hadoop-2.7.2根目录下运行`hadoop jar`命令执行wordcount。执行后,查看结果文件part-r-00000,显示了单词计数。最后讨论了如何获取统计结果的前10个词。

然后我们再来看一个hadoop,官方提供的一个案例,我运行起来看看效果.
按照上面的过程我们来做一下
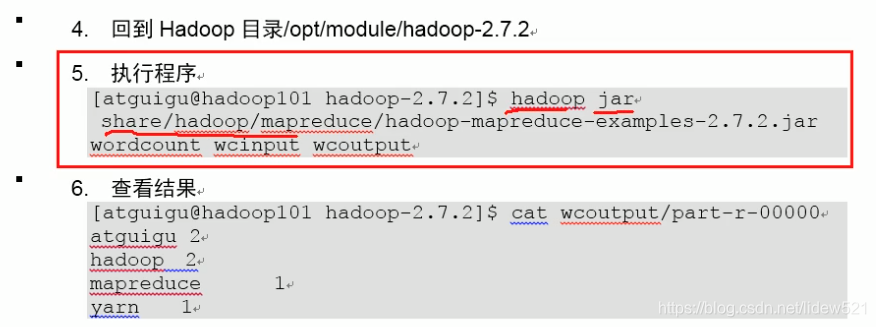
上面是文档上的整个流程.
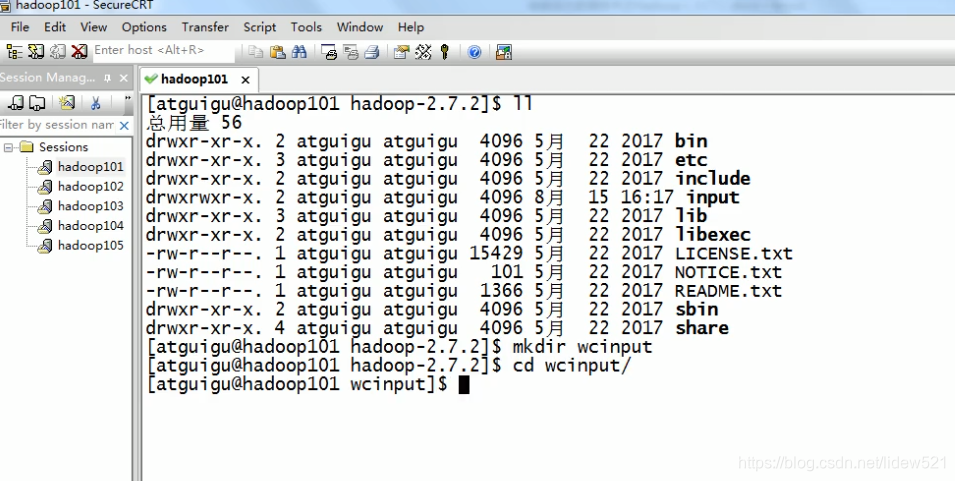
首先我们还是创建,输入文件夹
wcinput
然后进入这个文件夹wcinput
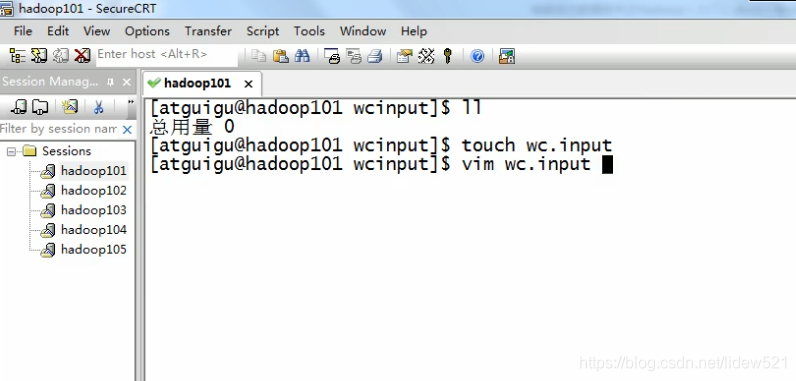
然后在这个文件夹下;,创建一个文件,叫wc.input
然后编辑这个文件
然后我们再来看一个hadoop,官方提供的一个案例,我运行起来看看效果.
按照上面的过程我们来做一下
上面是文档上的整个流程.
首先我们还是创建,输入文件夹
wcinput
然后进入这个文件夹wcinput
然后在这个文件夹下;,创建一个文件,叫wc.input
然后编辑这个文件

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























