







 超级会员免费看
超级会员免费看
 本文介绍了如何在Hadoop的本地模式下执行Grep案例,用于理解和调试。首先创建input目录并复制etc/hadoop/*.xml到其中,然后使用hadoop-mapreduce-examples.jar中的grep例子,寻找以dfs开头的xml文件。执行命令需确保output目录不存在,否则会报错。成功执行后,结果将保存在output目录的part-r-00000文件中。
本文介绍了如何在Hadoop的本地模式下执行Grep案例,用于理解和调试。首先创建input目录并复制etc/hadoop/*.xml到其中,然后使用hadoop-mapreduce-examples.jar中的grep例子,寻找以dfs开头的xml文件。执行命令需确保output目录不存在,否则会报错。成功执行后,结果将保存在output目录的part-r-00000文件中。
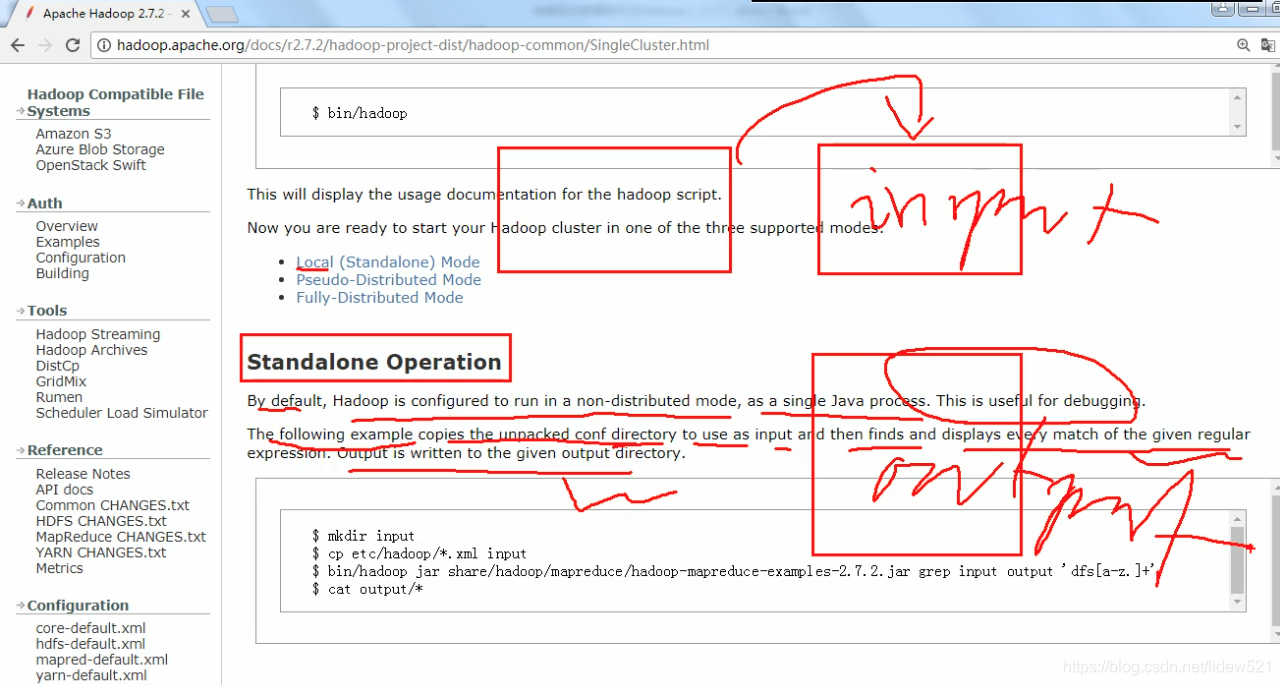
然后我们再继续看帮助文档,可以看到有个standalone operation 独立操作.
这里本地模式,说hadoop默认被配置为,不是分布式的mode,也就是上面独立操作模式,做为一个单独的java进程运行,这样的模式对于调试测试是很有用的.
然后下面是个例子,说,把conf文件夹中的xml文件都copy到input,这个文件夹中,然后,我们用提供的案例,来按照指定的正则表达式,来找到
对应的文件,以及统计文件的个数
可以看到上面就是首先创建了一个文件夹input,然后把etc/hadoop/*.xml中的所有的xml文件都放入了input中,然后
执行了一个jar,去找到以dfs开头的xml文件.
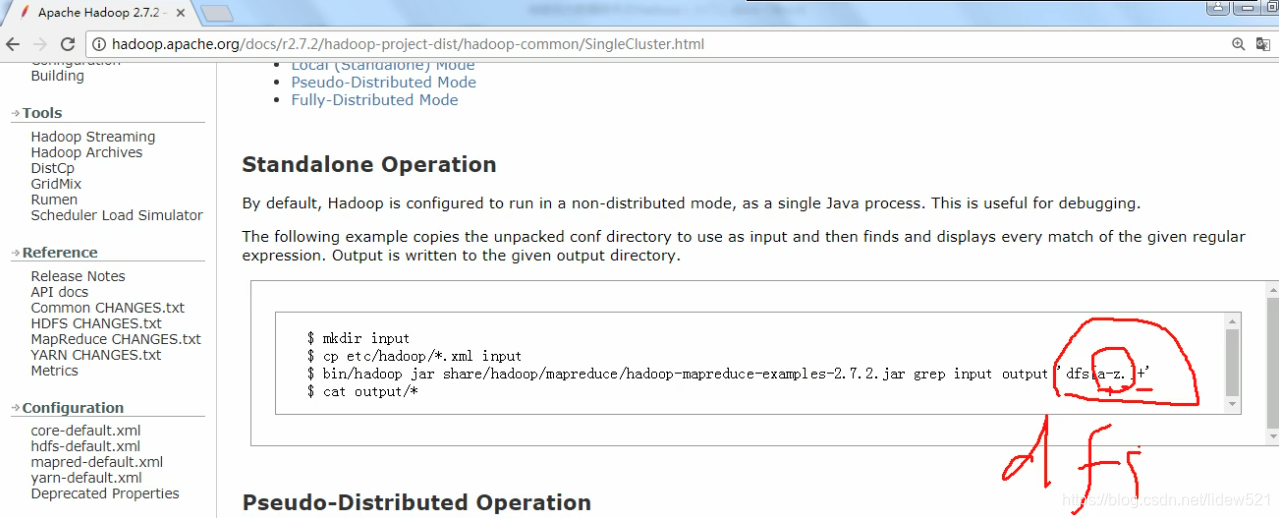
这里dfs[a-z.]+ 是一个正则表达式,这个就不多说了.

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











