




 本文深入探讨了卡尔曼滤波在WebRTC中的应用,主要涉及时间戳估计和抖动延迟估计。通过实例分析,展示了卡尔曼滤波如何在系统模型与观测值之间找到最优估计,以适应网络环境变化。在timestamp_extrapolator中,卡尔曼滤波用于预测帧的到达时间,而在jitter_delay模块中,它用于估算网络抖动,确保视频流畅播放。文章还提供了Python模拟代码,以帮助理解卡尔曼滤波的工作原理。
本文深入探讨了卡尔曼滤波在WebRTC中的应用,主要涉及时间戳估计和抖动延迟估计。通过实例分析,展示了卡尔曼滤波如何在系统模型与观测值之间找到最优估计,以适应网络环境变化。在timestamp_extrapolator中,卡尔曼滤波用于预测帧的到达时间,而在jitter_delay模块中,它用于估算网络抖动,确保视频流畅播放。文章还提供了Python模拟代码,以帮助理解卡尔曼滤波的工作原理。
卡尔曼滤波在webrtc中有多处运用,这里简单总结一下自己的一些认识。
1.卡尔曼滤波的理解
本节主要记录自己对卡尔曼滤波中,哪些量代表啥,哪些量是需要根据系统性质设置,哪些量需要手动调,分别如何影响输出的总结。
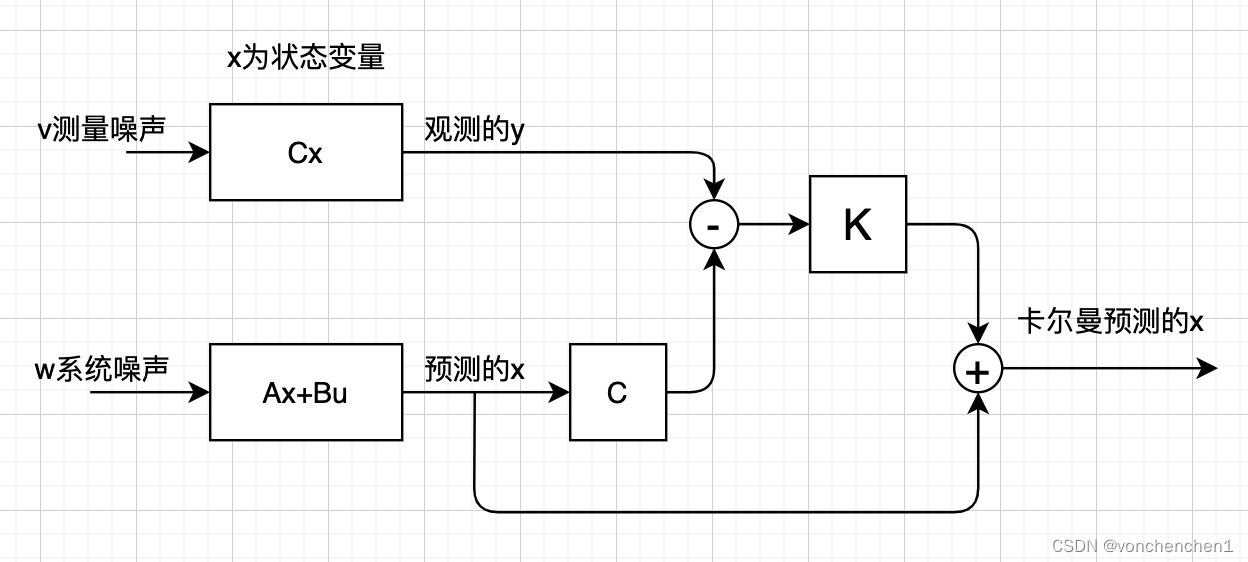
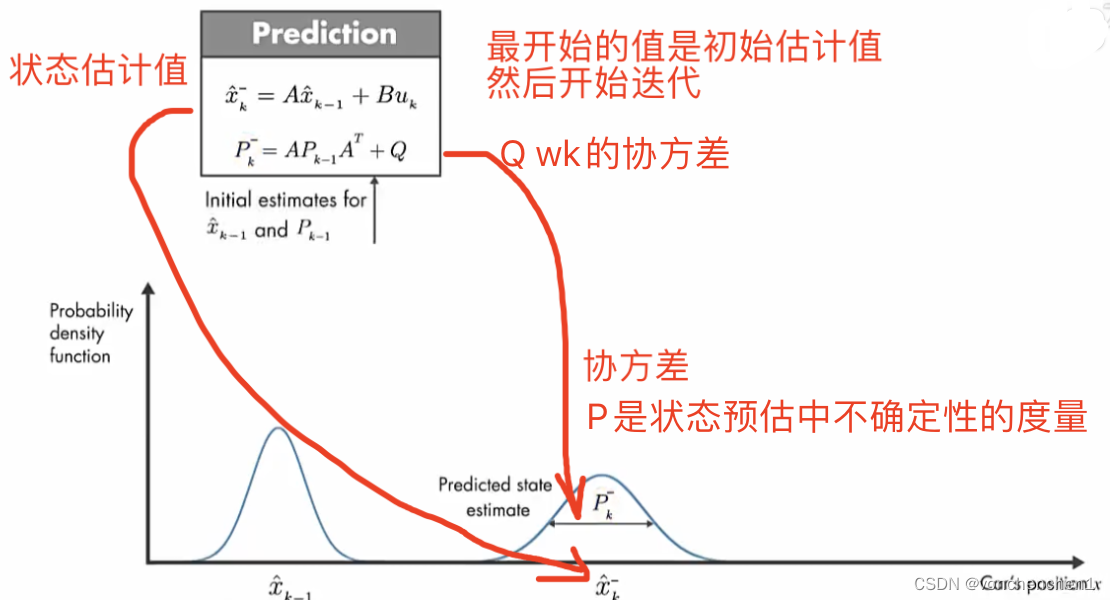
上图描述了卡尔曼滤波的基本流程,对于一些系统无法直接预测到他下一次的输出,但是可以通过间接测量得到一些信息,同时我们也知道本身系统的一些特点,基于这两者通过卡尔曼滤波,预测出系统的输出。
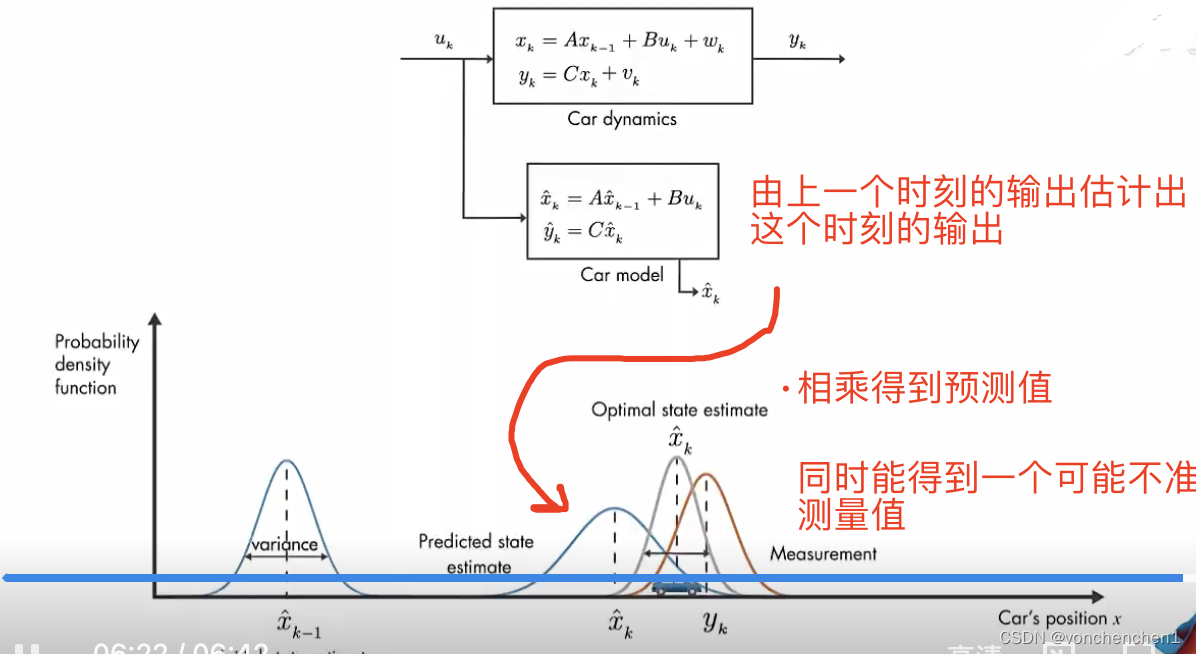
上面框框中会输出一个yk,这个相当于观测器观测到的数据,实际应用我理解就是传感器检测到的值,xk是我们想知道的真的输出量(卡尔曼最终就是要猜出xk的值),对于上面的框框,我们只能得到y的值。A代表了这个系统,B是施加的外部控制量,C代表了我们要猜测的xk与输出yk的关系,注意我们现在只能得到yk的值,通过C是xk与yk的转换关系,wk是系统的噪声,vk是观测噪声。
下面的框框是我们知道模型后,对输出xk做出的预测,这个预测没有当前的系统噪声和测量噪声。这样我们得到的估计值可能是不准确的,如途中xk尖。通过对估计的xk尖的观测,可以得到一个y尖。下面就比较观测值的差距,经过处理,反馈给下一次的估计,从而修正下一次估计的x尖,同样下一次也会观测当前的x尖,得到新的y尖,再与系统数据的y尖比较,反馈给下下此输入用于修正x尖。上图中,xk尖是预测的,他的不确定性会增加,所以方差比较大,看起来比较胖。棕色的yk是测量量,他也有误差,也是一个分布。
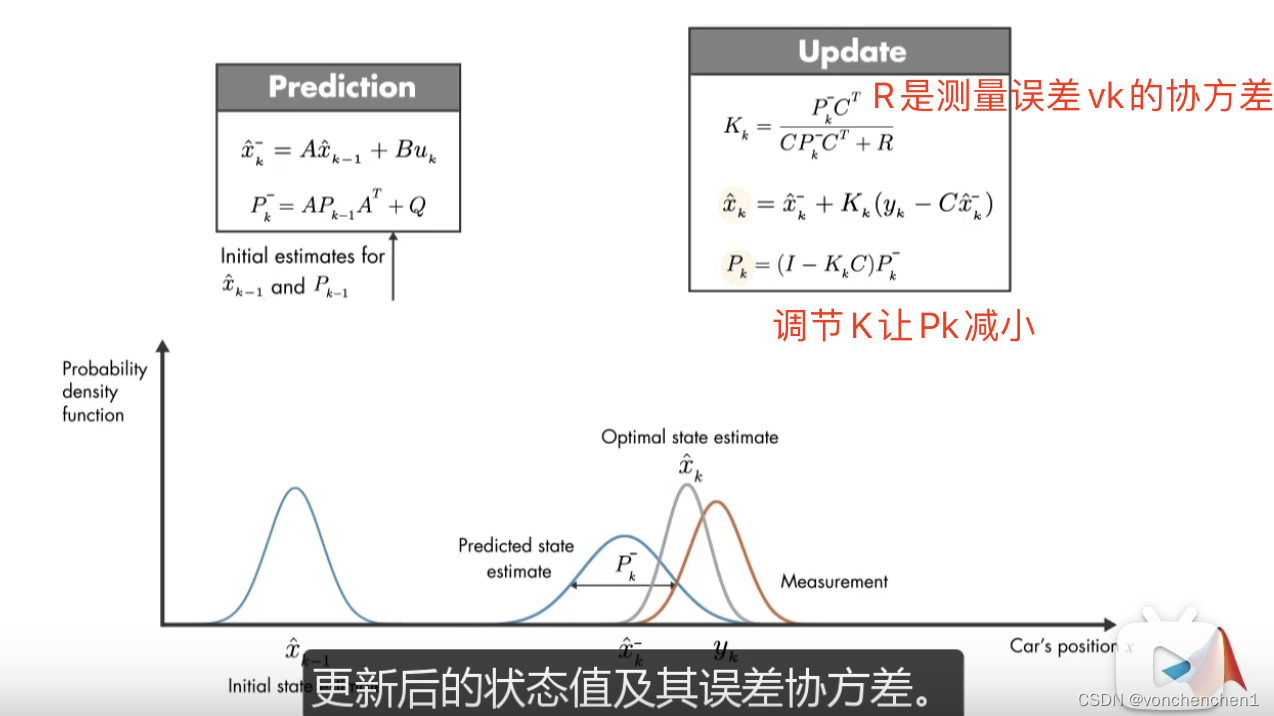
这个反馈修正过程的描述就是下面的式子,预测值与反馈值合起来,得到当前最优估计值。

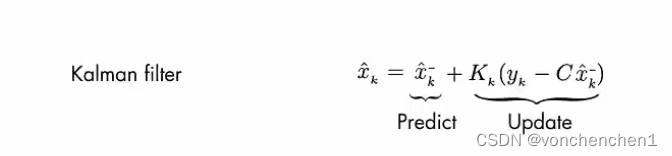
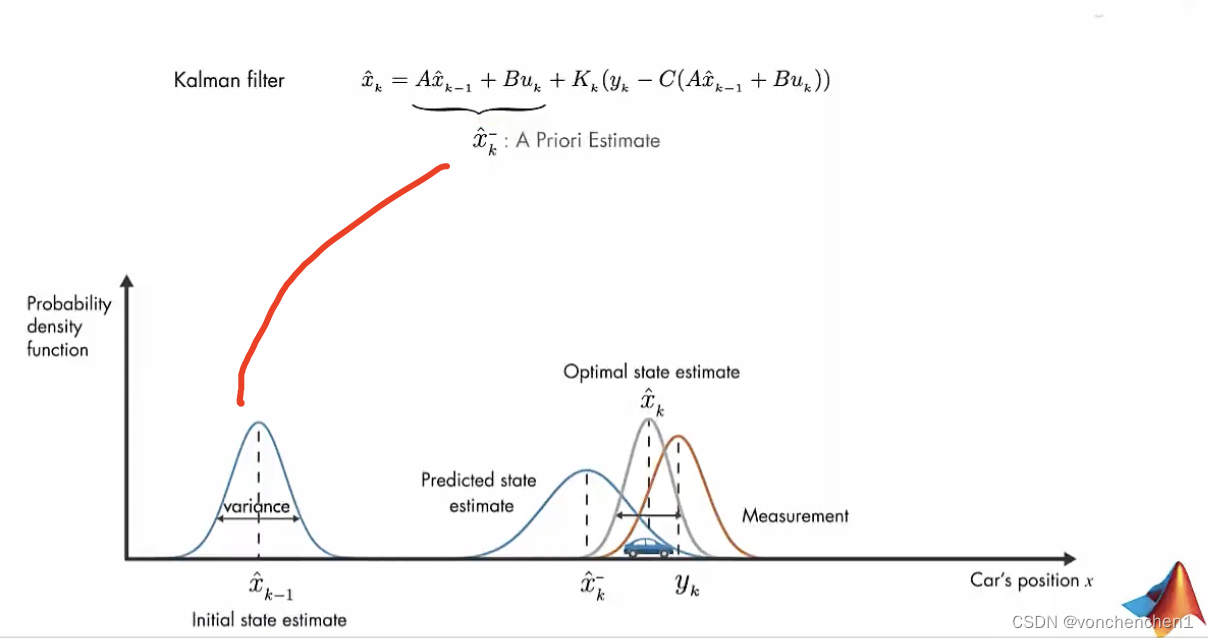
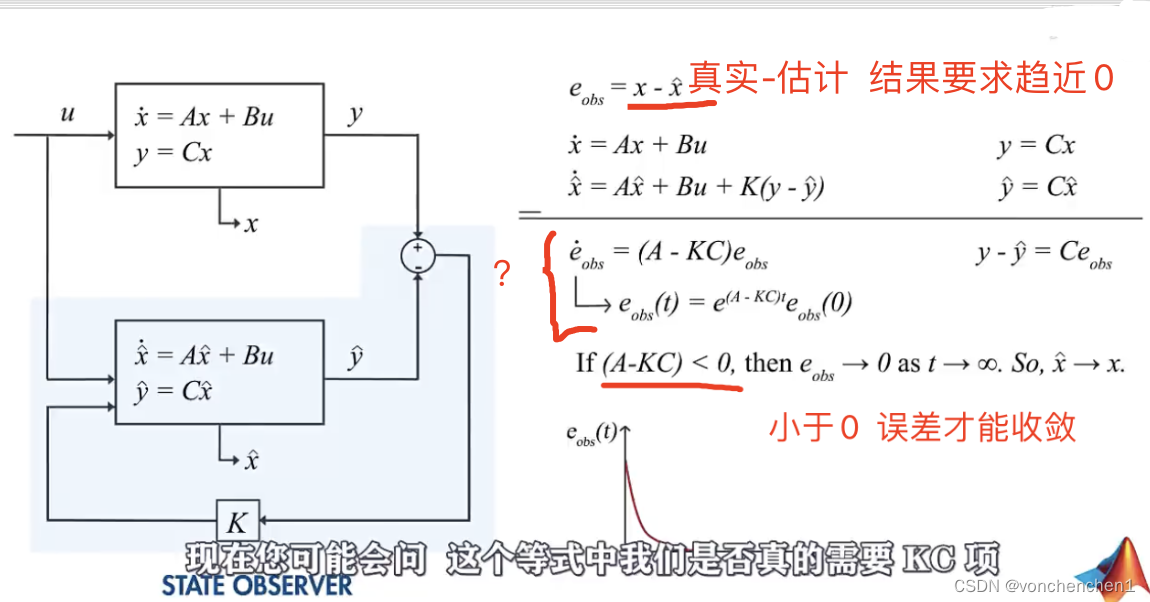
要看一下K是怎么求的
参数解释
wk 在建模过程中模型与真实系统的误差( Ax+Bu 对系统化简导致的误差 为系统噪声)
R是测量误差vk的方差 测量准确R小
Q是系统噪声wk的方差 模型准确Q小
P估计误差的协方差,Q、R、C参与计算得出P
这两个值可以调节,用来表示当前观测的准确程度和系统的噪声程度,传感器越准确,观测噪声越小,R可以调小,相信传感器的多。当前系统噪声越大,系统波动范围大,Q也就需要大些,相信上次预测的程度减小。最终目的是让P减小,通过K的不断调整,让P越来越小,状态预估不确定性降低,结果越来越准确。
A,B,C都是系统属性决定的。
R:我们观测到的每个数据,可以认为其对应某个真实的状态。但是因为存在不确定性,某些状态的可能性比另外一些可能性更高。我们将这种不确定性的方差为描述为Rk
模型也不准,观测也不准,那么该信谁,互相取多少作为最终占比呢。
2.一维例子
下面简单写了一个一维卡尔曼滤波的例子,用于直观上理解卡尔曼滤波。这里自己生产一个离散的正弦信号,然后给这个正弦信号叠加噪声,得到一个噪声信号。这个噪声新号就是我们的观测值,signal_x相当于我们给出的系统模型的输出,这里直接给A*上一次的输出,作为系统的预测输出,通过调节测量误差R和系统误差Q,观察输出与真实正弦信号的差别。
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
NUM = 10240
signal_std = [0]*NUM
signal_y_noise = 0.1*np.random.randn(NUM) #观测噪声
signal_y = [0]*NUM
signal_x = [0]*NUM
noise_system = 0.01*np.random.randn(NUM) #模拟系统输出的一些噪声,Q应该不止是这段噪声的方差
A = 1 #系统矩阵 假定就是1 预计输出信号和输入一致
B = 0 #控制矩阵
C = 1 #观测矩阵
#造一段加了系统噪声和观测噪声的传感器输出值
for i in range(1, NUM):
signal_std[i] = np.sin(0.01*i) #A=1和sin相差很多
#signal_std[i] = 1-np.exp(-0.05*i) #模拟电容充电
signal_y[i] = C*(A*signal_std[i] + noise_system[i])+ signal_y_noise[i]
#R Q 可以调节
#R测量误差 vk 的协方差矩阵 目前vk是我们自己造的signal_y_noise 可以直接求出R
#R = np.var(signal_y_noise) #这个值越大 越不相信测量值
R = 0.6
#Q系统噪声 wk 的协方差矩阵 目前wk是我们自己造的noise_system 可以直接求出 包括过程噪声,系统与真实的误差?
#目前看Q小 预测曲线越平滑,跟踪效果越差
#Q = np.var(noise_system)
Q = 0.01
#Q = 0
print("R 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4604
4604





 到【灌水乐园】发言
到【灌水乐园】发言







