




本研究解决了领域-类别增量学习问题,这是一个现实但富有挑战性的持续学习场景,其中领域分布和目标类别在不同任务中变化。为应对这些多样化的任务,引入了预训练的视觉-语言模型(
VLMs),因为它们具有很强的泛化能力。然而,这也引发了一个新问题:在适应新任务时,预训练VLMs中编码的知识可能会受到干扰,从而损害它们固有的零样本能力。现有方法通过在额外数据集上对VLMs进行知识蒸馏来解决此问题,但这需要较大的计算开销。为了高效地解决此问题,论文提出了分布感知无干扰知识集成(DIKI)框架,从避免信息干扰的角度保留VLMs的预训练知识。具体而言,设计了一个完全残差机制,将新学习的知识注入到一个冻结的主干网络中,同时对预训练知识产生最小的不利影响。此外,这种残差特性使分布感知集成校准方案成为可能,明确控制来自未知分布的测试数据的信息植入过程。实验表明,DIKI超过了当前最先进的方法,仅使用0.86%的训练参数,并且所需的训练时间大幅减少。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Mind the Interference: Retaining Pre-trained Knowledge in Parameter Efficient Continual Learning of Vision-Language Models

Introduction
监督学习技术在对所有数据完全访问的情况下训练网络,这可能导致在扩展网络以获取新任务知识时缺乏灵活性。持续学习(CL)作为一种解决方案应运而生,使得模型能够在陆续到达的数据上进行持续训练,同时保留所学的信息。传统的CL设置一般考虑的只新引入的类别或领域分布的变化,这称为类别增量学习和领域增量学习。然而,只考虑一种增量的现有工作限制了它们在复杂现实场景中的适用性。
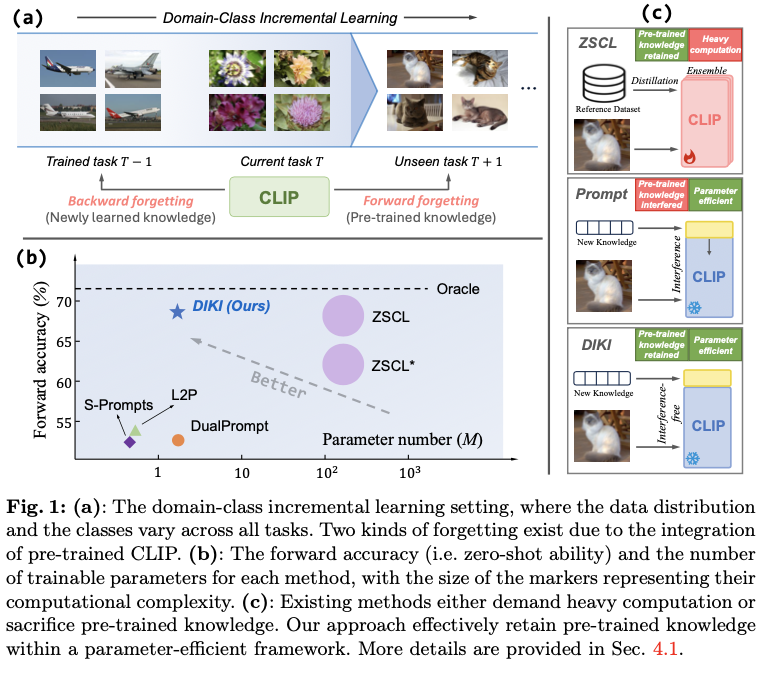
考虑一个更具挑战性的领域-类别增量学习(DCIL)设置,在该设置中,领域数据分布和待分类的类别在所有任务中可能不断变化,如图1(a)所示。在这种情况下,基于传统图像编码器的技术由于其不可扩展的分类头设计而无法实现。最近,对比训练的视觉-语言模型(VLMs)如CLIP的出现,使得解决这一要求高但实际的问题成为可能。VLMs是在大规模的图像-文本对上训练的,具有强大的零样本泛化能力,可以识别几乎无限的类别,应对这种严重的任务变化场景。
然而,使用视觉-语言模型引入了增量训练的新挑战。传统的持续学习方案旨在防止模型遗忘先前学习的知识,这被称为向后遗忘(忘记微调的知识)。现有的研究探讨了正则化机制、复习缓冲区和架构设计在减轻向后遗忘方面的潜力,并取得了令人鼓舞的成果。然而,当这些方法应用于视觉-语言模型时,出现了一种不同形式的灾难性遗忘:模型往往会遗忘在预训练阶段所学的知识,从而妨碍其强大的零样本泛化能力。这个问题被称为向前遗忘(忘记预训练的知识),因为它发生在VLMs对未知分布数据进行“向前”预测时。图1(a)展示了这两种遗忘类型。
最近的工作ZSCL尝试解决CLIP上的向前遗忘问题,引入了一个大规模的参考数据集来进行知识蒸馏,并结合了权重集成方案。然而,这种方法需要大量的计算和外部数据,在实际场景中可能不可行。同时,现有的基于VLM的参数高效持续学习方法主要利用提示调整机制,未能保留预训练知识,并导致零样本能力下降,如图1(b)所示。论文将这个问题归因于信息干扰:新引入的任务特定参数可能会干扰预训练知识。这些方法的示意图如图1(c)所示。
为了以计算和参数高效的方式缓解VLMs的向前遗忘问题,论文引入了分布感知无干扰知识融合(DIKI)框架。具体而言,将任务特定信息注入到冻结的VLM中,以便为每个任务高效地存储已学习的知识。
论文的贡献总结为三点:
- 引入了参数高效的
DIKI,以在DCIL设置下保留VLM中的预训练知识。它解决了信息干扰问题,降低了对大量计算和外部数据的需求。 - 为了缓解向前遗忘,
DIKI以完全残差的方式植入新知识,保持预训练知识不受干扰。凭借这种残差特性,进一步集成了分布感知融合校准,以提高在未见任务上的性能。 - 综合实验表明,与以前的方法相比,
DIKI以仅0.86%的训练参数和显著更少的训练时间实现了最先进的性能。
Preliminaries
持续学习旨在以顺序方式学习不同的任务,同时不忘记之前学到的知识。考虑到 N N N 个顺序到达的任务 [ T 1 , T 2 , ⋯ , T N ] \left[ \mathcal{T}^1, \mathcal{T}^2, \cdots, \mathcal{T}^N \right] [T1,T2,⋯,TN] ,每个任务 T i \mathcal{T}^i Ti 包含一个数据集 D i = { x j i , y j i } j = 1 N i D^i=\{x^i_j, y^i_j\}_{j=1}^{N^i} Di={
xji,yji}j=1Ni ,其中 x j i x^i_j xji 是一幅图像, y j i y^i_j yji 是当前数据集中对应的独热标签, N i N^i Ni 是图像样本的数量。此外,还包括一个类名集合 C i = { c j i } j = 1 N c i C^i=\{c^i_j\}_{j=1}^{N_{c}^i} Ci={
cji}j=1Nci ,将标签索引连接到VLMs使用的类别名称。
与之前的类别和领域增量学习设置不同,本研究强调了一种更实际的持续学习设置:领域-类别增量学习(DCIL)。在这个设置中,领域分布和需要识别的类别在不同任务之间不断变化,即 C i ≠ C j C^i \neq C^j Ci=Cj 和 P ( D i ) ≠ P ( D j ) \mathbb{P}(D^i) \neq \mathbb{P}(D^j) P(Di)=P(Dj) ,对于 i ≠ j i \neq j i=j ,其中 P \mathbb{P} P 表示任务数据集的数据分布。
在具有挑战性的领域-类别增量学习(DCIL)设置中,训练基于普通图像编码器的模型,如ResNets和ViTs,对于增量学习强烈变化的领域和类别并不实用。因此,引入了预训练的视觉-语言模型,因为它们具有强大的零样本迁移能力。CLIP包含一个图像编码器 f f f 和一个文本编码器 g g g ,它们被训练用于生成成对图像-文本样本的紧密对齐特征。在推理时, f f f 首先将输入图像 x x x 编码为特征向量 f ( x ) f(x) f(x) 。与此同时,潜在的类名被嵌入到一个模板中,例如“一个{ c c c }的照片”,然后由 g g g 编码以形成文本嵌入 { t j } j = 1 N c \{t_j\}_{j=1}^{N_c} {
tj}j=1Nc 。模型的预测通过图像嵌入与所有文本嵌入之间的最大相似性得分来确定 s j = ⟨ f ( x ) , t j ⟩ s_j = \Braket{f(x), t_j} sj=⟨f(x),tj⟩ ,其中 ⟨ ⋅ , ⋅ ⟩ \Braket{\cdot, \cdot} ⟨⋅,⋅⟩ 表示余弦相似度。
一系列研究开始探索在持续学习中参数高效微调的潜力,常见的做法是为每个任务学习和存储一组轻量级提示,在持续学习阶段形成一个“提示池”,表示为:
P = { P 1 , P 2 , ⋯ , P N } , where P i ∈ R l × d , \begin{equation} \mathbf{P}=\{P_1, P_2, \cdots, P_N\},\ \ \text{where}\ P_i\in \mathbb{R}^{l\times d}, \end{equation} P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









