




即插即用的方法
OVMR将新类别的多模态线索嵌入到VLM中,以增强其在开放词汇识别中的能力。它最初利用多模态分类器生成模块将示例图像嵌入到视觉标记中,然后通过推断它们与语言编码器的上下文关系来自适应地融合多模态线索。为了减轻低质量模态的负面影响,通过一个无参数融合模块根据每个类别对这些分类器的特定偏好,动态地将多模态分类器与两个单模分类器集成来源:晓飞的算法工程笔记 公众号
论文: OVMR: Open-Vocabulary Recognition with Multi-Modal References

Introduction
开放词汇识别旨在识别训练集之外的未见过的对象,这是一项具有挑战性的任务,因为模型对测试集中的新类别一无所知。除了尽量预训练具有较强泛化能力的模型外,最近的研究还通过将新颖类别线索嵌入预训练主干模型来开发更轻量级的策略。在这些工作中,一种流行的策略是在小规模任务特定数据集上微调一个通用模型。这种少样本微调策略能够有效优化任务特定参数,但耗时、缺乏灵活性,并且降低了泛化能力。
另一方面的研究是利用视觉-语言模型(VLMs)强大的泛化能力,通过提供图像或文本描述作为新类别线索。一些研究使用从文本描述中提取的文本嵌入作为新类别的分类器,但文本描述可能含糊不清,并且缺乏对视觉线索的详细描述,降低该分类器的区分能力。例如,bat这个词既可以指体育器材,也可以指动物。收集示例图像可能是另一个提供类别线索的选项,但图像样本可能表现出多样化质量,容易受到域差异、混乱背景等问题影响。
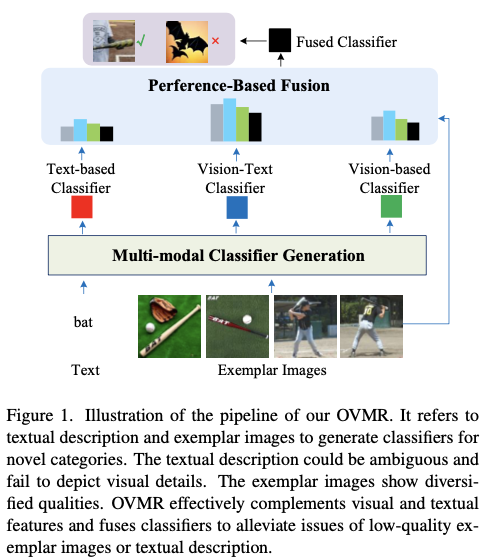
论文从不同的角度解决开放词汇识别问题,参考由文本描述和示例图像组成的多模态线索。换句话说,通过将文本描述和示例图像同时输入VLM,挖掘文本和图像的互补线索,从而学习更强大的新类别分类器。如图1所示,在此过程中,期望文本模态提供可泛化的语义线索,而示例图像则被分析以提取视觉细节,这对生成分类器的区分能力至关重要。为了缓解低质量文本或图像示例的负面影响,论文还评估了这些单模态和多模态分类器的性能,以自适应生成最终分类器。论文将提出的方法命名为OVMR。
如图1所示,OVMR以文本描述和描绘新类别的多个示例图像作为输入,包括两个模块来生成最终的分类器:
- 第一个模块动态地融合视觉示例和文本描述以生成多模态分类器,该模块一共包含两个单模态分类器和一个多模态分类器。首先利用轻量级视觉标记生成器从给定的示例中提取视觉标记,随后语言编码器通过推断它们之间的上下文关系来自适应地融合视觉和文本标记。这个多模态分类器生成模块由于其轻量级结构而非常高效,不需要训练特定于类别的参数,确保其良好的泛化性能和对各种类别可扩展性。
- 第二个模块通过基于偏好的融合将上述三个分类器生成最终的分类器。为了缓解低质量分类器的负面影响,论文提出了一种通过评估性能来进行动态融合的策略。由于有多个示例图像,将它们作为验证集来测试每个分类器的性能,最后作为学习融合权重的线索。如图
1所示,这个过程通过利用示例图像作为测试集来模拟测试阶段,可以有效地保证最终融合分类器的稳健性。
论文进行了大量实验来测试OVMR的性能,在11个图像分类数据集和LVIS目标检测数据集上均明显优于最近的开放词汇方法,也优于那些仅简单应用普通平均融合和文本引导融合来生成新分类器的相关工作。
论文的贡献可以总结为三个方面:
- 提出了一个灵活的即插即用模块,将新类别的线索嵌入
VLMs中,以增强它们在开放词汇识别任务中的能力。补充多模态线索相对于仅依赖视觉或文本线索带来了显著优势。 OVMR提出了一种从双模态输入生成稳健分类器的新型流程。它自适应地融合文本和视觉线索生成多模态分类器,并进一步提出了一个无需参数的融合模块,以缓解低质量模态的负面影响。- 广泛的实验表明,
OVMR在开放词汇分类和检测任务中表现出优越性能,展示了其在开放词汇识别中的潜力。
Related Work
Open-Vocabulary Classification
现有的开放词汇分类方法可以总结为三类,即预训练、提示学习和少样本适应方法。
许多预训练工作都致力于增强VLM在开放词汇分类中的能力,包括大型策划数据集和增强的训练策略。它们需要从头开始重新训练模型,这需要相当多的时间、样本和注释。
为了有效地增强VLM在分类中的能力,业界提出了各种prompt学习方法(编码文本和待分类图片,文本产生类别数个的输出与图片编码计算相似度,取最大的文本)。CoOp从少样本数据集中学习静态上下文标记,但倾向于过拟合训练类别,在未见类别上性能下降。为了缓解这一问题,CoCoOp从输入图像中获取动态的实例特定标记,旨在改善未见类别的分类。MaPLe致力于跨不同层次学习视觉和语言分支的多模式提示标记。这些方法需要在每个下游数据集上进行微调,而且倾向于过拟合已见类别,并且缺乏VLM中的泛化能力。
Few-shot分类包括一个训练阶段,在这个阶段,模型在一个相对大的数据集上学习,以及一个适应阶段,在这个阶段,调整学习的模型以适应之前未见任务的有限标记样本。在这个框架下,可以粗略地分为两种方法:元学习方法和非元学习方法。最近的一项工作揭示了少样本图像分类中的训练和适应阶段是完全解耦的。此外,它还表明,使用CLIP的训练算法预训练的视觉主干比以前的少样本训练算法表现更优秀。
在论文的工作中,将CLIP的预训练视觉主干作为基础模型,并评估不同的适应方法。这些适应方法包括无需训练的MatchingNet、Nearest Centroid Classifier(PN)以及需要训练的MAML、逻辑回归、余弦分类器、URL和CEPA。
Open-Vocabulary Detection
最近的许多工作旨在将VLM的开放词汇能力转移到目标检测领域。包括知识蒸馏和prompt优化在内的技术已被用来训练一个使用预训练VLM的开放词汇检测器。弱标记和伪框方法也被提出,以增强VLM的对象级别识别能力。此外,一些工作在VLM或SAM的预训练视觉主干顶部添加了新的检测头,无论是保持主干冻结还是可微调。最近,为开放词汇检测预训练视觉-语言模型是一个新方向。GLIP和DetCLIP在检测、定位和字幕数据的组合上进行训练,以学习单词-区域对齐。RO-ViT提出了预训练区域感知位置嵌入,以增强VLM在密集预测任务中的能力。
此外,最近的MM-OVOD和MQ-Det引入示例图像以增强用于开放词汇检测的文本分类器。然而,MM-OVOD同等对待两种模态,并直接计算新学习的基于视觉的分类器与现有文本分类器在VLMs中的算术平均值,以获得多模态分类器。MQ-Det使用文本特征作为查询,从示例图像中提取信息,并利用交叉注意机制优化原始文本分类器。这是基于文本模态更重要的假设。然而,受示例和文本质量的影响,对两种模态的偏好应在不同类别之间动态变化。
Differences with Previous Works
OVMR方法与先前的开放词汇分类和检测方法有几个不同之处:
- 与传统的需要大量资源的预训练方法不同,
OVMR使用在较小数据集上预训练的轻量级视觉令牌生成器。这使得能够在不完全重新训练模型的情况下,高效地将新的类别线索集成到模型中。 OVMR有效地避免了提示学习方法中固有的过拟合问题,因为它不学习类别特定的参数。此外,插拔属性使其能够在预训练后无缝地转移到各种任务中。OVMR利用语言模型的强大泛化能力,自适应地融合多模态线索。与像MM-OVOD和MQ-Det这样同等对待模态或优先考虑文本的方法不同,OVMR通过评估它们的性能进一步动态地集成单模态分类器和多模态分类器。这种两阶段的分类器生成流程对于具有低质量示例或文本描述的场景更加稳健,使得OVMR在各种任务中表现更好。
Methodology
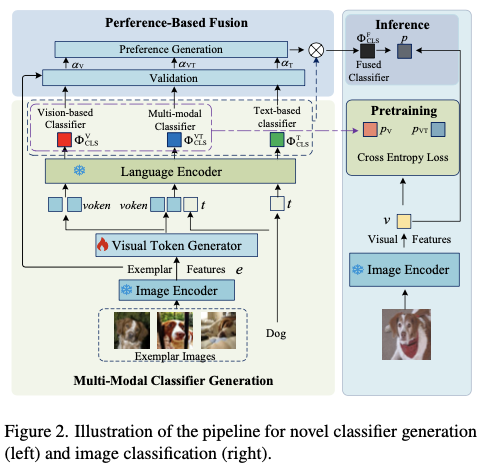
如图2所示,OVMR由两个主要模块组成。第一个是多模态分类器生成模块,利用可通用的语言编码器动态地集成文本和视觉示例。它还包括一个新预训练的视觉标记生成器,将示例图像嵌入到语言空间中。第二个模块是测试时用的基于偏好的融合模块,不引入任何可训练参数。
Multi-modal Classifier Generation
多模态分类器生成模块旨在通过自适应地融合视觉示例和文本描述来生成多模态分类器。对于感兴趣的新类别 C i C_i Ci ,将其视觉示例、目标图像和文本标记分别表示为 E i ∈ R M × H × W × 3 E_i\in \mathbb{R}^{M\times H \times W \times 3} Ei∈RM×H×W×3 、 V i ∈ R N × H × W × 3 V_i\in \mathbb{R}^{N\times H \times W \times 3} Vi∈RN×H×W×3 和 t i ∈ R L i × d t_i\in \mathbb{R}^{L_i\times d} ti∈RLi×d ,其中 M M M 是示例图像数量, N N N 是目标图像数量, L i L_i Li 是属于 C i C_i Ci 类别的文本标记长度, d d d 是标记嵌入的隐藏维度。此外,视觉示例 E i E_i Ei 和目标图像 V i V_i Vi 通过CLIP图像编码器 Φ C L I P − V \Phi_{CLIP-V} ΦCLIP−V 编码为示例特征 e i e_i ei 和视觉特征 v i v_i vi 。
为了利用语言编码器生成一个良好的多模态分类器,一个关键的先决条件是从视觉示例中提取出语言编码器能够理解的稳健的视觉标记,这些视觉标记需要准确地表示具有类别判别性的视觉细节。视觉标记生成器由 P P P 个与类别无关的可学习查询 q ∈ R P × d q \in \mathbb{R}^{P\times d} q∈RP×d 和四层全局自注意力Transformer块组成。通过利用可学习查询和示例特征之间的自注意力交互,可学习查询 q q q 自适应地从示例特征 e i e_i ei 中提取出属于 C i C_i Ci
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5593
5593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









