




即插即用的
PlugIR通过LLM提问者和用户之间的对话逐步改进文本查询以进行图像检索,然后利用LLM将对话转换为检索模型更易理解的格式(一句话)。首先,通过重新构造对话形式上下文消除了在现有视觉对话数据上微调检索模型的必要性,从而使任意黑盒模型都可以使用。其次,构建了LLM问答者根据当前情境中检索候选图像的信息生成关于目标图像属性的非冗余问题,缓解了生成问题时出现的噪音和冗余性问题。此外,还新提出Best log Rank Integral(BRI)指标,用于衡量多轮任务中的综合性能。论文验证检索系统在各种环境下的有效性,并突出了其灵活的能力。来源:晓飞的算法工程笔记 公众号
论文: Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach

Introduction
文本到图像检索是一个专注于在图像数据库中定位与输入文本查询相对应的目标图像的任务,由于视觉-语言多模态模型的发展,这一任务取得了显著进展。传统上,该领域的方法采用单轮检索方法,依赖于初始文本输入,这需要用户提供全面和详细的描述。最近,有研究提出了一种基于聊天的图像检索系统,利用大型语言模型(LLMs)作为提问者以促进多轮对话。即使用户提供了简单的初始图像描述,也能增强检索效率和性能。然而,这种基于聊天的检索框架面临一些限制,包括需要进行精细微调以充分编码对话式文本,这个过程既消耗资源又不适合可扩展性。此外,LLM提问者依赖于初始描述和对话历史,而没有查看候选图像的能力。仅根据LLM的参数化知识,可能生成目标图像无关的内容。
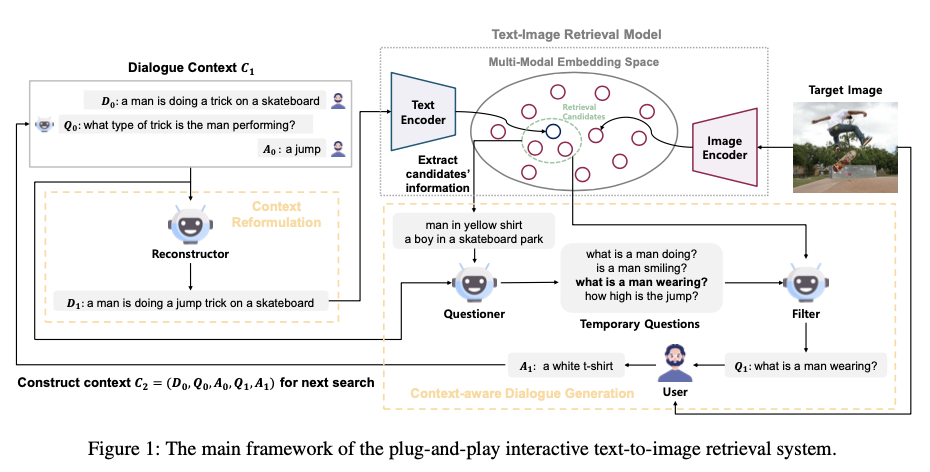
为了克服这些挑战,作者介绍了一种新颖的即插即用的交互式文本到图像检索方法PlugIR,与LLMs紧密耦合。PlugIR包括两个关键组件:上下文重构和上下文感知对话生成。利用LLMs的指令遵循能力,PlugIR将用户和提问者之间的交互上下文重构为适合预先训练好的视觉-语言模型的兼容格式。这个过程使得可以直接应用一系列多模态检索模型,包括黑盒变体,无需进一步精细调整。此外,作者的方法确保LLM提问者的询问基于检索候选集的背景,从而使其能够提出与目标图像属性相关的问题。在这个过程中,以文本形式将检索上下文注入LLM提问者作为参考输入上下文。随后,作者的方法还包括一个筛选过程,选择最符合背景、不重复的问题,简化搜索选项。
作者确定了评估交互式检索系统的三个关键方面:用户满意度、效率和排名改进的重要性,发现现有的指标,如Recall@K和Hits@K,在这些方面存在不足。例如,Hits@K未能考虑效率,而实际上通过较少的交互可以更好地定位目标图像。为了解决这些问题,作者引入了Best log Rank Integral(BRI)指标。BRI有效地涵盖了所有三个关键方面,提供了一个全面的评估,并不依赖于特定排名K,与Recall@K或Hits@K不同。我们在实证中证明BRI与人工评估更接近比起现有的指标。
在包括VisDial、COCO和Flickr30k在内的多个数据集上进行的实验表明,PlugIR在使用零样本或微调模型的现有交互式检索系统方面表现出显著优势。此外,作者的方法在应用于各种检索模型(包括黑盒模型)时显示出显著的适应性。这种兼容性扩展了其实用性,使其能够适应更广泛的应用和场景。
论文贡献如下:
-
提出了第一组经验证据,表明零样本模型在理解对话方面存在困难,并引入了一种上下文重构方法作为解决方案,不需要微调检索模型。
-
提出了一个
LLM提问者,旨在解决嘈杂和冗余问题导致的搜索瓶颈问题。 -
引入了
BRI指标,这是一种与人类判断相一致的新型度量标准,专门设计用于实现对交互式检索系统进行全面和可量化评估。 -
验证了论文的框架在各种不同环境中的有效性,突出了它多功能的即插即用能力。
Method
Preliminaries: Interactive Text-to-Image Retrieval
交互式文本到图像检索是一个多轮任务,从用户提供的简单初始描述 D 0 D_0 D0 开始。这个任务涉及用户和检索系统之间关于与 D 0 D_0 D0 (目标图像)对应的图像进行对话,形成一个上下文,在每个轮(回合)中被用作搜索目标图像的查询。在每一轮 t t t 中,检索系统生成关于目标图像的问题 Q t Q_t Qt ,用户以答案 A t A_t At 做出回应,从而为该轮创建对话上下文 C t = ( D 0 , Q 0 , A 0 , … , Q t , A t ) C_t=(D_0, Q_0, A_0, …, Q_t, A_t) C<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









