







 NestDNN是一个针对移动视觉系统的资源感知多租户设备深度学习框架,能动态调整资源和精度权衡。通过模型剪枝和复原生成多容量模型,提供灵活的资源精度权衡,有效利用有限资源,最大化并发应用程序性能。在评估中,NestDNN在推理精度、处理速度和能耗方面表现出优越性。
NestDNN是一个针对移动视觉系统的资源感知多租户设备深度学习框架,能动态调整资源和精度权衡。通过模型剪枝和复原生成多容量模型,提供灵活的资源精度权衡,有效利用有限资源,最大化并发应用程序性能。在评估中,NestDNN在推理精度、处理速度和能耗方面表现出优越性。
本文出自论文 NestDNN: Resource-Aware Multi-Tenant On-Device Deep Learning for Continuous Mobile Vision,主要提出了NestDNN,一个将运行资源动态性考虑在内的框架,动态地选择最优的资源精度权衡,最大化所有并发应用程序的性能。
移动视觉系统通常会同时运行多个应用程序,由于启动新的应用程序、关闭现有的应用程序和应用程序优先级改变等事件,它们在运行时的可用资源是动态的。本文我们提出了NestDNN,一个将运行时资源的动态性考虑在内的框架,对于移动视觉系统可支持资源感知性多租户的设备深度学习。NestDNN支持每个深度学习模型来提供灵活的资源和精度间的权衡,在运行期间,它动态地为每个深度学习模型选择了最优的资源和精度间的权衡,从而更好地适应系统可用运行资源的需求。这样做,NestDNN有效地利用了移动视觉系统的有限资源,最大化所有并发运行的应用程序的性能。
文章目录
一、简介
- 当深度学习芯片出现时,这里有一个显著的兴趣点,利用设备上的计算资源来执行移动系统上的深度学习模型,并且没有云支持。与云相比而言,移动系统被有限的资源所约束,而深度学习模型被认为是资源需求型的。为了支持设备上的深度学习,常见的做法是对深度学习模型进行压缩来减少它的资源需求,同时有一个可容忍的精度损失作为权衡。但是它有一个缺点,就是在应用开发阶段基于一个静态的资源预算,压缩模型的资源精度权衡已经被预先确定好,在应用部署后也被固定下来。然而,移动视觉系统在运行时的可用资源总是动态变化的。当运行时的可用资源不能满足压缩模型的资源需求时,当前同时运行的应用程序会发生资源争夺,这迫使流媒体视频以更低的帧频率处理。另外,当运行时的额外资源可用时,压缩模型并不能利用额外的可用资源来恢复所牺牲的精度。
- 我们提出了NestDNN,一个将运行资源的动态性考虑在内的框架,可以支持用于移动视觉系统的资源感知多租户设备间的深度学习。NestDNN使用灵活的资源精度权衡替代了固定的资源精度权衡,并为在运行时的每个深度学习模型动态地选择最优资源精度权衡,将模型的资源需求和系统的可用运行时资源相匹配。通过这样做,NestDNN能够有效地利用移动系统的有限资源,来最大化所有并发运行的应用程序的性能。
- NestDNN设计的关键技术挑战:(1)支持一个深度学习模型去提供灵活的资源-精度权衡;(2)为每个并发运行的深度学习模型选择一种资源精度权衡。为了解决第一个挑战,NestDNN部署了一个新的模型剪枝和复原方案,将一个深度学习模型转换成一个单一的紧缩多容量模型。这个多容量模型由一系列派生模型组成,每一个都提供一个唯一的资源精度权衡,并且较小容量的派生模型和较大容量的派生模型共享它的模型参数,在不占用额外的空间时来获得更大的容量。通过这样做,多容量模型能够提供使用一个紧缩的内存占用来提供不同的资源精度权衡。为了解决第二个挑战,NestDNN将每个并发运行的应用程序的每个派生模型的推理精度和处理延迟编码成一个成本函数,然后部署一个资源感知的运行时调度方案,它为每个深度学习模型选择最优的资源精度权衡,并决定被分配到每个模型运行资源的最优数量,从而最大化总体推理精度和最小化所有并发运行程序的总体处理延迟。
- 为了评估多容量模型的性能,我们在6个移动视觉应用程序上进行评估,这些应用程序基于2个广泛使用的深度学习模型(VGGNet和ResNet)以及6种常用于计算视觉系统的数据集。为了对资源感知运行调度方案进行评估,我们合并了2个广泛使用的调度方案,并实现NestDNN和6个运行在3台智能手机上的移动视觉应用程序。
- 结果展示:(1)多容量模型能够提供嵌套在一个单一模型上的灵活的和最优的资源精度权衡,使用参数共享,它可以显著地减少模型内存占用和模型切换开销。(2)资源感知运行调度方案胜于在相同调度方案上的资源不可知副本,在推理精度上实现了4.2%的增加,视屏帧处理速率上2倍的增加,以及能耗上1.7倍的减少。
二、NestDNN回顾
-
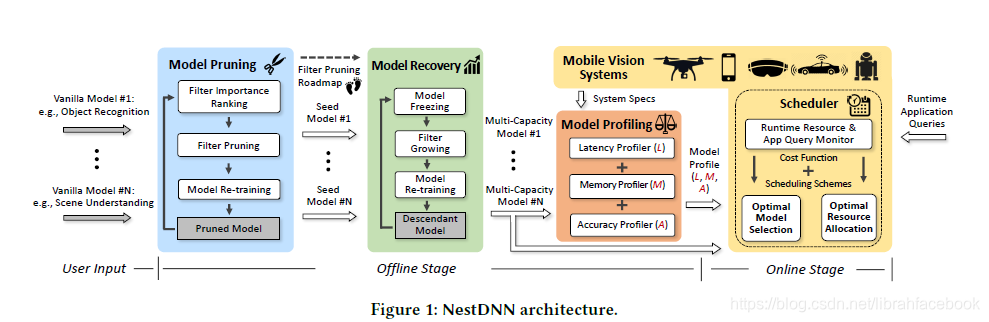
NestDNN体系架构:NestDNN被划分成一个离线阶段和一个在线阶段,其中离线阶段由三部分组成,分别是模型剪枝、模型复原和模型分析。
(1)在模型剪枝过程中,NestDNN部署了一个最先进的 Triplet Response Residual(TRR) 方法来对一个给定的深度学习模型的过滤器进行排序,排序基于它们的重要程度,然后迭代地修改过滤器。在每次迭代过程中,较少重要的过滤器被剪掉,修剪过的模型被重新训练来补偿由过滤器修剪引起的精度损失。当修剪过的模型不能满足由用户设定的最小精度目标时停止迭代。其中最小的修剪模型被称为seed 模型,一个过滤器修剪路线图被建立起来,在路线图上的每个足迹都是一个带有过滤器修剪记录的修剪模型。
(2)在模型复原过程中,NestDNN部署了一个新的模型 freeze-&-grow 方案以一种迭代方式来生成多容量模型。模型复原使用seed 模型来作为开始点,在每次迭代过程中,模型 freezing 被第一个应用于冻结所有模型过滤器上的参数。通过以逆序的方式沿着过滤器修剪路线图,过滤器growing被用于添加修剪后的过滤器。这样一个有着较大容量的派生模型被生成,它的精度通过再训练被重新获得。通过重复这个迭代过程,一个新的派生模型在先前的基础上生成。于是,最终的派生模型有着所有先前模型的容量,被命名为多容量模型。
(3)在模型分析过程中,给定一个移动视觉系统的规格,一个用于每个多容量模型的分析被生成,包括推理精度、内存占用和它每个派生模型的处理延迟。
-
对于在线阶段,资源可知运行调度器连续地监视着改变运行资源的事件,一旦这样的事件被检测到,调度器会核查所有并发运行的应用程序的分析,为每个应用程序选择最优的派生模型,然后分配运行资源的最优数量到每个所选择的派生模型,从而最大化总体推理精度并最小化所有这些应用程序的总体推理延迟。
三、NestDNN设计
-
基于过滤器的模型剪枝:通过修剪滤波器,模型大小(模型参数)和计算成本(浮点数计算)都被减少了。过滤器剪枝的关键是确定较少重要的过滤器,通过修剪这些滤波器,一个CNN模型的大小和计算成本都可以被有效地减少。为此,我们提出了一个过滤器重要性排序方法(TRR)来衡量过滤器的重要性,并根据它们的相关重要性程度来对滤波器进行排序。TRR方法的关键点是:如果一个过滤器能够提取特征映射,并且这些特征映射对于区分图像归属到不同的类是有用的,则这个滤波器是重要的。换言之,如果从图像中提取到的特征映射属于同一类的要比属于不同类的更相似,则这个滤波器是重要的。我们设置一个三元组{ a n c , p o s , n e g anc,pos,neg anc,pos,neg},第一个代表基础图像,第二个代表积极图像,第三个代表消极图像,其中 a n c anc anc和 p o s pos pos来自于同一类, n e g neg neg来自于不同类, F ( . ) F(.) F(.)表示生成的特征映射,因此过滤器i的TRR被定义为: T R R i = ∑ ( ∣ ∣ F i ( a n c ) − F i ( n e g ) ∣ ∣ 2 2 − ∣ ∣ F i ( a n c ) − F i ( p o s ) ∣ ∣ 2 2 ) TRR_i=\sum(||F_i(anc)-F_i(neg)||_2^2-||F_i(anc)-F_i(pos)||_2^2) TRRi=∑(∣∣Fi(anc)−Fi(neg)∣∣
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 34万+
34万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









