






提到图生图,可能很多同学首先想到的是使用 ControlNet,但除此之外也有不少其它图生图功能和模型值得去了解和应用。
现在网上不少分享各种效果很好但结构复杂的图生图工作流程,节点数百个,其文件能达到大几百K。看着有种高级感,但其实都是一个个普通的图生图工作流程融合而成,没有什么高深的知识在内。ComfyUI 没有三维软件和特效软件那么难学,它是一个很基础的工具,只是需要更灵活的去运用。对于初学者来讲,开始就直接去套用那些复杂的工作流,对学习没有任何益处。
本文介绍包括 ContrlNet 在内的多种图生图的基本用法,旨在帮助新同学尽可能的掌握 ComfyUI 图生图功能的使用,内容也会随着相关技术的更新和本人认知的跟进而不定期更新。
文中所用案例均使用 SD1.5 和 SDXL 等早期模型,这些模型比较快速和基础,掌握了这些,Flux 等其它模型的图生图用法也就自然而然的会运用了。
文中会放上部分所有涉及到的工作流,建议新同学根据截图手动连节点,我的截图又大又清晰,这是个很好的学习和熟练的过程。
本文部分非人物图片素材源自网络,侵删。
原生图生图功能
工作流分享:
https://www.alipan.com/s/BFtSjHEw9XV
https://pan.quark.cn/s/5c6af5dae790
1. 基础图生图
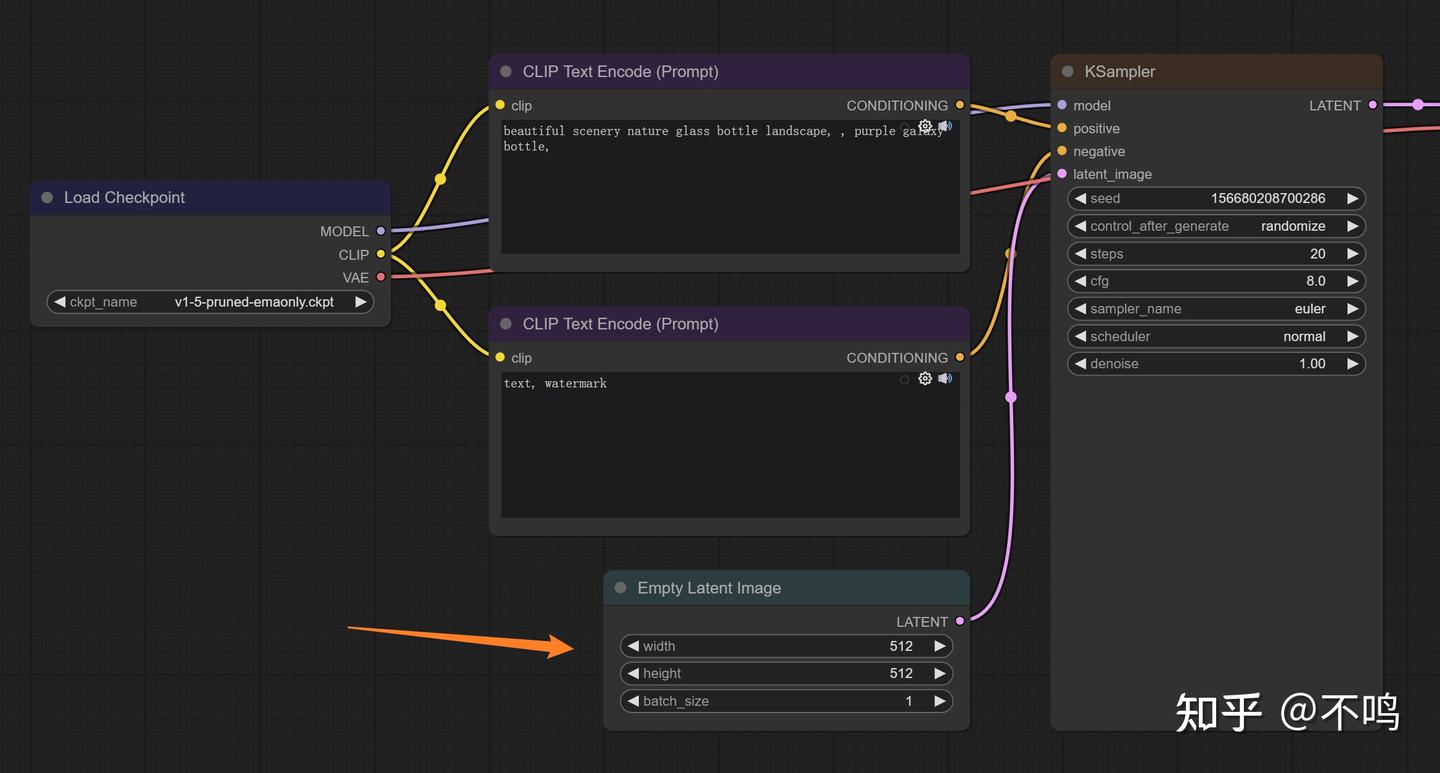
在文生图工作流中,有一个 Empty Latent Image 节点,它相当于向采样器提供了一个只有尺寸信息的空图像。当我们把它替换为带有像素的普通图像时,就相当于将文生图转为图生图了:
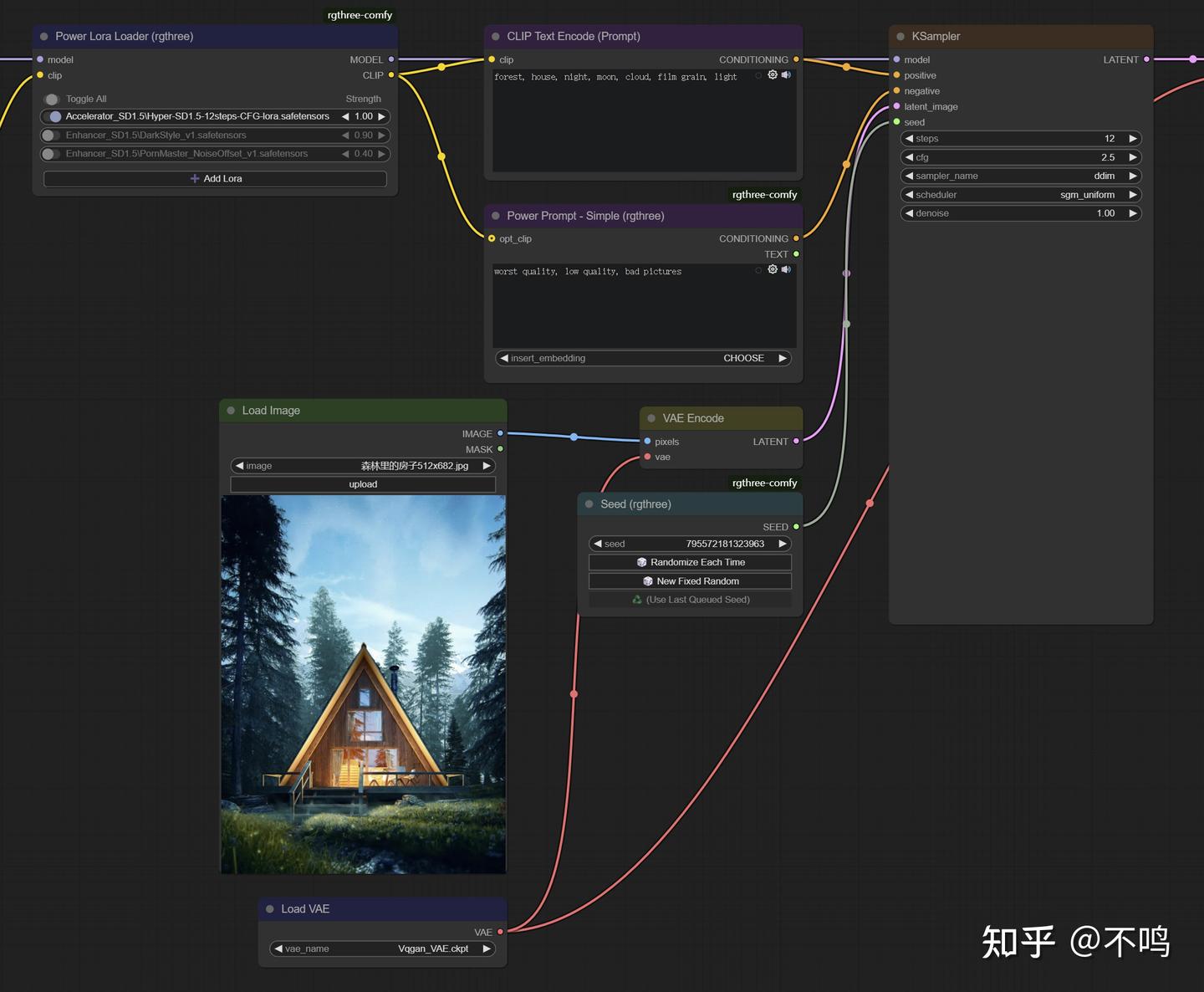
需要在图片和采样器之间加一个编码器节点 VAE Encode,它的作用是将图像转换为 Latent Image 传递给采样器。记得连接 VAE,靠 VAE 来编码的。
然后根据图像内容写几个简单的提示词,跑张图试试。
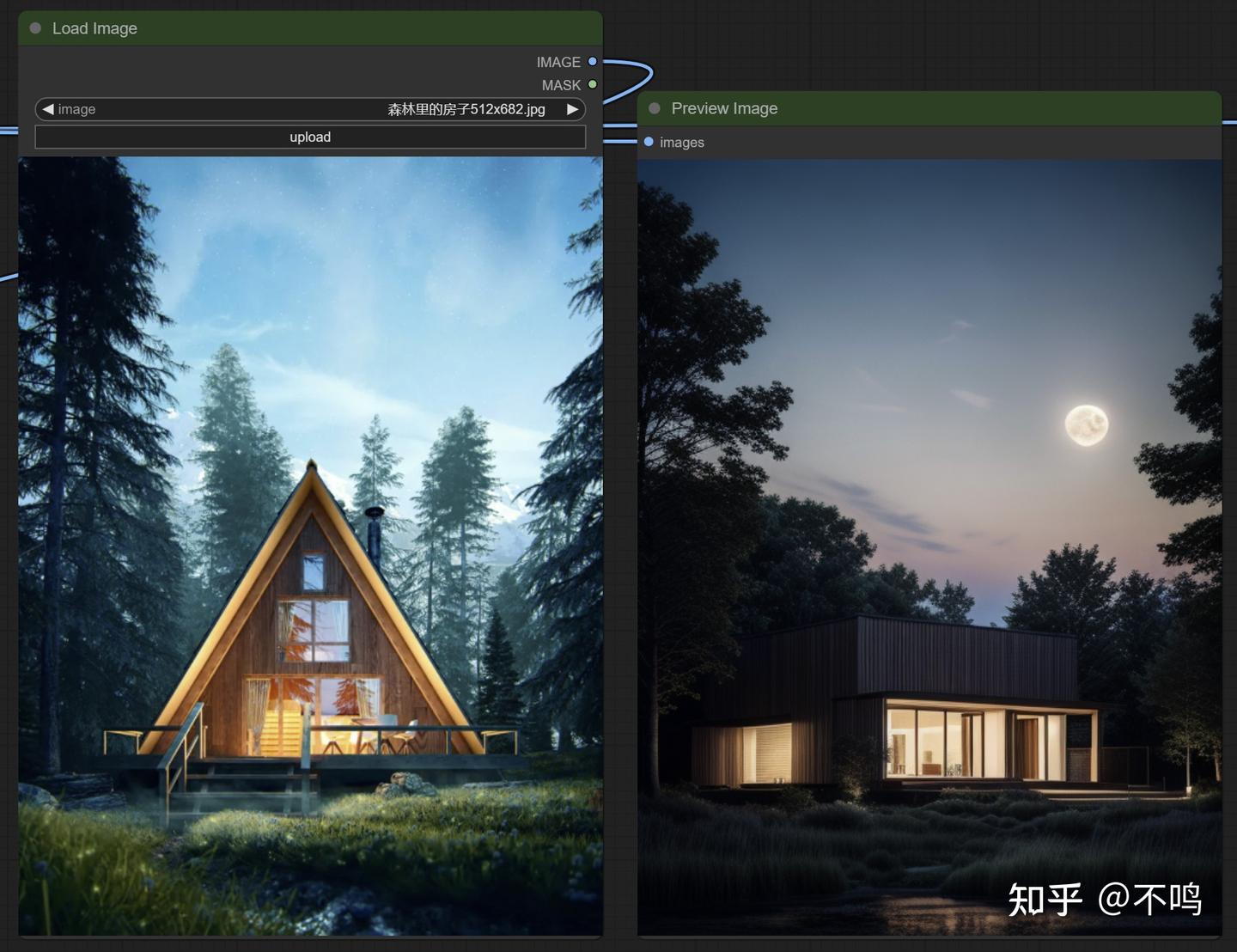
右边为生成的图像,这结果,好像跟左边的原图没啥关系。现在我们把采样器的 denoise 值从原默认的 1 降到 0.7 看看。
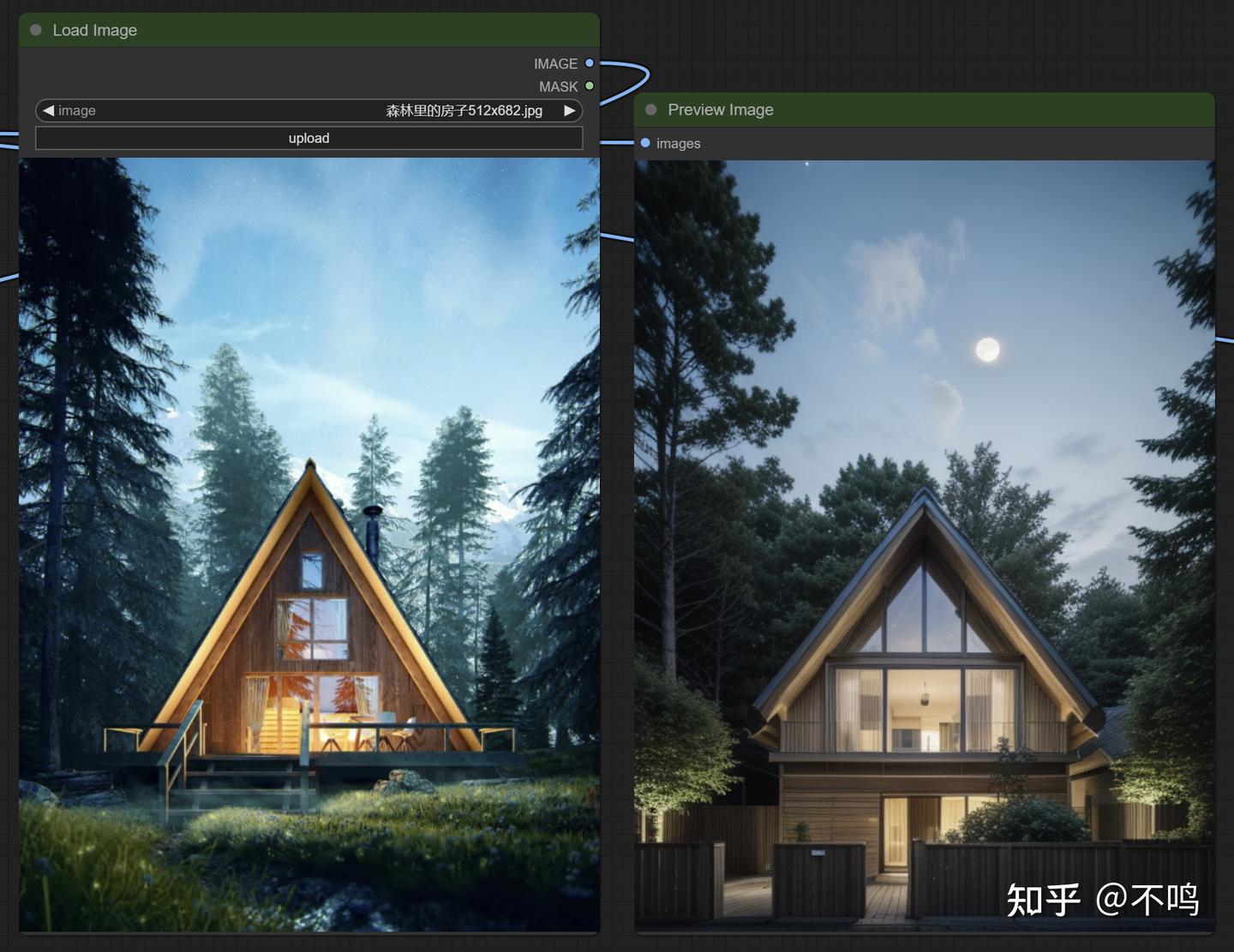
现在结果与原图关联度已经很高,构图相近。
denoise 的本意是降噪,它在此处的作用是擦除 Latent Image 的信息,最大值为 1,值越低,代表擦除的输入图像信息越少,生成的图片也就与其关联度越高。
你也可以用不同风格的模型或提示词来进行图生图,会得到一些有意思的效果。
2. 基础内部重绘
将图生图中的 VAE Encode 改为 VAE Encode for inpainting 节点,就成了一个基础的内部重绘工作流程。
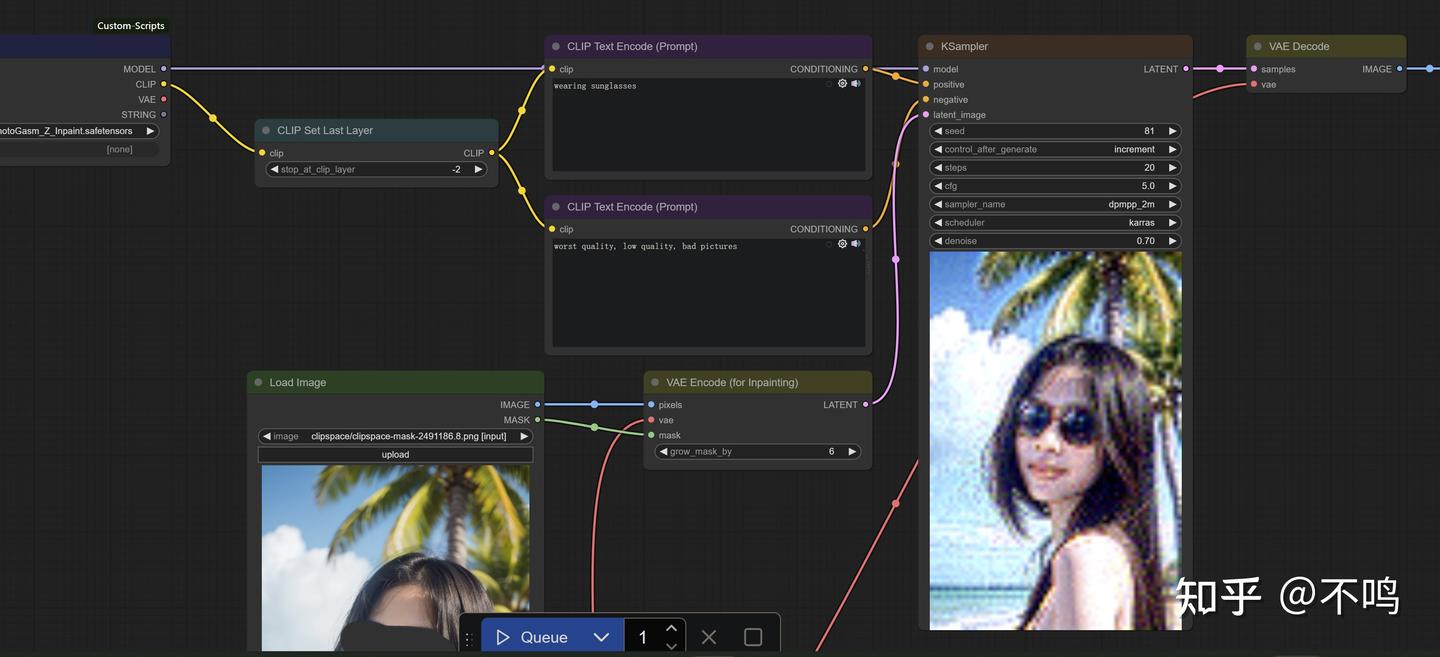
grow_mask_by 的值越低,重绘部分与原图的结合部会越明显。
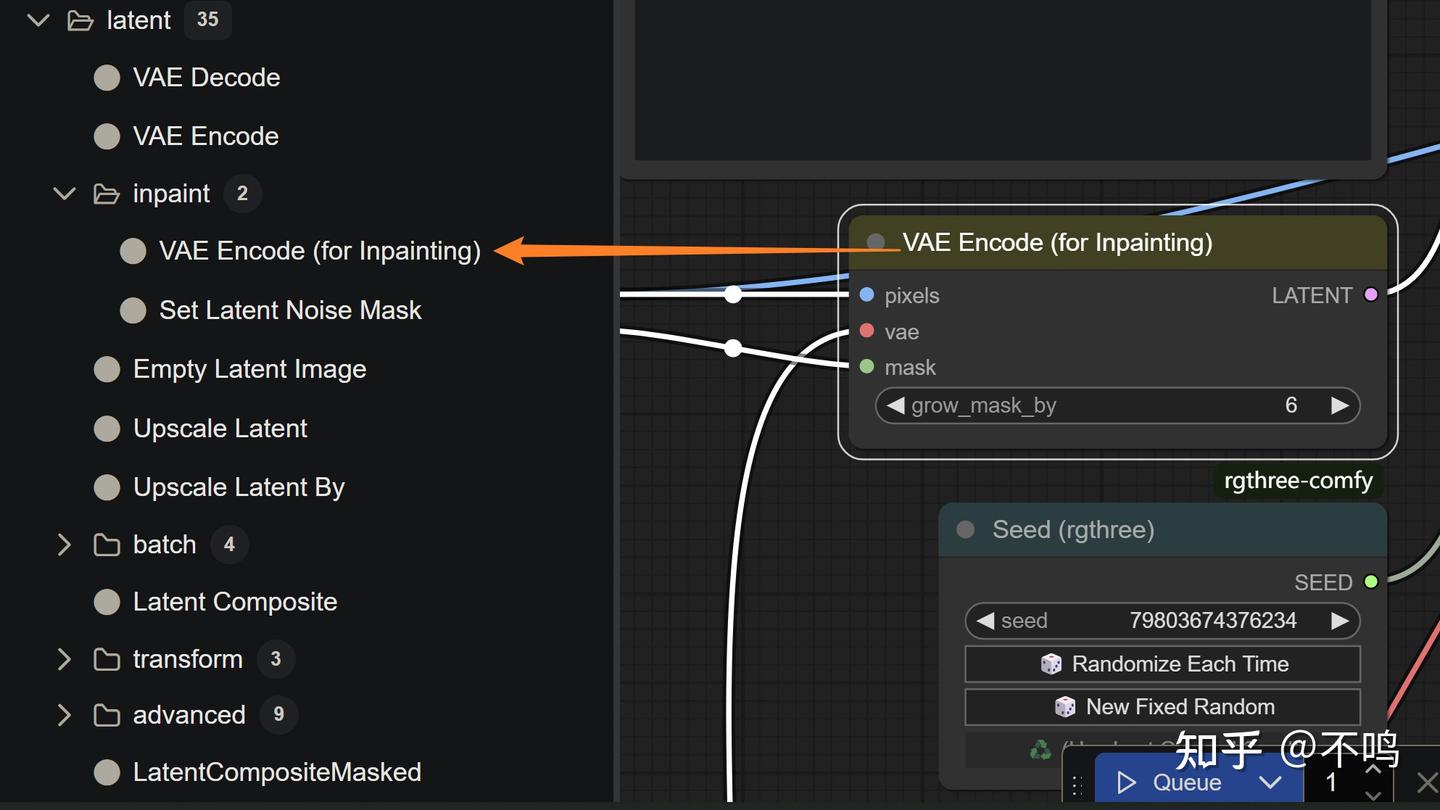
右键点击输入的图片,Open in MaskEditor 打开图片。
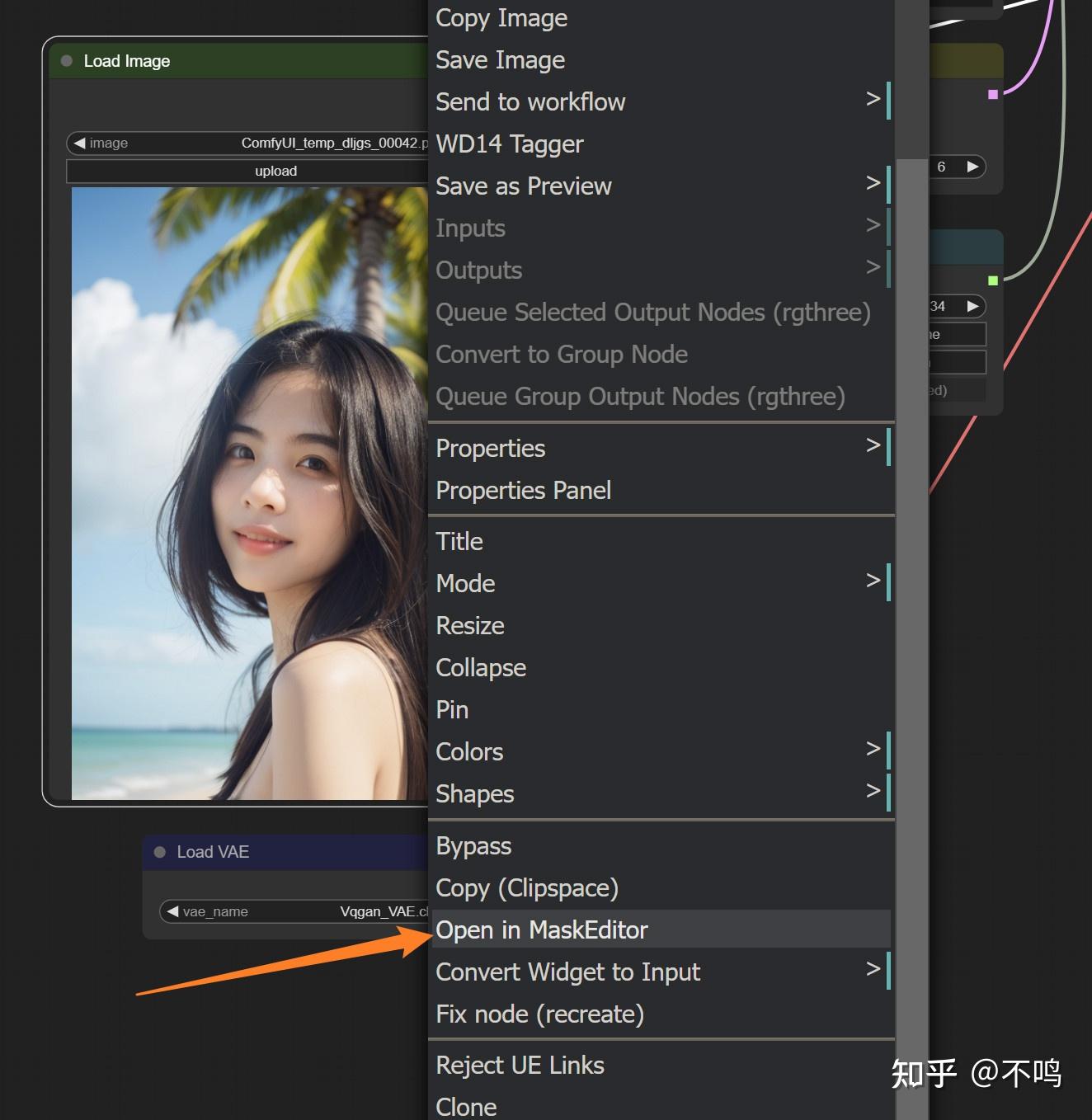
在输入图片上右键选择 Open in MakeEditor,将要重绘的部分给完全涂抹,然后保存。
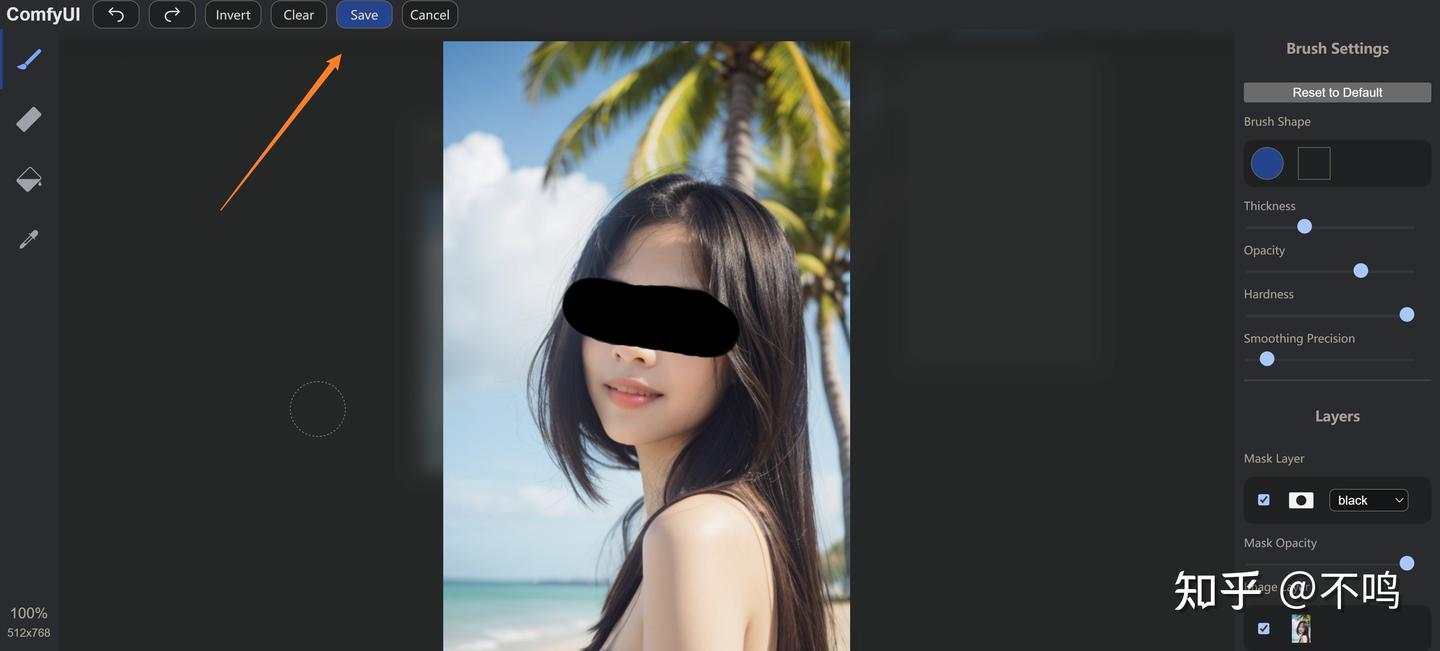
采样器的 denoise 设置为 0.7,提示词:wearing sunglasses,给人物戴上太阳眼镜。

注意基础模型需要用 Inpaint 模型,平常使用的文生图模型用于内部重绘的话效果并不好,提示词也要尽可能的简洁。
3. 基础外部扩展
其实图像外部扩展的本质也是内部重绘,它是先增加原图片的尺寸,然后再以扩充的空白区域为蒙版进行内部绘制。需要在输入图片和编码器间加一个 Pad Image for Outpainting 节点。
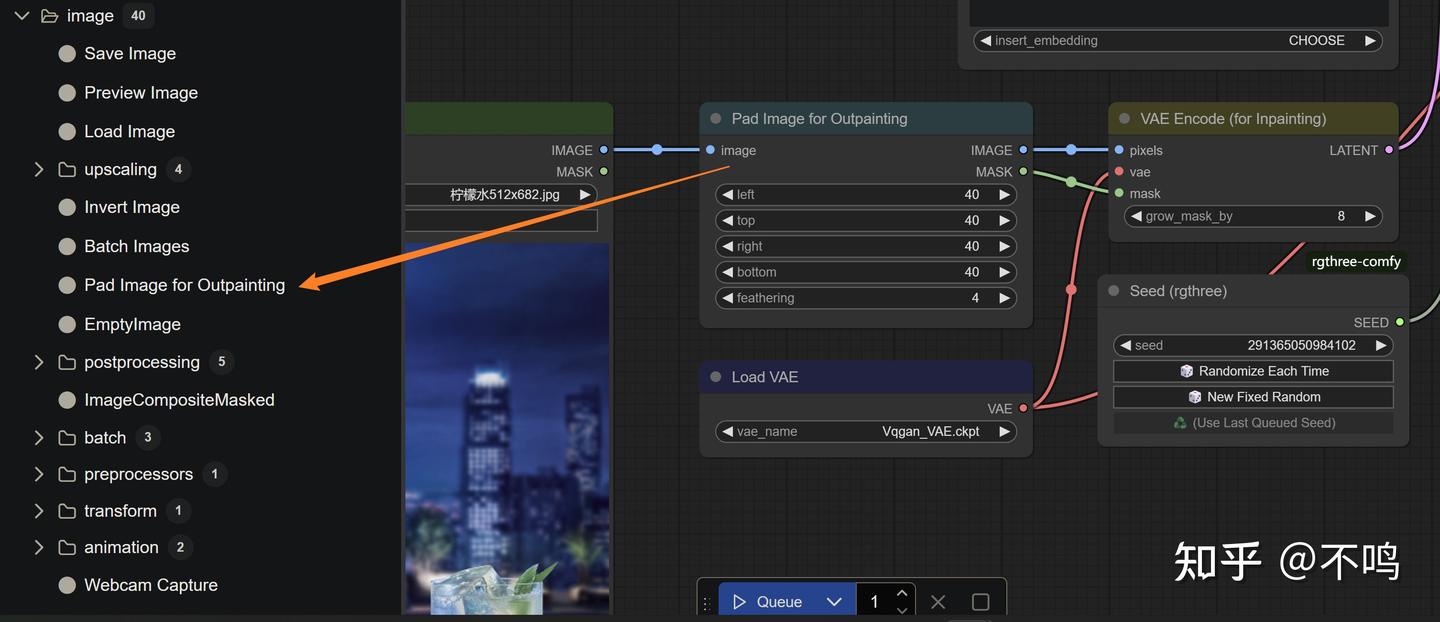
left、top、right、bottom 表示向四个方向扩展图像尺寸,以 8 为单位增减。feathering 表示羽化度,好将重绘的内容与原图更好的融合。采样器的 denoise 设为 1,因为不需要保留扩展区域的空白内容。
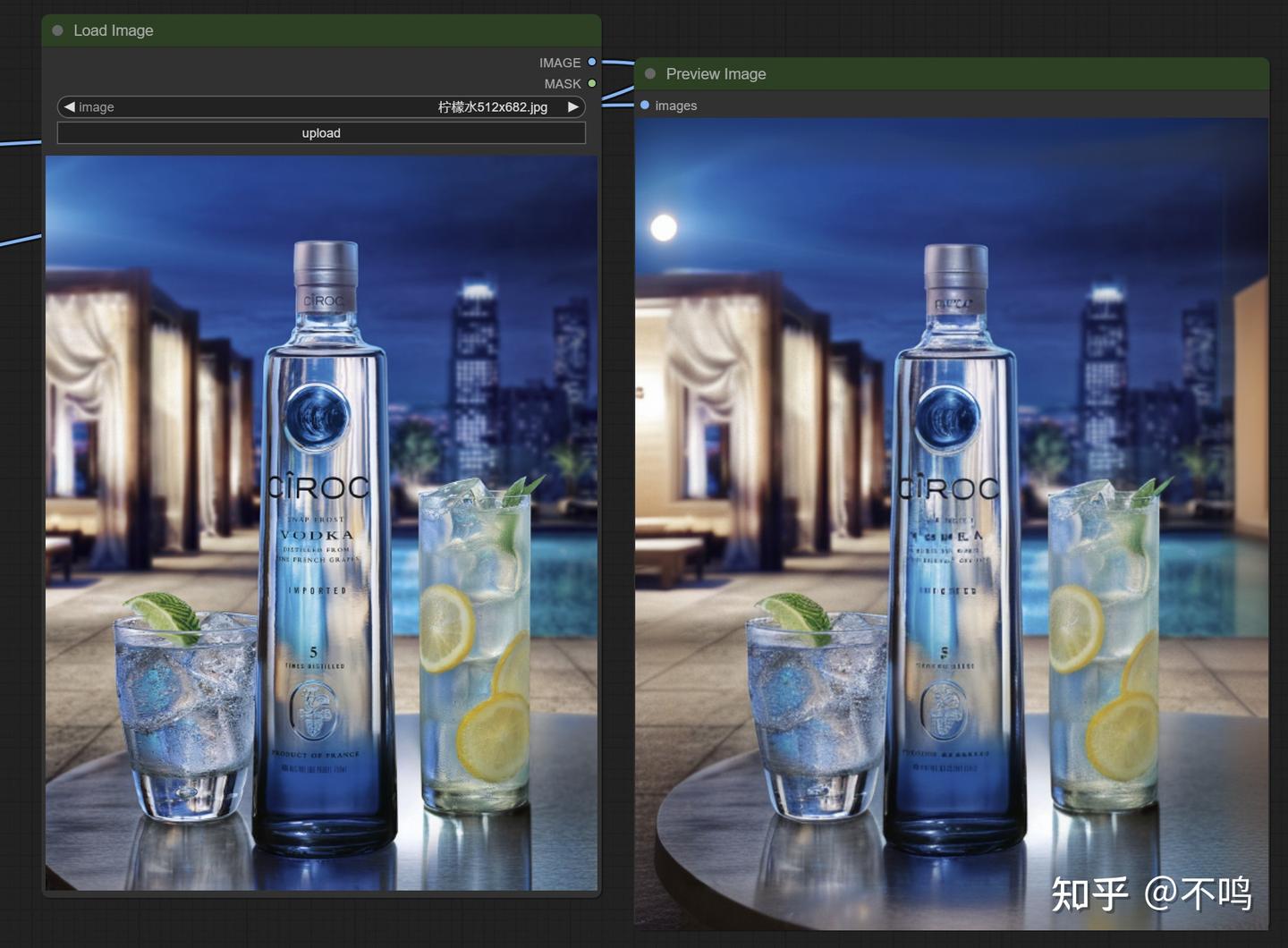
将图片四周扩展 40 像素,简单提示词:Beautiful night view。例图的结果还算可以了,内部重绘需要多尝试、碰运气。
4. unCLIP图片概念
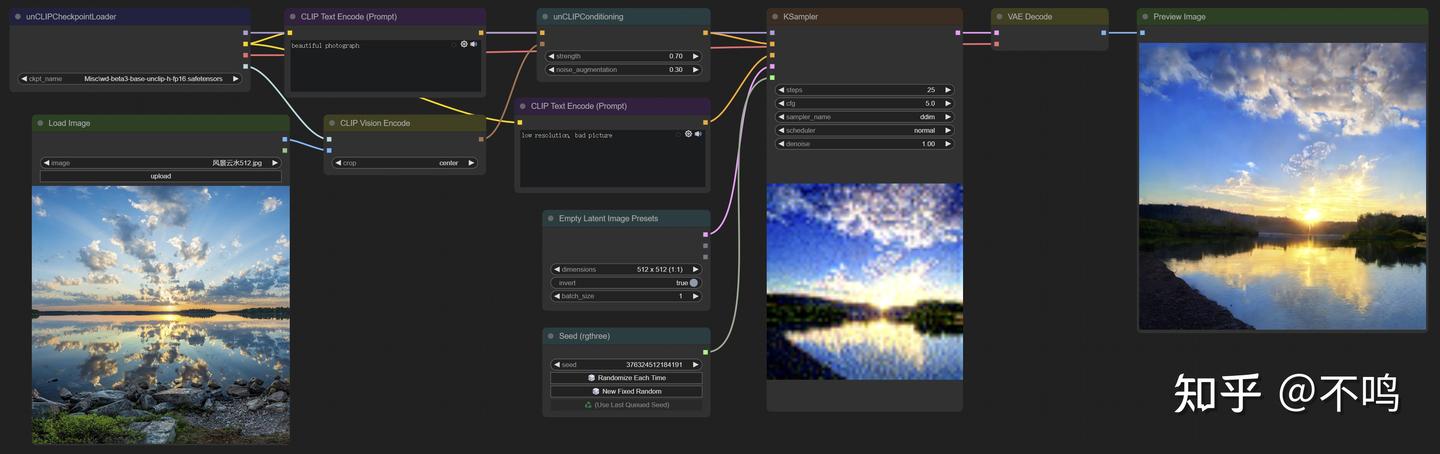
unCLIP 模型用以从输入的图像中随机选取元素重新生成图片。可以输入单张图,也可以多张图片融合。它选取的内容可以是输入图片中的具体事物,也可能是色彩信息。另外,生成的图片尺寸与原图尺寸无关,可以直接输入大图。
可以输入单张图片:
也可以用 2 张图进行融合:
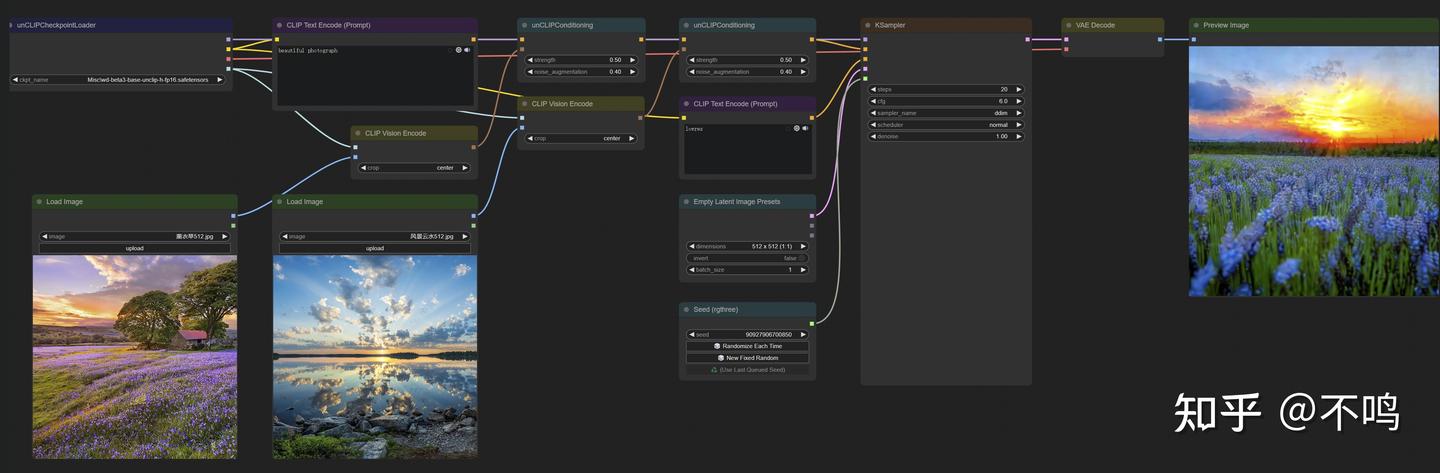
我做了不少尝试,但结果大都不如意。或许可以为用户提供一些概念上的灵感和参考,观者可以根据自己的需求来尝试。
提示词需要尽量简洁,因为该流程本就是随机生成图片的。
unclip 模型放入 checkpoints 文件夹,下载地址如下。这些模型产出的效果并不相同,但也不需要全都留用,也可以自己尝试后再决定保留哪些模型:
https://hf-mirror.com/stabilityai/stable-diffusion-2-1-unclip/tree/main
https://hf-mirror.com/comfyanonymous/illuminatiDiffusionV1_v11_unCLIP/tree/main
https://hf-mirror.com/comfyanonymous/wd-1.5-beta3_unCLIP/tree/main
5. Revision图片概念
该流程也是提取图像元素以随机生成图片的,效果较之 unCLIP 要好很多。
可以用单张图片:
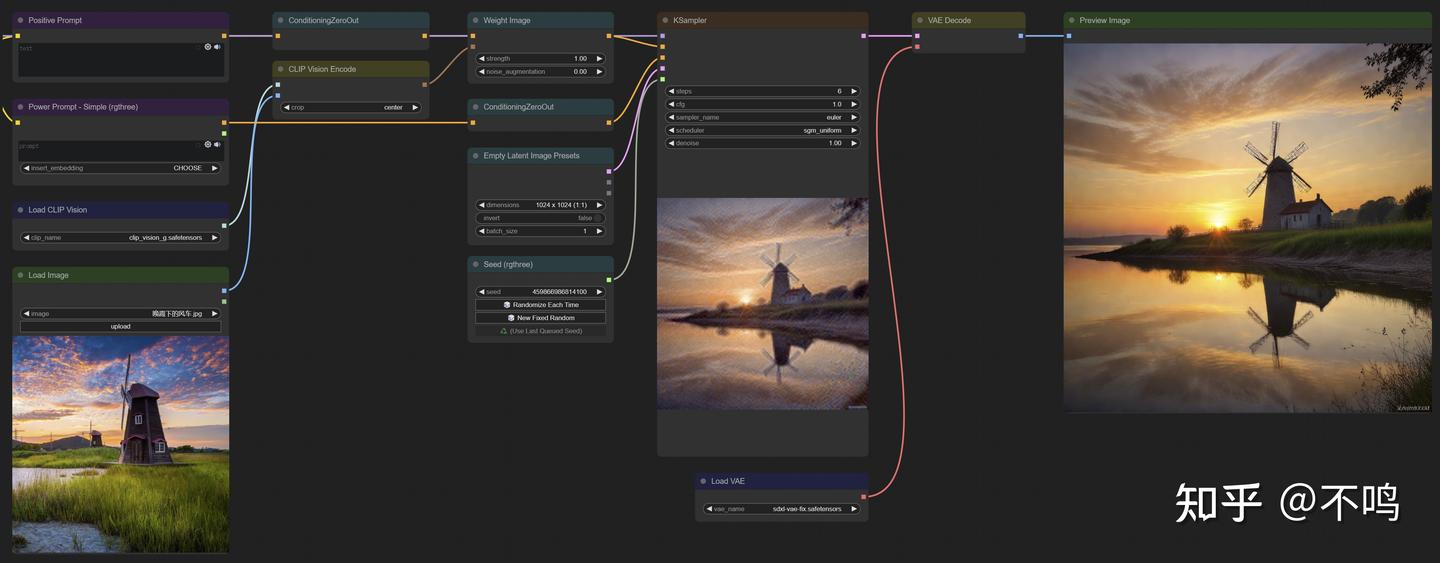
也可以混合两张图片的元素:
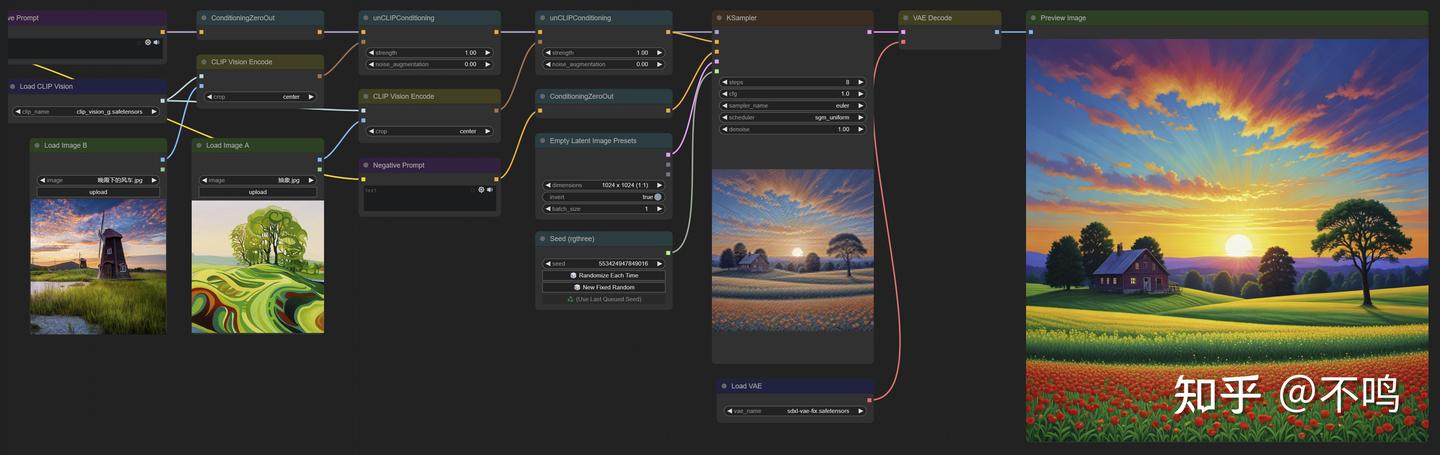
此方法使用 SDXL 模型,不需要提示词,需要下载 clip_vision_g 模型放置于 clip_vision 文件夹内。下载地址:
https://hf-mirror.com/comfyanonymous/clip_vision_g/tree/main
6. CosXL图片风格转换
与 ControlNet 的 Pix2Pix 一样,只需简单的提示词就可以对图片进行相应的处理,在原图基础上转换为想要的风格或添加元素,该模型的效果要比 ControlNet 模型好些。
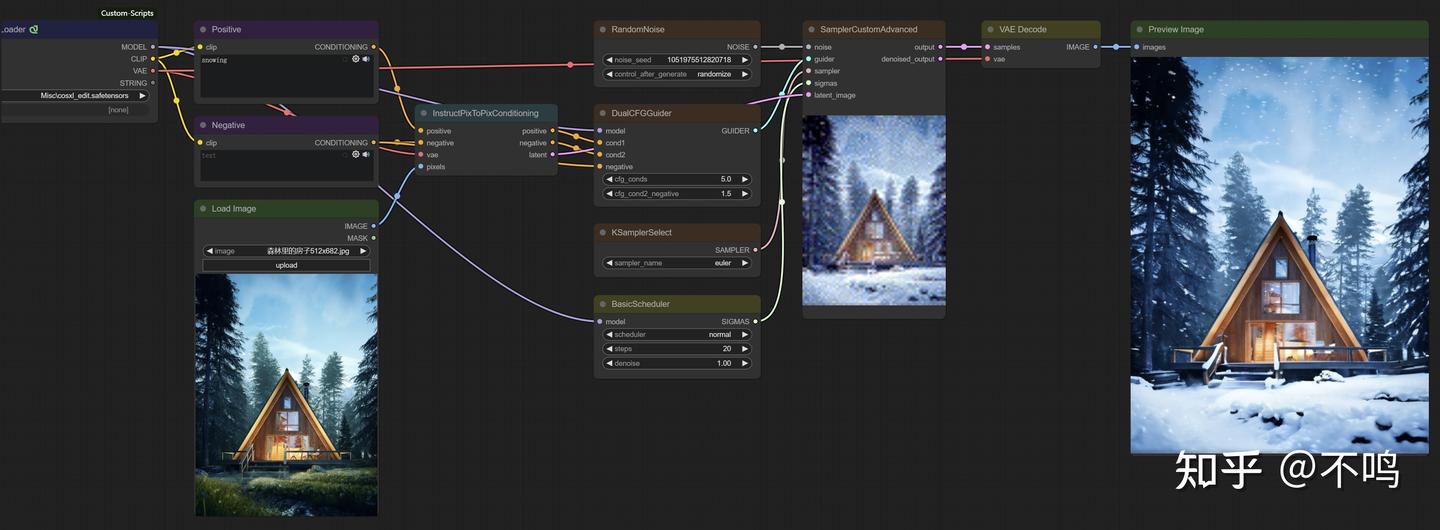
在 StabilityAI 的抱脸上下载 cosxl_edit 模型需要登录账号,所以无法通过镜像网来下载,这对网络不通的用户来说有点难,不过有好心人上传了这个模型:
https://hf-mirror.com/thesudio/CosXL/tree/main
Inpaint-Nodes
这是一款用于 SDXL 的 Inpaint 插件。我们在使用内部绘制功能时,需要相应的 Inpaint 模型。但喜欢的模型并不一定有训练内部绘制版本,虽然融合 Inpaint 模型并不难,但一个 SDXL 就近 7 个G,太占用硬盘。而这个插件可以使用常规的文生图模型用于内部绘制。
https://github.com/Acly/comfyui-inpaint-nodes
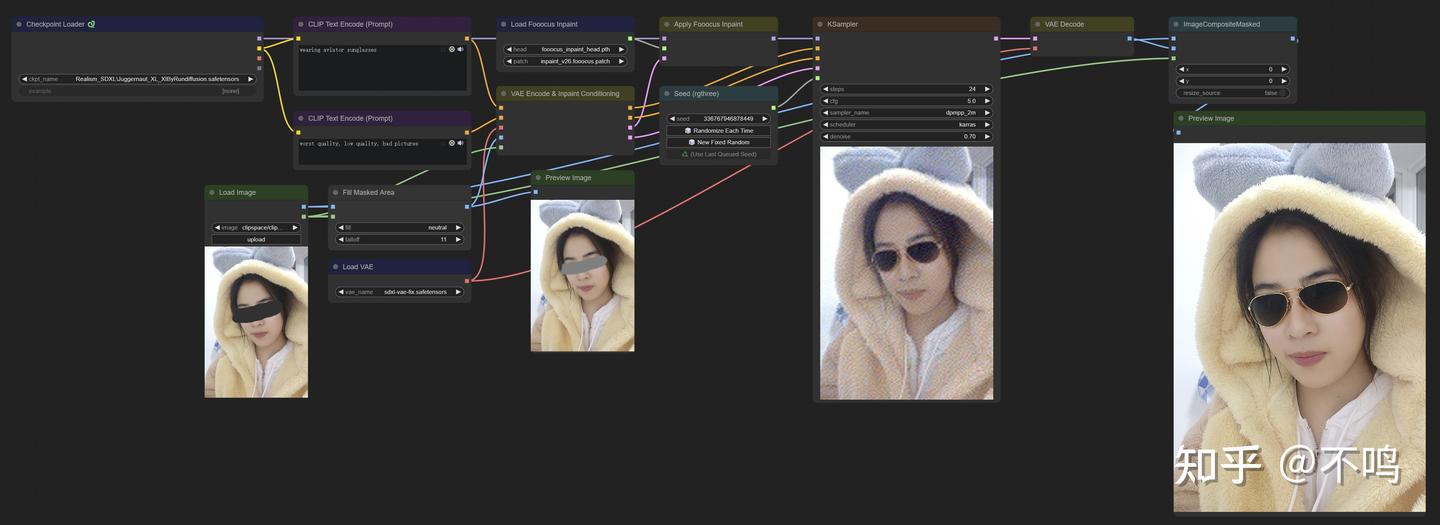
使用该插件的内部重绘与原生内部重绘不同之处在于,采样器的 denoise 要设置为 1。该插件可以让我们自由的选择模型来内部重绘,也节省了硬盘。但从使用经验看,它插件并不能明显提升重绘质量,还是需要多多尝试呀。
插件文件中有几个工作流示例,简单易用。
ControlNet
1. ControlNet预处理插件的安装
在 Stable Diffusion 兴起之初,正是有了 ControlNet 的出现,才让 SD 除了好玩儿之外有了更多的实际运用。关于 ControNet 的教程颇多,但大多是 WebUI 的,虽说使用原理相同,但其使用方法对新同学来说还是需要摸索的,毕竟不像 WebUI 选项卡模式那般简单。
ComfyUI 中带有 ContrlNet 节点,我们平时说的 ControlNet 插件,其实是预处理器。该插件的实际作用是对输入的图片进行预处理,将其转换成 ControlNet 模型读的懂的形式:
https://github.com/Fannovel16/comfyui_controlnet_aux
2. ControlNet使用前的准备
ControlNet 模型下载:
ControlNet 模型下载,放置在 ComfyUI\models\controlnet 中:
https://hf-mirror.com/comfyanonymous/ControlNet-v1-1_fp16_safetensors/tree/main
该页面中是 fp16 的模型,与 fp32 相比,体积小了一半,出图结果没有明显差异。页面上有 136M 的 rank126 模型,和 723M 的模型相比,它的效果通常会差些,但在 tile 功能的使用上,rank126 似乎效果更好。
本文只针对 SD1.5 模型讲解,虽然 SDXL、Flux 等模型的效果更好,但 SD1.5 的 ContrlNet 模型更全面更集中,依然是初学者需要去掌握的内容。不过一通则百通,之后转换到 SDXL、Flux 等模型时也就水到渠成。
预处理模型下载:
在插件页面的最下方,有一堆预处理模型,这个很重要,也很容易被忽略导致出图错乱。如果不自己下载的话,在初次使用相关预处理器时会自动下载。但是对大多网络不通的用户来讲,是下不动的。
第一个方法是可以将 ComfyUI 连接的 huggingface 地址改到其镜像网,具体操作可以看我另一篇文章《连接HuggingFace及更改缓存路径》。第二个方法就是自己手动下载预处理模型到对应文件夹。
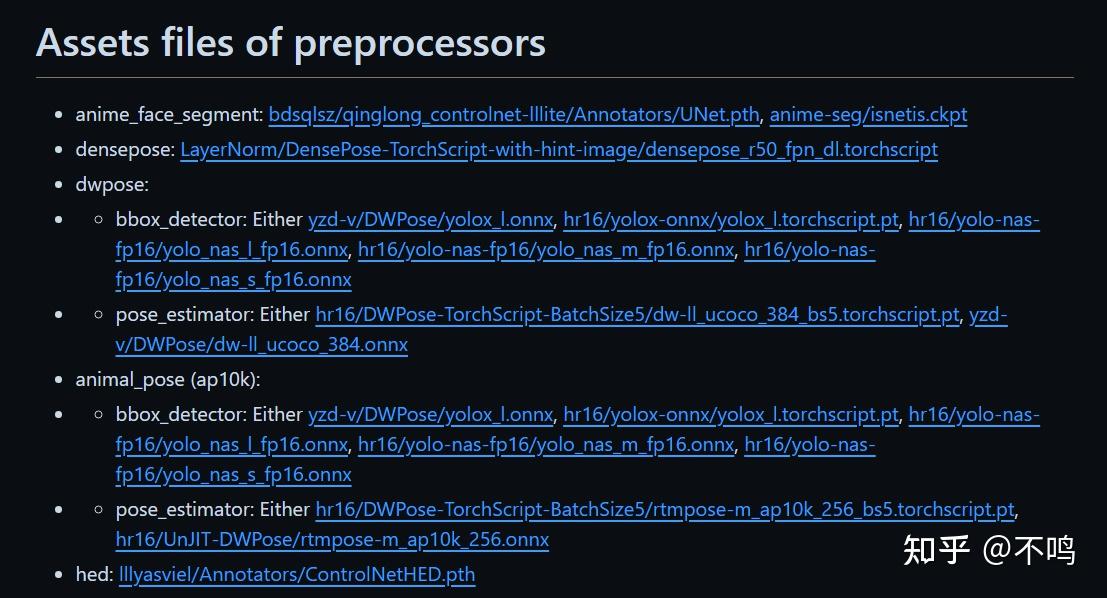
点开连接后,将 https://huggingface.co/ 后 /blob 前的地址复制下来,粘贴到下方镜像站的后面即可正常打开,然后下载相应的文件。
https://hf-mirror.com
下载好的预处理文件需要放到 confyui_controlnet_aux 插件内,新建一个 ckpts 文件夹:
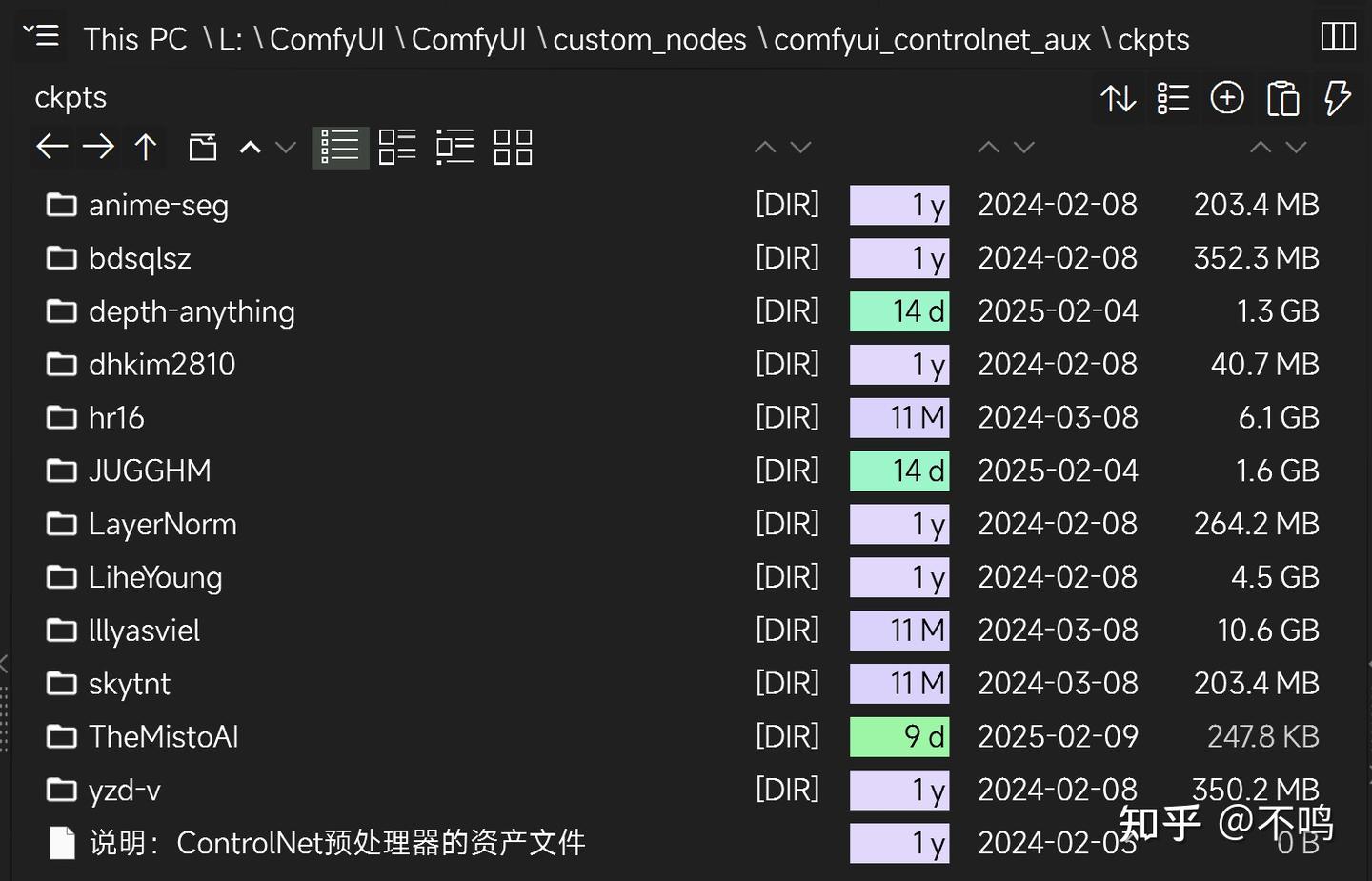
文件放置位置需要特别注意,举个例子:
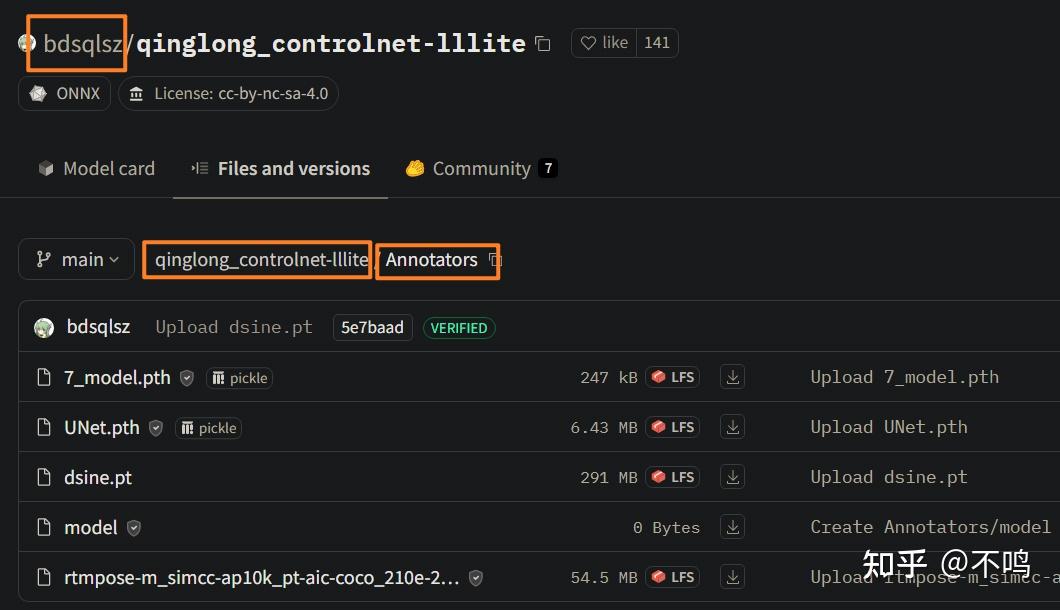
在下载页面上,可以看到要下载的文件处在 bdsqlsz --> qinglong_controlnet-lllite --> Annotators 之下,那么在 contronet 插件内的 ckpts 文件夹中,它的放置顺序也是如此:
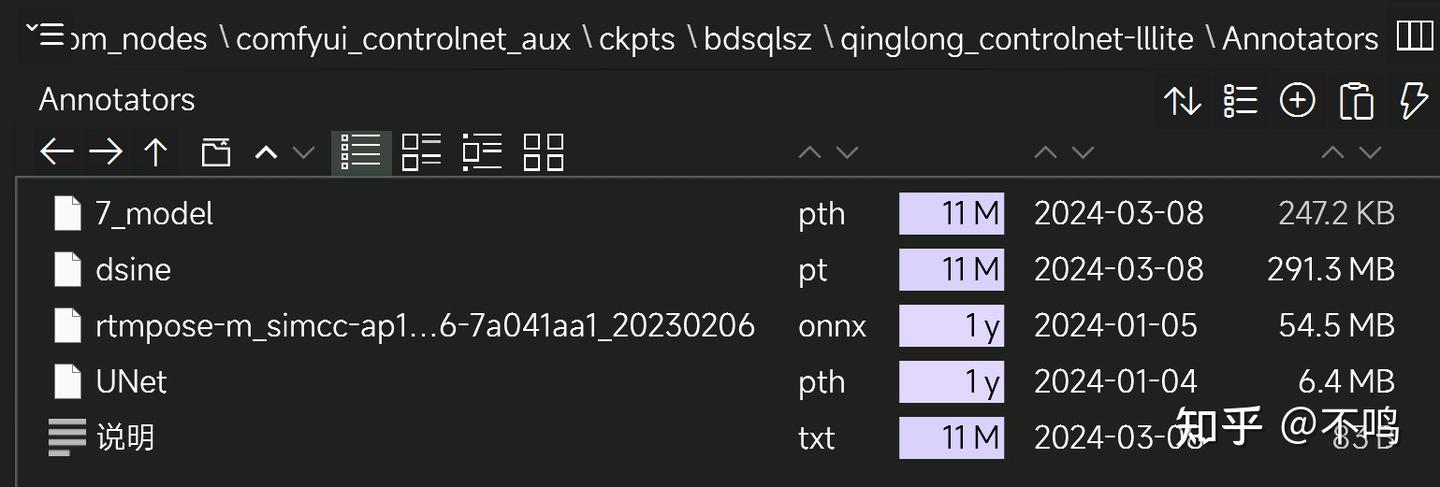
其它文件均是如此,建议把 ckpts 文件夹做个备份,防止自己不注意删了插件。也感谢此插件的文档管理者能细心列出所有需要的预处理文件,有些插件只能在使用时自动下载或缓存必要模型,但模型下载地址又多是网络不通就打不开的,不能手动用镜像下载着实折磨人。
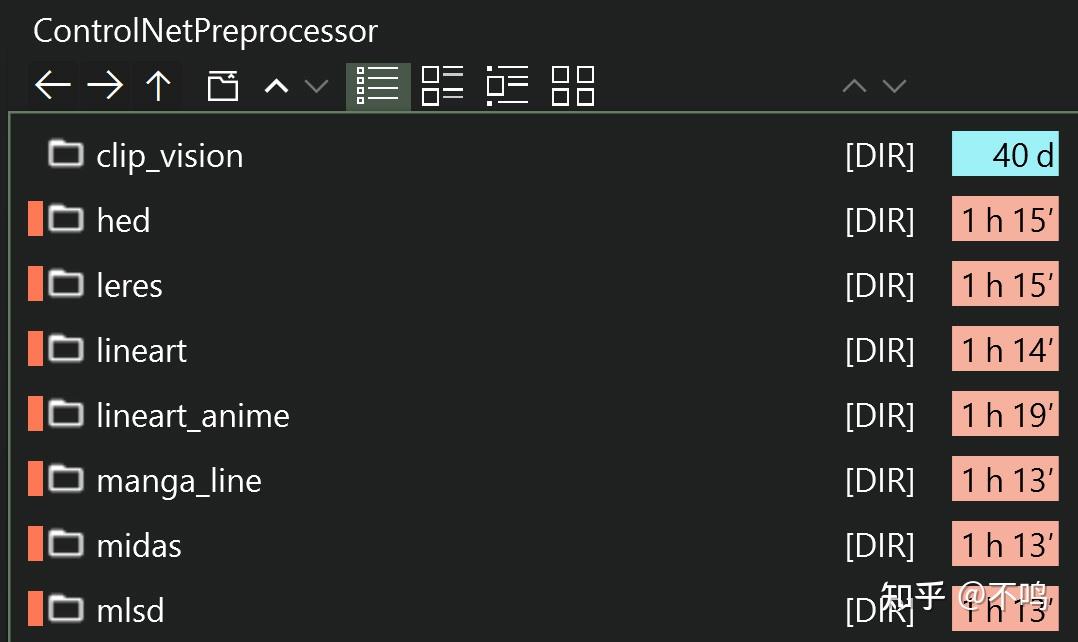
多说几句,不同的 AI 软件中 ControlNet 的预处理文件所安放的位置是不同的。比如 WebUI Forge,它把不同功能的处理文件分类放置,不能在使用时下载的话就只能手动整理,颇为繁琐:
3. ControlNet学习方法
完成以上步骤,就可以使用 ControlNet 预处理器插件了。
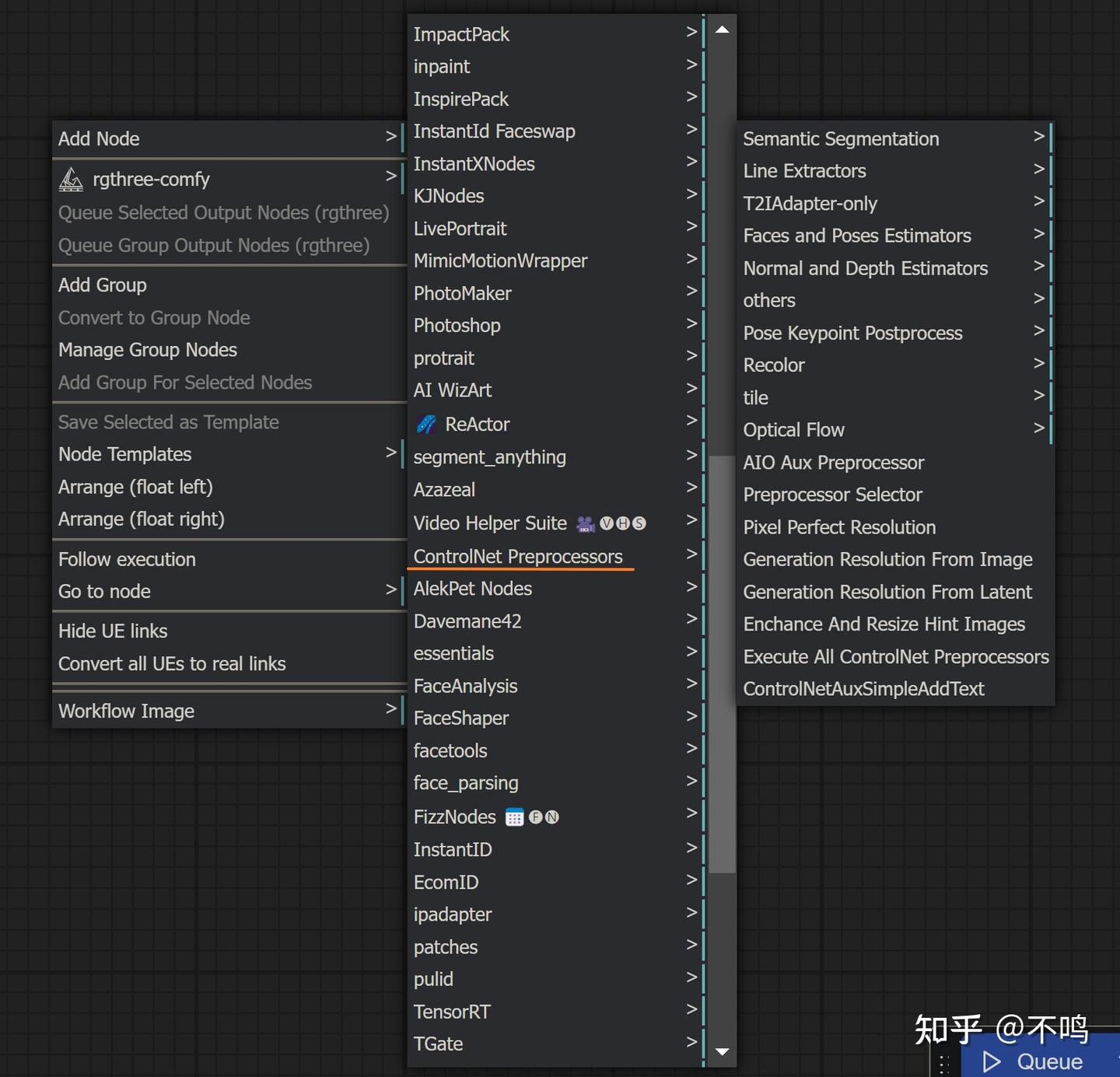
对初学者来讲,ControlNet 的难点就是模型对应的预处理器使用了。但只要多操作几次,很快就会明白它们的对应关系。如果你不是钱多到没处花,如果你想边学习边提升自学能力,别去报课。
我最初学 ComfyUI 时,网上找不到任何像样的 ControlNet 教程,于是只能看着下面这个页面,对应着在 ComfyUI 中摸索:
https://github.com/lllyasviel/ControlNet-v1-1-nightly
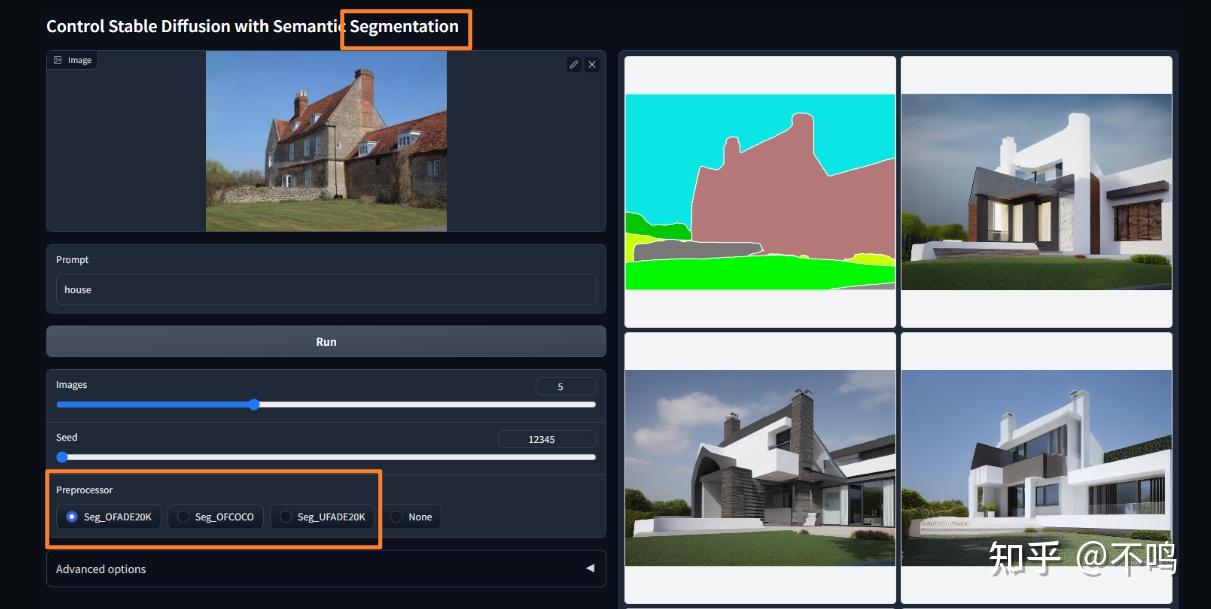
最需要注意的是模型与对应的预处理器,可以边看资料边记录:
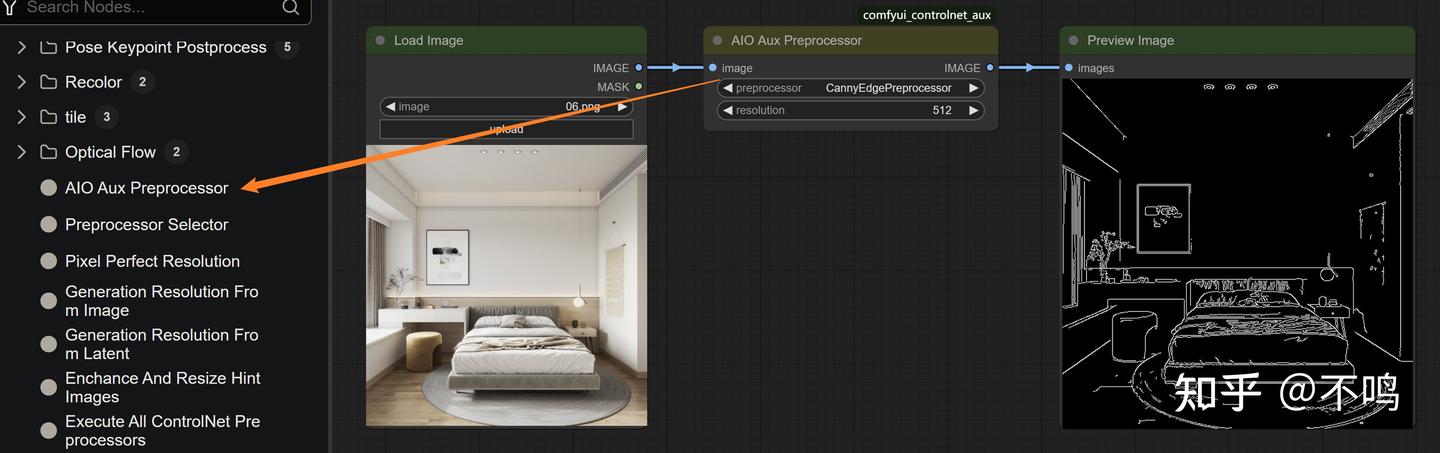
插件中有一个 AIO Aux Preprocessor 节点,它集合了所有的预处理器,在实际运用中很少会用到它,但对初学者来讲,它是一个很好的查看预处理效果的节点。
并非所有的预处理器都能处理同样的图片,根据你所需要生成的内容不同,所用的处理器也会不同。开始学习时尽管尝试,不要怕出错。所用图片分辩率最好为 512,这是 SD1.5 的标准尺寸,待你熟练之后再用别的尺寸。
现在用最基础的 ControlNet 工作流做几个案例。
Depth:
将卧室图处理成深度图像,提示词为 room。Control 模型相应的读取 control_v11f1p_sd15_depth,最后生成结构与原图一致但内容不同的卧室图。
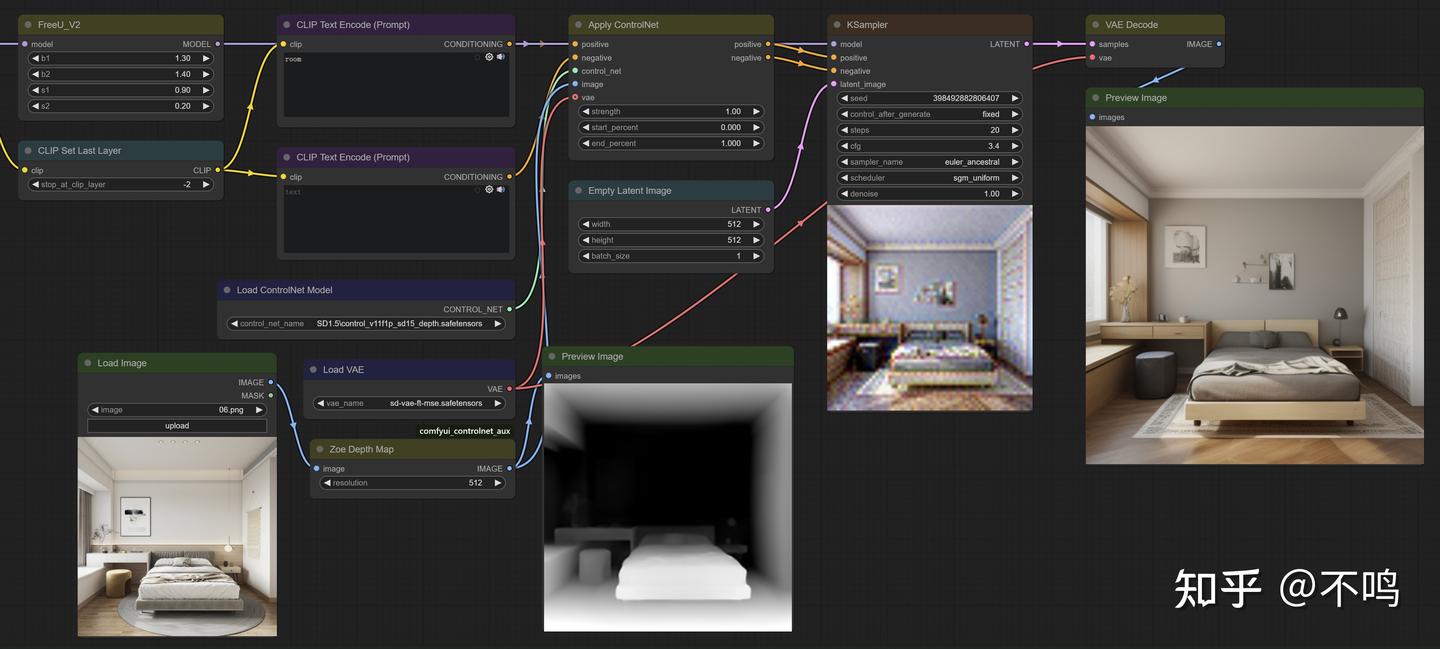
示例中的 ControlNet 工作流比基础文生图工作流多了 3 个节点,分别是预处理器 Zoe Depth Map,Control 模型读取 Load ControlNet Model,ControlNet 应用 Apply ControlNet。
提示词也应尽量简洁,过多的提示词只会起到不良效果。
Realistic Lineart:
现在将预处理器改为 Realistic Lineart,模型换为 control_v11p_sd15_lineart。
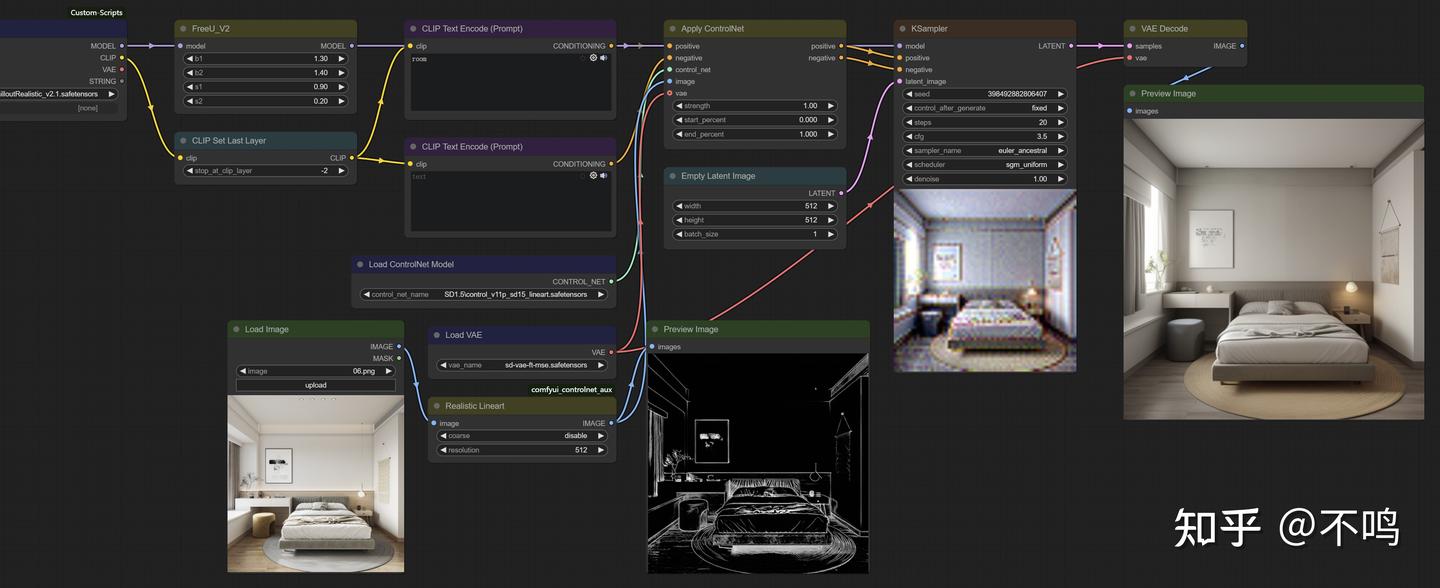
线条类的预处理器有多个,它们处理的结果不同,生成的图片也不同,但所用 Control 模型是一样的。
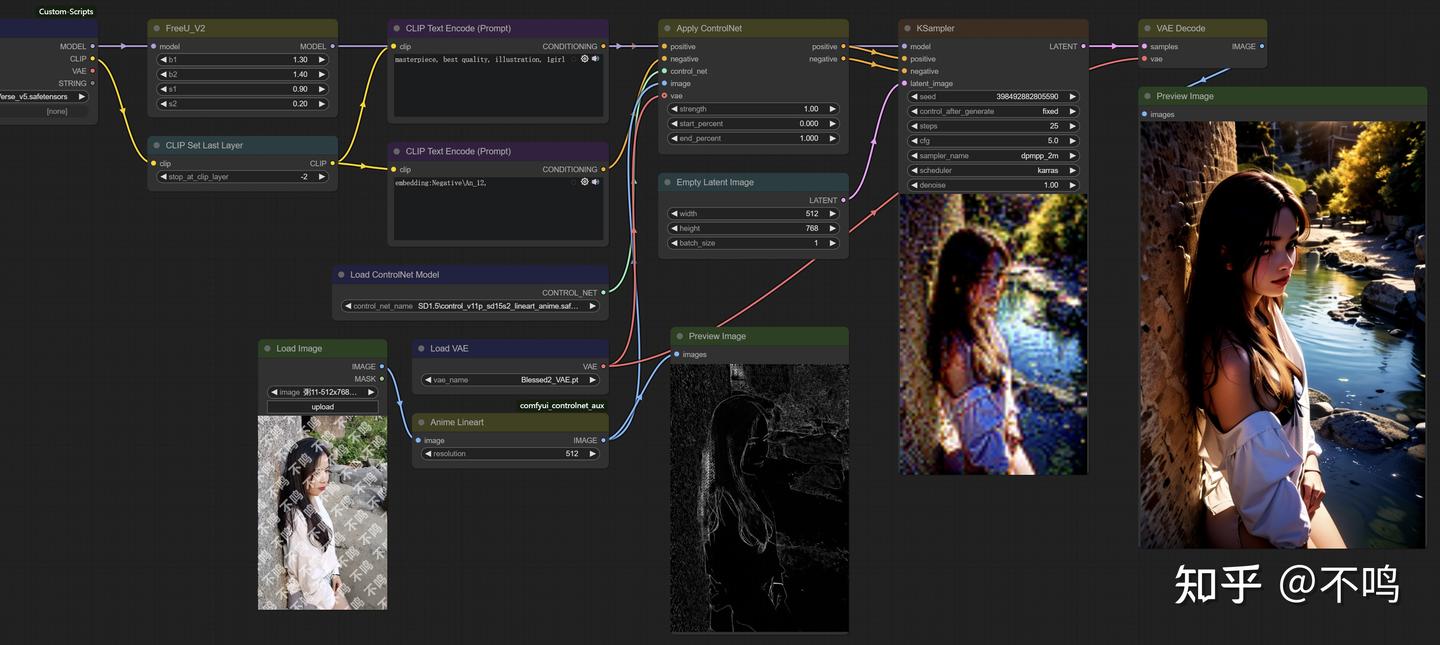
Anime Lineart:
再来一个人物转动漫示例。Anime Lineart 预处理器,对应 control_v11p_sd15s2_lineart_anime 模型。
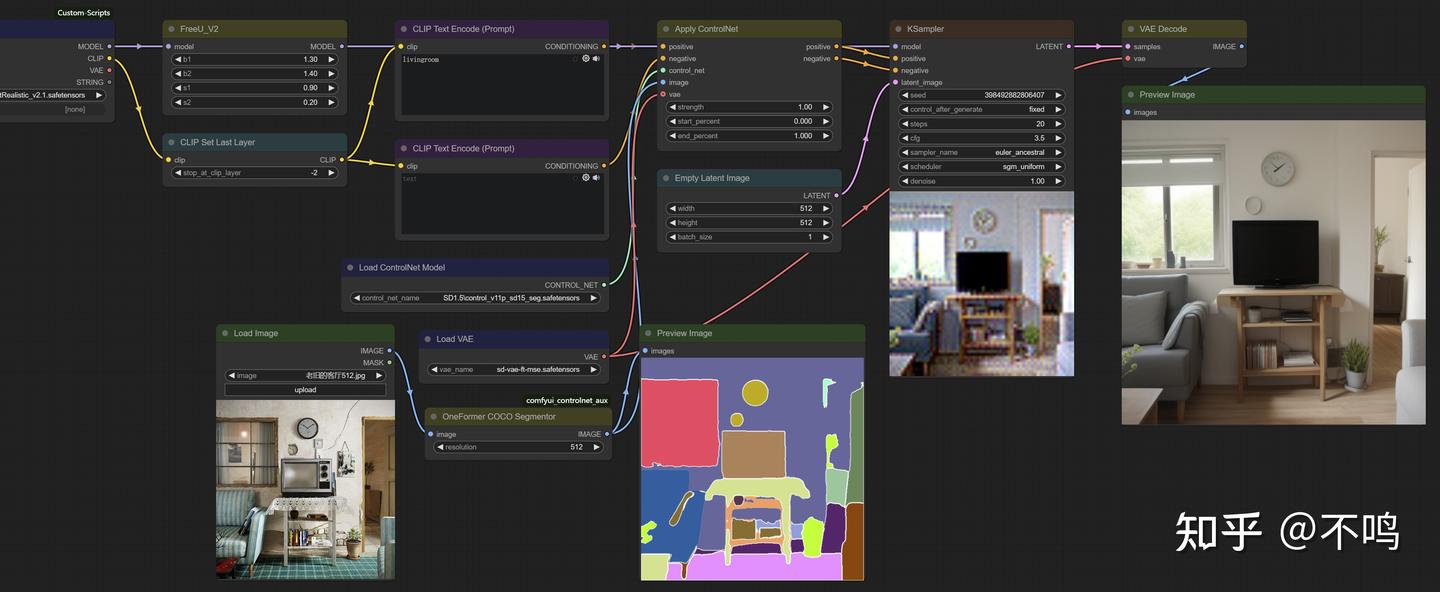
Segmentor:
再来个图形分割,预处理器换成 OneFormer COCO Segmentor,Control 模型改为 control_v11p_sd15_seg。
只要模型和预处理器名称对应的上,一般不会出错。
OpenPose:
输入人物图像,通过 OpenPose Pose 预处理器提取姿态,使用 openpose 模型来生成与之形态一致的图片。
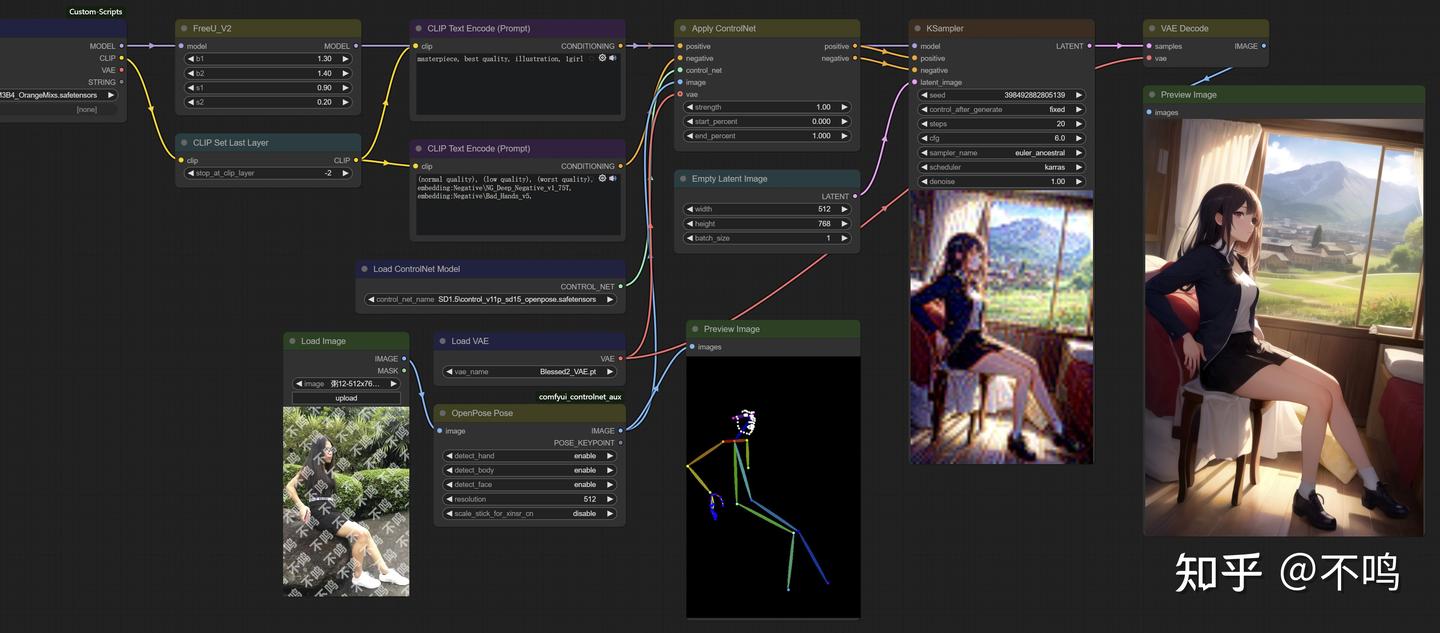
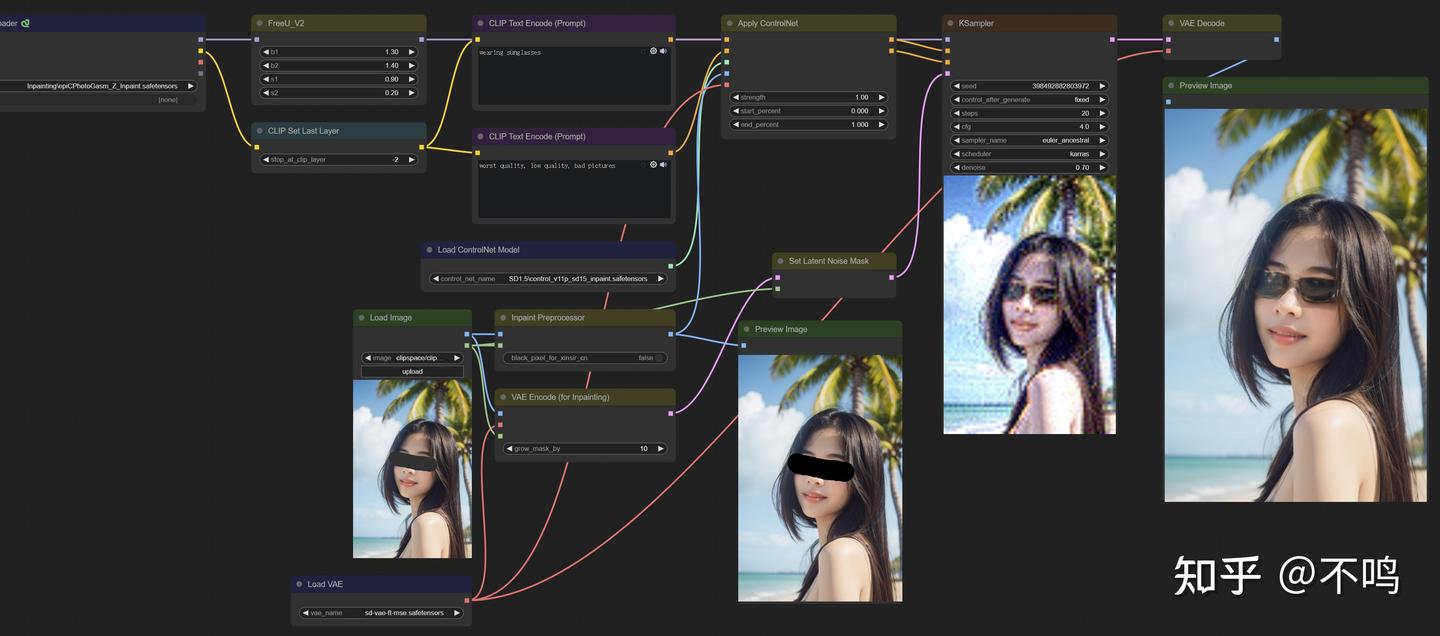
Inpaint:
并非所有的 Control 模型用法都一样,比如 Inpaint,它需要普通内部重绘加上 ControlNet 的 Inpaint 预处理器。注意,不止是 ControlNet 模型,基础大模型也要换成 Inpaint。
Instruct Pix2Pix:
它可以对图片进行风格转换,不需要预处理器,Control 模型为 control_v11e_sd15_ip2p。提示词要精简,比如示例中将森林小屋图转为冬天场景,make it winter 或 snowing 都有相似的效果。
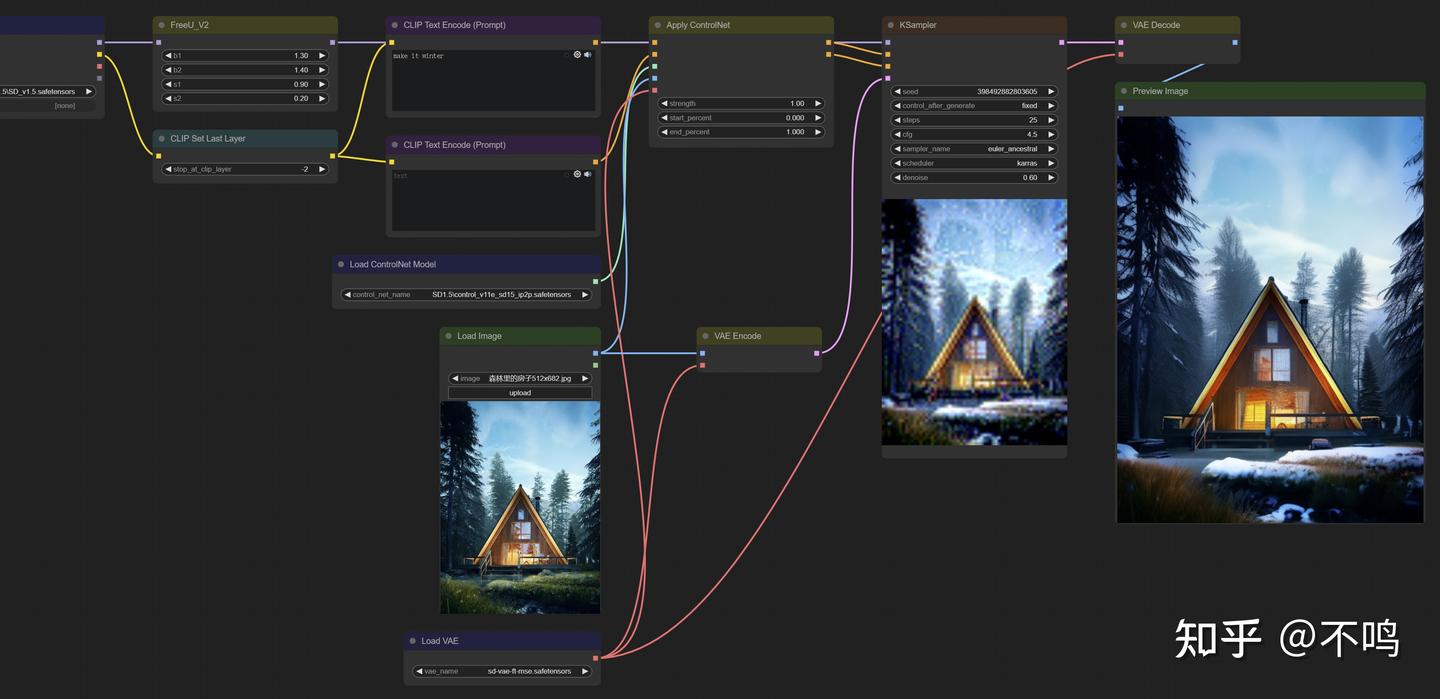
示例中输入图片连接了一个 VAE Encode,它在此处的作用是读取输入图片的尺寸,传递给采样器的 latent_image。
SD1.5 的 ControlNet 模型和 SDXL、Flux 的相比,效果上差距明显,所以学习时不必过于追求结果,主要是掌握使用方法及其运行方式。
人物肖像
用人物照片制作各种风格的肖像画是目前 AI 使用最广的玩法之一,各类相关 APP 上也是一堆的此类功能。但它们各有优缺点,还无法与在本机上使用 AI 软件带来的自由和效果相比。
本文不会对这些模型做过多讲解,仅做为图生图功能的一部分来介绍。
工作流分享:
https://www.alipan.com/s/1y1yHdzkCGx
https://pan.quark.cn/s/9a36aff1d701
1. Photomaker
Photomaker 根据输入人像图片的面部信息来生成各种风格样式的人物图。ComfyUI 带有 Photomaker 节点,但很基础,且长期属于测试分组,想用这个功能的话,建议使用该插件:
https://github.com/shiimizu/ComfyUI-PhotoMaker-Plus
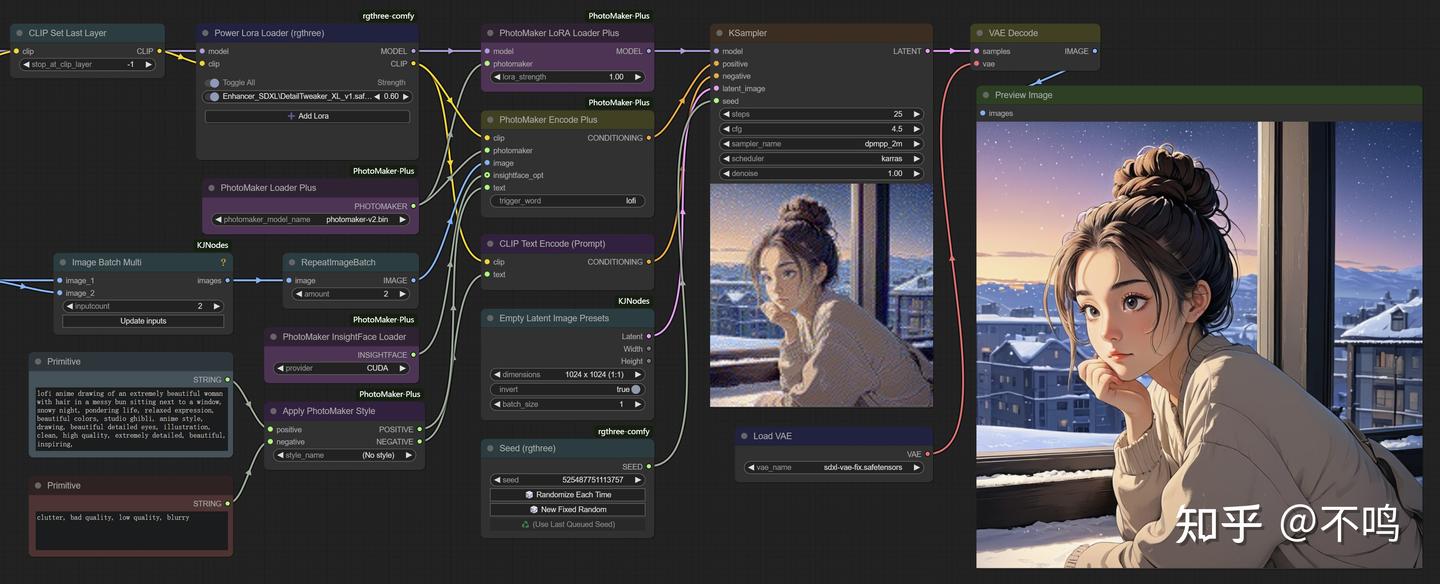
插件中带有几个工作流程,但太复杂,对新人不友好,所以我进行了简化。
Photomaker 需使用 SDXL 基础模型,并且输入输出均需用正方图,否则画面会怪异,这点十分不友好。Photomaker 像一些 Lora 一样,需要触发词才会有效,ComfyUI 自带节点的默认触发词为 Photomaker,用插件的话,可以在 PhotoMaker Encode Plus 中自定义触发词。另外在同类模型中,Photomaker 的效果是我认为最不好的,一次次的尝试和调整,结果总是远不如模型例图。
下载 photomaker 模型,将其放在 models 下的 photomaker 文件夹中:
https://hf-mirror.com/TencentARC/PhotoMaker-V2/tree/main
2. InstantID
InstantID 和 Photomaker 有些相似,但我认为其效果要好于 Photomaker,玩起来也很有意思。它也可以和 IPAdapter 配合使用,插件下载:
https://github.com/cubiq/ComfyUI_InstantID
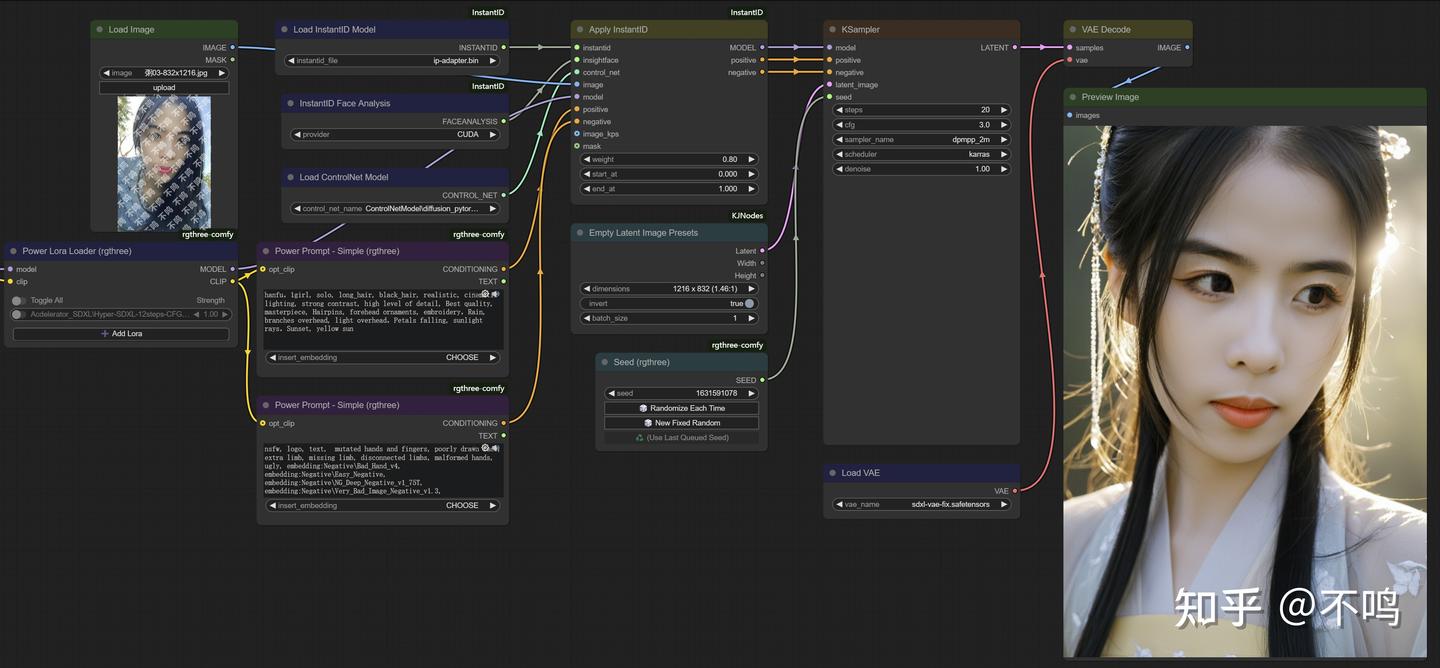
文档内容和插件中包含的工作流,已经足够让你掌握它的使用方法。InstantID 要和 SDXL 模型配合使用,底模够好的话,可以生成照片感很强的肖像图。
InstantID 对输入输出的图片没有尺寸限制,但两者比例最好一致,否则可能会出现人物面部占比不合理的情况。
必要模型下载
ip-adapter:
https://hf-mirror.com/InstantX/InstantID/tree/main
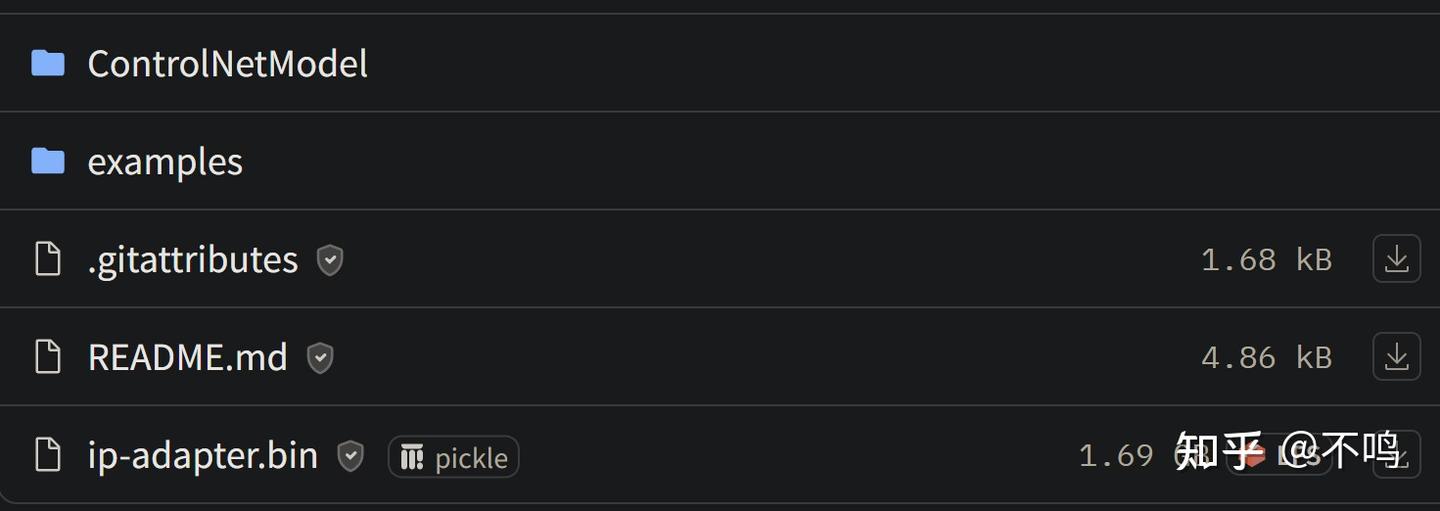
ControlNetModel 整个文件夹放置在 ComfyUI 的 contrlnet 文件夹中,ip-adapter.bin 放在 instantid 文件夹中,没有的话就新建一个。
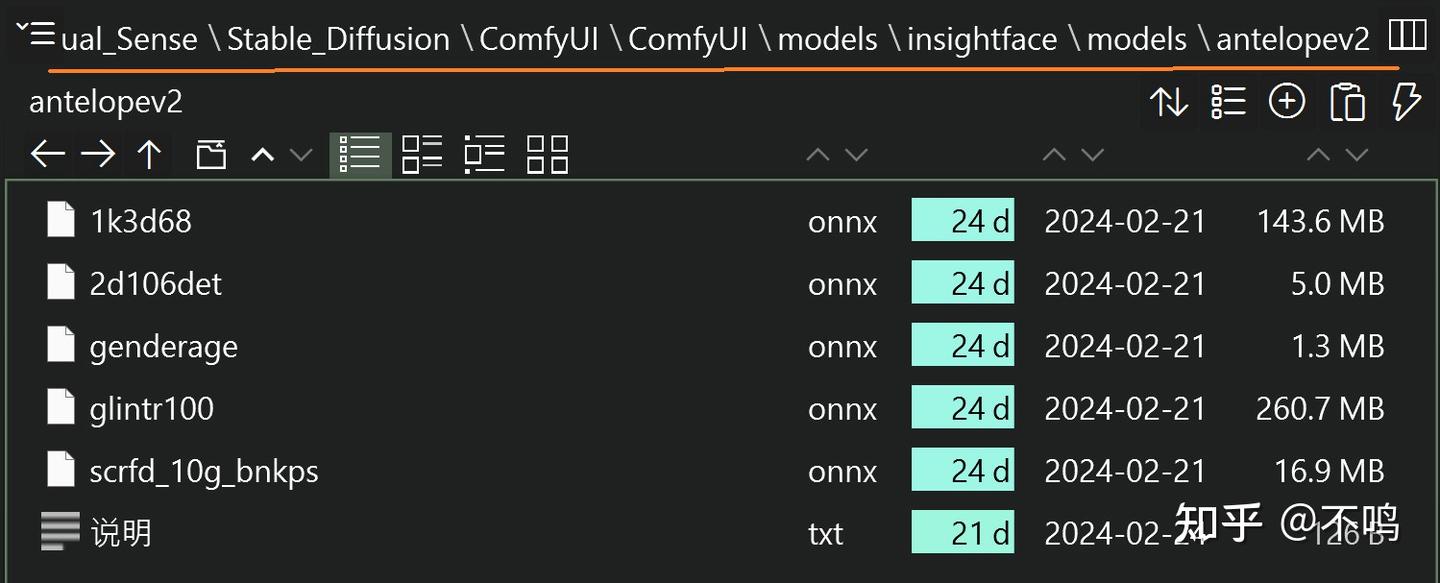
antelopev2:
https://hf-mirror.com/DIAMONIK7777/antelopev2/tree/main
3. IPAdapter
IPAdapter 很强大,可以生成与输入人像关联度很高的肖像图片。支持当前多种主流模型,不过需要下载不同的插件来使用,功能多样,探索起来趣味颇多。输入图片需使用方形图,输出图片没有尺寸要求。
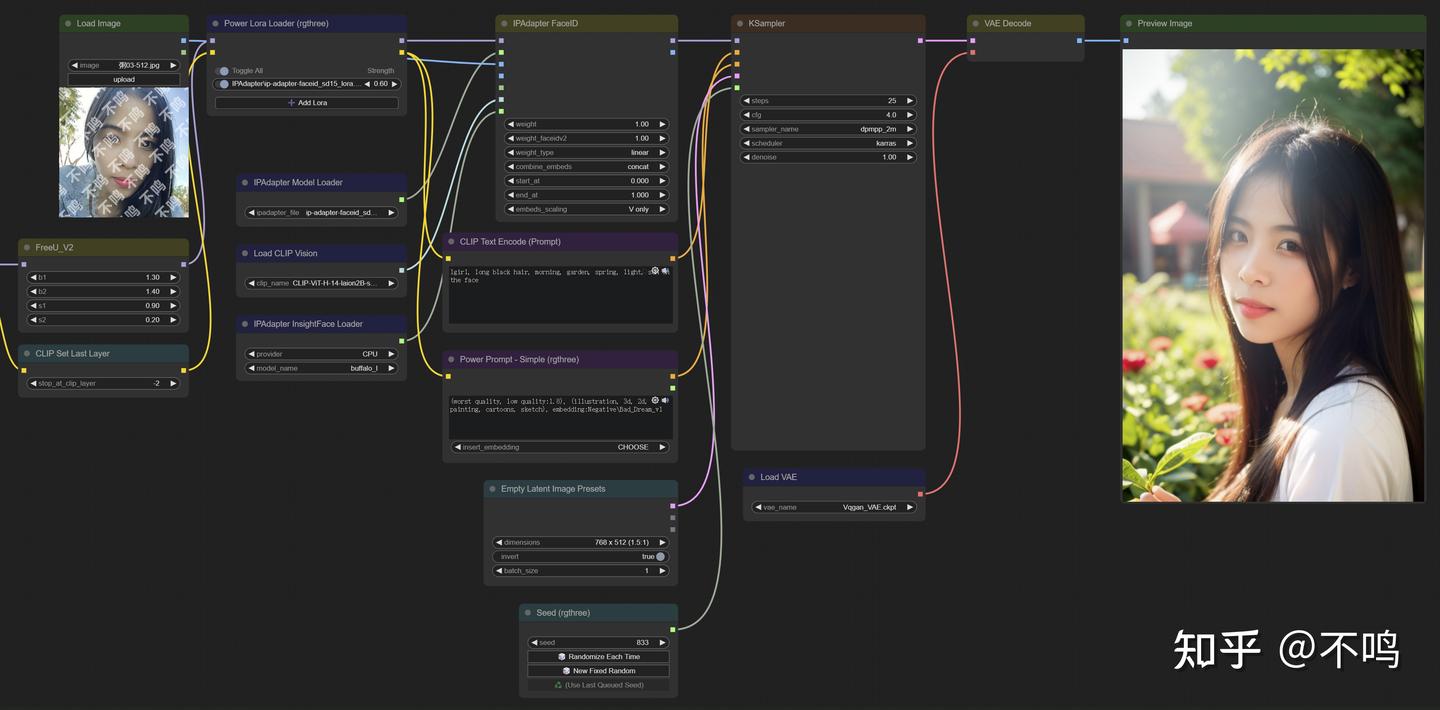
插件下载地址,该 IPAdapter 插件目前支持 SD1.5、SDXL、Kolors 模型:
https://github.com/cubiq/ComfyUI_IPAdapter_plus
插件内有完善的工作流,不必担心学习问题。
插件页面有较完善的安装说明,认真查看,下载后就可以正常使用,不会再缓存其它模型。
4. PuLID
PuLID 也是使用的 SDXL 模型,对输入输出图片尺寸没有要求,但建议输入方图。该模型生成的肖像真实度较高,面部非常接近原图。但缺点是有时候会感觉人物面部形态与图片整体不太融洽,需要调整提示词来接近理想效果。
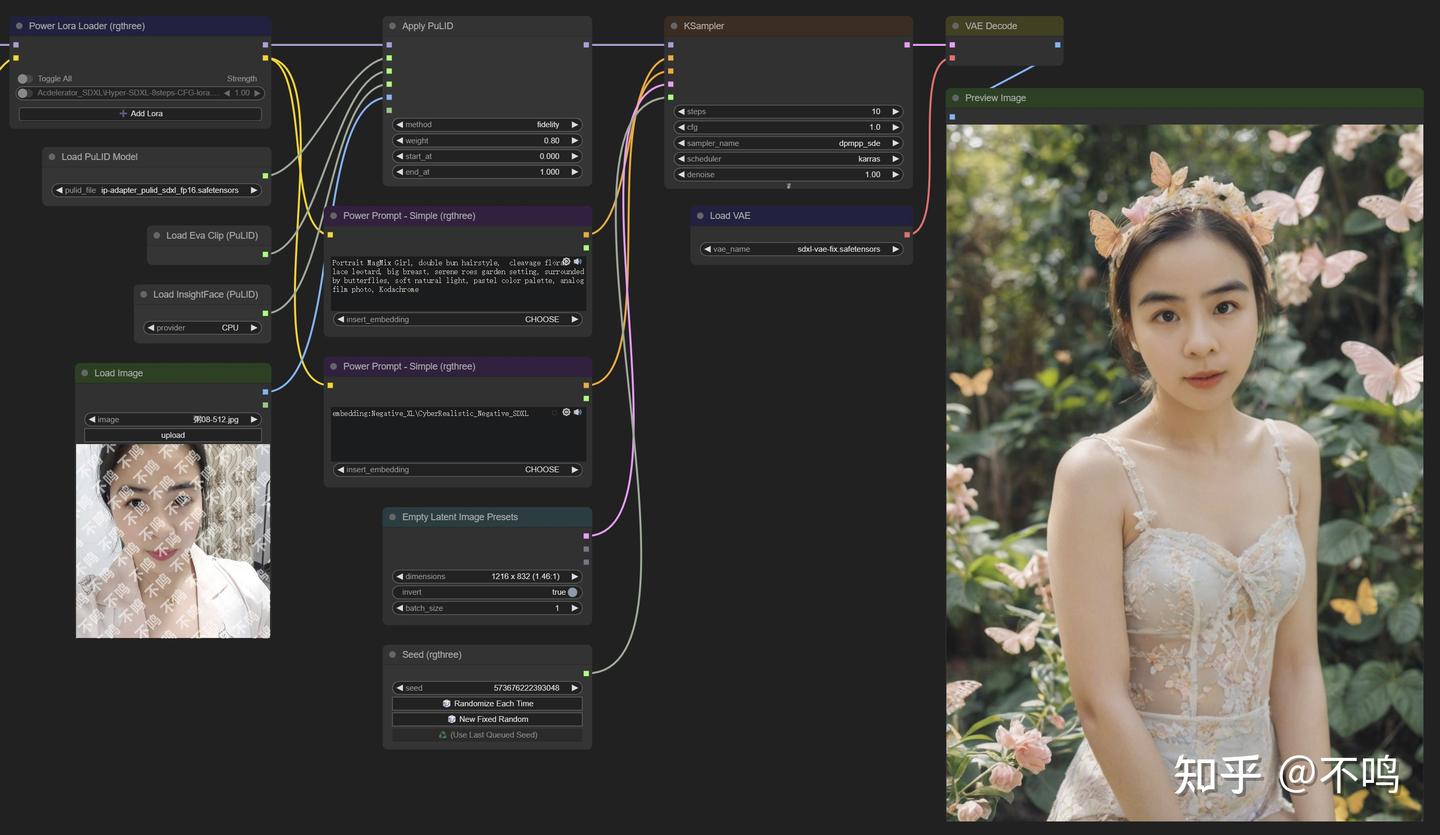
插件下载:
https://github.com/cubiq/PuLID_ComfyUI
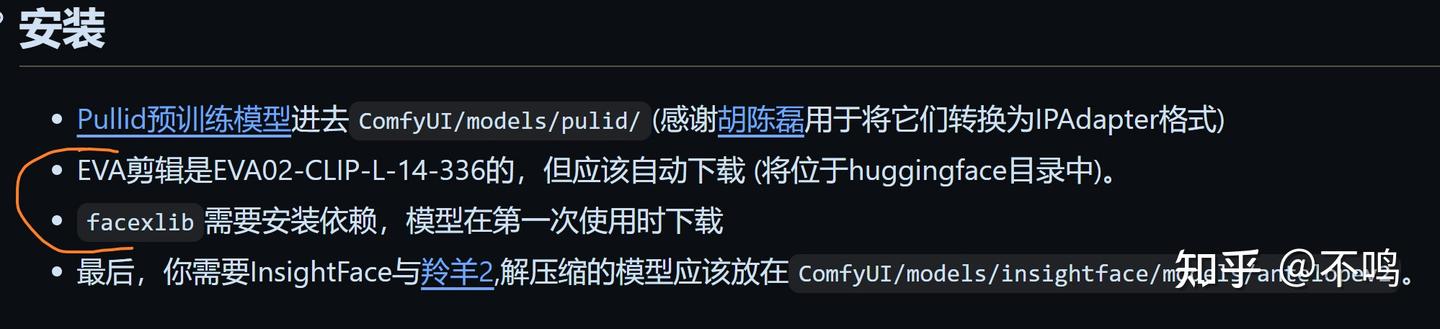
需要注意的是,这里的 EVA 模型只能初次使用插件时通过缓存来下载模型,缓存路径默认为 C 盘中的 .cache 目录内。如果你想改变缓存地址,或者连接不上 huggingface ,可以查看我的另一篇文章:《连接HuggingFace及更改缓存路径》。
而 facexlib 更是离谱,将模型自动下载到了 python 包内。
要我说呀,这种比较重要而且会被多种插件使用的模型就该统一到 models 内,特别是对于把 ComfyUI 装在移动盘中会更换电脑使用的用户。ComfyUI_PuLID_Flux_ll 就非常人性化,把同样的模型放到它们该去的地方。
5. EcomID
EcomID 也要使用 PuLID 模型,并且该插件与 PuLID 有不少相似之处,它更像是后者的一种升级改进。有更多的参数可供调整,比如 ip_weight 控制输出图片与输入人脸的相似度,它能达到近乎直接换脸的程度。输入输出图片无尺寸限制,但输入方形图更容易出效果。
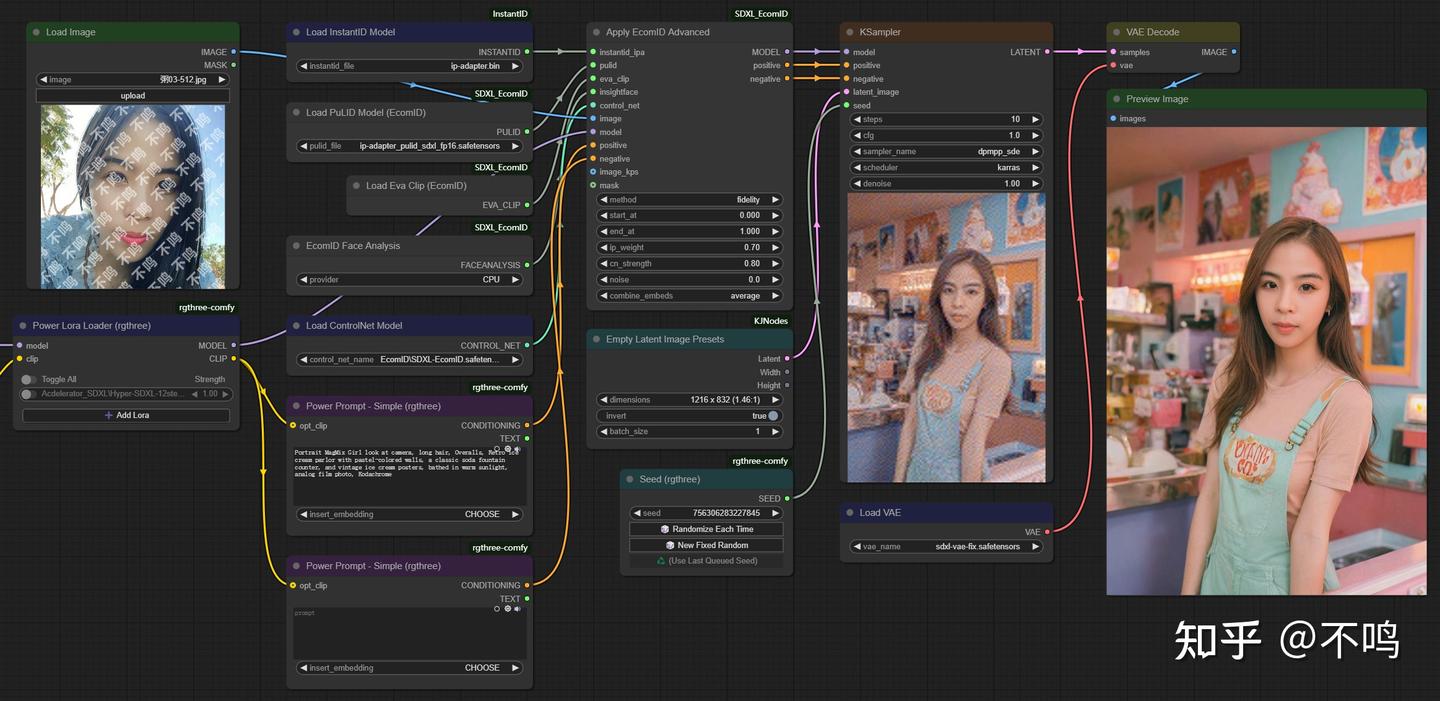
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
需要的可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …

二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …

三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …

四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …

五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …


这份完整版的学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









