









先欣赏下养眼图,休息一下~~

Stable Diffusion生成图1

Stable Diffusion生成图2

Stable Diffusion生成图3

Stable Diffusion生成图4

Stable Diffusion生成图5

Stable Diffusion生成图6
在网上看到那些美cry的AI生成的美女图片 ,你是不是也蠢蠢欲动想要按照自己的想法生成一副属于自己的女神照呢?
什么?你的电脑显卡没有显卡?没关系,今天笔者带大家手把手在本地电脑上使用CPU部署Stable Diffusion+Lora AI绘画 模型。
什么是Stable Diffusion ?
Stable Diffusion 是一种通过文字描述创造出图像的 AI 模型. 它是一个开源软件, 有许多人愿意在网络上免费分享他们的计算资源, 使得新手可以在线尝试.
安装
本地部署的 Stable Diffusion 有更高的可玩性, 例如允许您替换模型文件, 细致的调整参数, 以及突破线上服务的道德伦理检查等. 鉴于我目前没有可供霍霍的 GPU, 因此我将在一台本地ubuntu上部署,因为Stable Diffusion 在运行过程中大概需要吃掉 12G 内存。如果你的电脑或者服务器没有16GB以上的内存,需要配置一个虚拟内存来扩展你的内存容量,当然,性能也打个折扣,毕竟是在硬盘上扩展的内存空间。
如果你的电脑内存大小大于16GB,可以忽略以下的操作:
$ dd if=/dev/zero of=/mnt/swap bs=64M count=256
$ chmod 0600 /mnt/swap
$ mkswap /mnt/swap
$ swapon /mnt/swap
笔者的电脑配置:
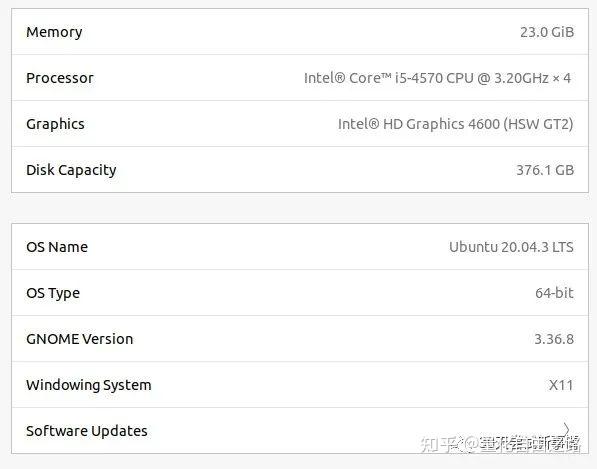
intel的集显哈
然后直接安装下载并安装 Stable Diffusion WebUI:
$ git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
$ cd stable-diffusion-webui
$ git checkout 22bcc7be428c94e9408f589966c2040187245d81
# 我们需要 CPU 版本的 torch
$ export TORCH_COMMAND="pip install torch==1.13.1 torchvision==0.14.1 --index-url https://download.pytorch.org/whl/cpu"
$ export USE_NNPACK=0
# 前 4 个参数是为了让其运行在 CPU 上, 最后一个参数是让 WebUI 可以远程访问
$ bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
稍等片刻(依赖你的网速)
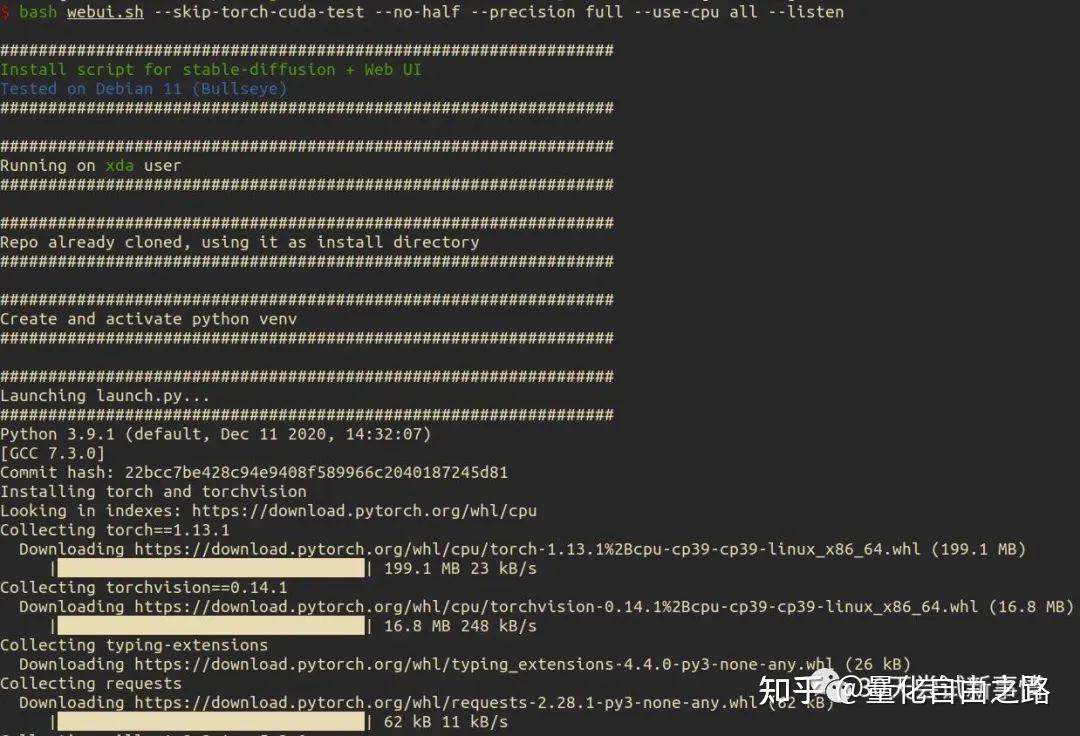
20230415002
由于需要连接到github下载源码,所以如果网络不稳定掉线,需要重新运行安装命令就可以了。
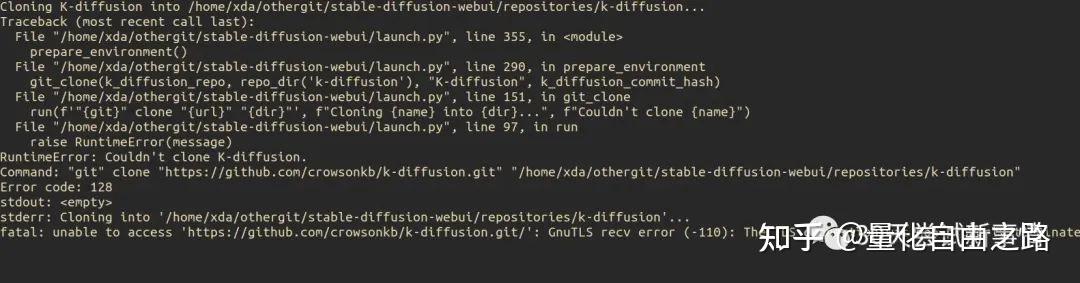
超时
重新运行:
bash webui.sh --skip-torch-cuda-test --no-half --precision full --use-cpu all --listen
这个脚本会自动创建python的虚拟环境,并安装对应的pip依赖,一键到位,可谓贴心。果断要到github上给原作者加星
v2-a85a91949b0f08315abd104425ecf7ee_r-v1
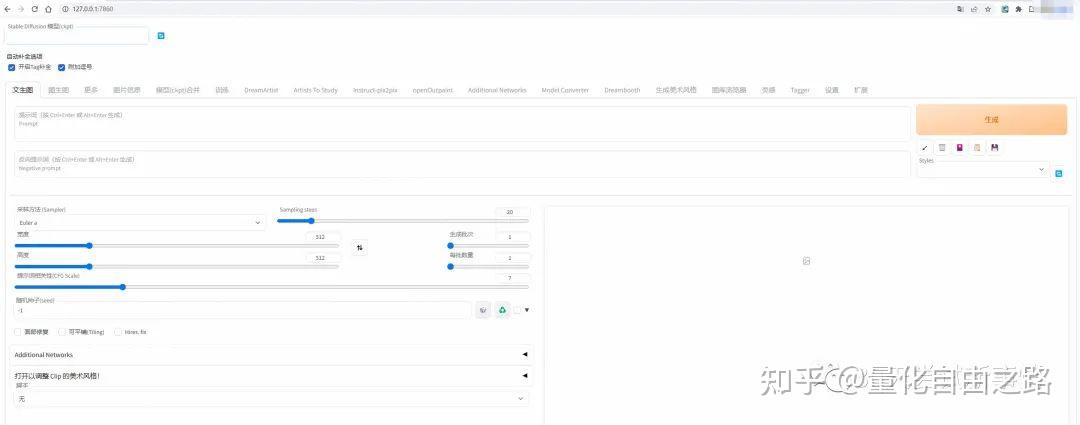
等待一段时间, 在浏览器中打开 127.0.0.1:7860 即可见到 UI 界面.
下载更多模型
模型, 有时称为检查点文件(checkpoint), 是预先训练的 Stable Diffusion 权重, 用于生成一般或特定的图像类型. 模型可以生成的图像取决于用于训练它们的数据. 如果训练数据中没有猫, 模型将无法产生猫的形象. 同样, 如果您仅使用猫图像训练模型, 则只会产生猫.
Stable Diffusion WebUI 运行时会自动下载 Stable Diffusion v1.5 模型. 下面提供了一些快速下载其它模型的命令.
$ cd models/Stable-diffusion
# Stable diffusion v1.4
$ wget https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
# Stable diffusion v1.5
$ wget https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
# F222
$ wget https://huggingface.co/acheong08/f222/resolve/main/f222.ckpt
# Anything V3
$ wget https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/anything-v3-fp16-pruned.safetensors
# Open Journey
$ wget https://huggingface.co/prompthero/openjourney/resolve/main/mdjrny-v4.ckpt
# DreamShaper
$ wget https://civitai.com/api/download/models/5636 -O dreamshaper_331BakedVae.safetensors
# ChilloutMix
$ wget https://civitai.com/api/download/models/11745 -O chilloutmix_NiPrunedFp32Fix.safetensors
# Robo Diffusion
$ wget https://huggingface.co/nousr/robo-diffusion/resolve/main/models/robo-diffusion-v1.ckpt
# Mo-di-diffusion
$ wget https://huggingface.co/nitrosocke/mo-di-diffusion/resolve/main/moDi-v1-pruned.ckpt
# Inkpunk Diffusion
$ wget https://huggingface.co/Envvi/Inkpunk-Diffusion/resolve/main/Inkpunk-Diffusion-v2.ckpt
修改配置文件
ui-config.json 内包含众多的设置项, 可按照个人的习惯修改部分默认值. 例如我的配置部分如下:
{
"txt2img/Batch size/value": 4,
"txt2img/Width/value": 480,
"txt2img/Height/value": 270
}
提示语示例
model: chilloutmix_NiPrunedFp32Fix.safetensors
prompt: beautiful, masterpiece, best quality, extremely detailed face, perfect lighting, (1girl, solo, 1boy, 1girl, NemoNelly, Slight penetration, lying, on back, spread legs:1.5), street, crowd, ((skinny)), ((puffy eyes)), brown hair, medium hair, cowboy shot, medium breasts, swept bangs, walking, outdoors, sunshine, light_rays, fantasy, rococo, hair_flower,low tied hair, smile, half-closed eyes, dating, (nude), nsfw, (heavy breathing:1.5), tears, crying, blush, wet, sweat, <lora:koreanDollLikeness_v15:0.4>, <lora:povImminentPenetration_ipv1:0>, <lora:breastinclassBetter_v14:0.1>
prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.331), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), bad hands, missing fingers, extra digit, bad body, pubic
上述提示词结尾引用了 3 个 Lora 模型, 需提前下载至 models/Lora 目录.
$ cd models/Lora
$ wget https://huggingface.co/amornlnw7/koreanDollLikeness_v15/resolve/main/koreanDollLikeness_v15.safetensors
$ wget https://huggingface.co/samle/sd-webui-models/resolve/main/povImminentPenetration_ipv1.safetensors
$ wget https://huggingface.co/jomcs/NeverEnding_Dream-Feb19-2023/resolve/main/lora/breastinclassBetter_v14.safetensors
生成的效果图:

AI生成图
更新: 如果wget下载模型属性慢,可以加入梯子,会明显快很多的。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍代码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入门stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









