







这个插件主要用于修复面部问题并为面部和手增加细节。目前,ADetailer包含了14个不同的模型,每个模型都有其独特的用途。我已经对其中大部分模型进行了对比分析。但有一个特殊的模型——DeepFashion,我之前并未介绍,因为它与其他模型有所不同。在这篇文章中,我将详细介绍DeepFashion。
# DeepFashion的核心功能
DeepFashion模型的核心功能是处理服装。这个模型的数据集包括来自13个流行服装类别的80多万件服装。使用DeepFashion模型,ADetailer能够检测图像中的服装,并进行分割,以便进行单独处理。

我们都知道,Stable Diffusion的自然语言理解能力较弱,无法与DALL-E和Midjourney相提并论。例如,使用SDXL模型生成的这张图片,其提示词是“1位女孩,面带微笑,晨光打在脸上,黑色丝质吊带衫,领口处有精致的蕾丝边,酒红色格子高腰半身裙,全身拍摄,凉鞋,古色古香的鹅卵石街道,景深,虚化”。但是,女孩裙子上的格子图案并没有被体现出来。提示词越长,遗漏的细节就越多。

而使用DeepFashion后,可以看到明显的改进,如裙子上的格子图案就被准确体现出来了。

再比如,解决提示词污染的问题。例如,一张图片的背景是柠檬黄色,但Stable Diffusion可能会错误地将柠檬图案应用到女孩的裙子上,如下图所示:

这时,使用DeepFashion可以有效解决这一问题。它会将裙子单独分离出来,并使用专门的提示词进行描述。这样,如果提示词中不包含“柠檬”,裙子上就不会出现柠檬图案。
# 安装DeepFashion模型
以下是DeepFashion模型的详细安装过程:
1️⃣Adetailer插件安装
首先,确保已经安装了Adetailer插件。如果尚未安装,可以参考上一篇文章中的步骤进行安装。安装Adetailer是使用DeepFashion的前提条件。
2️⃣下载DeepFashion模型
安装Adetailer插件后,DeepFashion模型不会自动出现在模型列表中。要使用DeepFashion,您需要手动下载它。模型的下载链接是:
https://huggingface.co/Bingsu/adetailer/tree/main。
3️⃣进入下载页面
在浏览器中输入下载地址后,你将被引导至HuggingFace下载页面。在这里,所有可用的模型都会被列出,你可以找到位于列表首位的DeepFashion模型。旁边有一个下载按钮,点击该按钮开始下载。
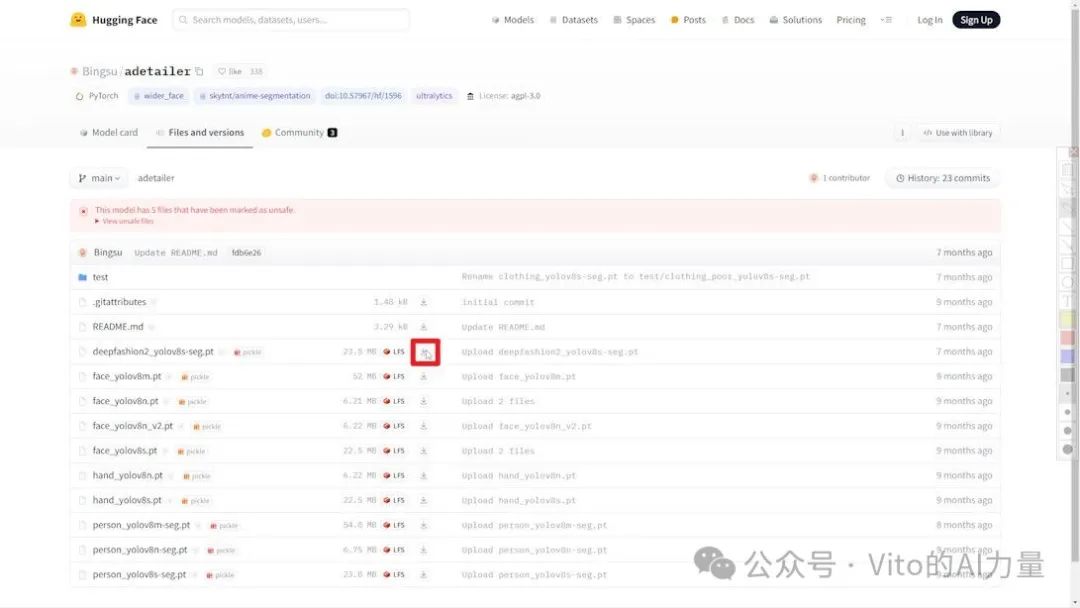
4️⃣移动模型文件
下载完成后,将下载的模型文件移动到Stable Diffusion的 “webui/models/adetailer” 文件夹内。这一步骤是必要的,以确保WebUI能够正确识别并加载模型。
5️⃣重启WebUI
将DeepFashion模型文件放置在正确的文件夹后,需要重启WebUI。重启后,DeepFashion模型应该出现在Adetailer的模型列表中,这意味着它已经准备好使用了。
安装完成以后,让我们通过两个案例,身临其境,体验DeepFashion的用法。
# 案例一:使用DeepFashion解决衣物图案问题
1️⃣ 生成初始图片:
- 打开WebUI界面。
- 选择模型:“MajicmixRealistic”(在下一个案例中将使用SDXL模型)。
- 提示词内容:“在现代艺术画廊里穿着亮片裙子的女孩儿”。
- 根据需要调整其他参数。
- 点击“生成”查看效果。
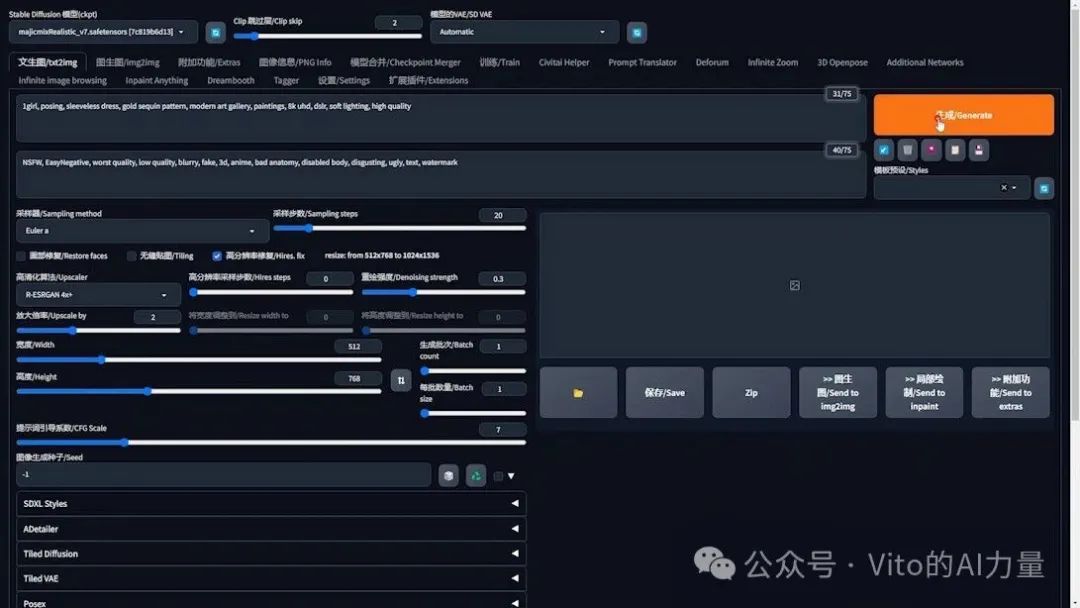
为了更好地说明问题,我生成了几张不同的图片。从中选取了三张展示出来。可以看到,衣服上的亮片或金色部分错误地出现在了背景中。

2️⃣ 使用DeepFashion解决问题:
- 首先生成一张衣服上没有亮片图案的底图。
- 指定裙子的颜色为黄色,以避免生成黑色裙子导致亮片不明显。
- 将“gold sequin pattern”从提示词中剪切出来,稍后在Adetailer中使用。
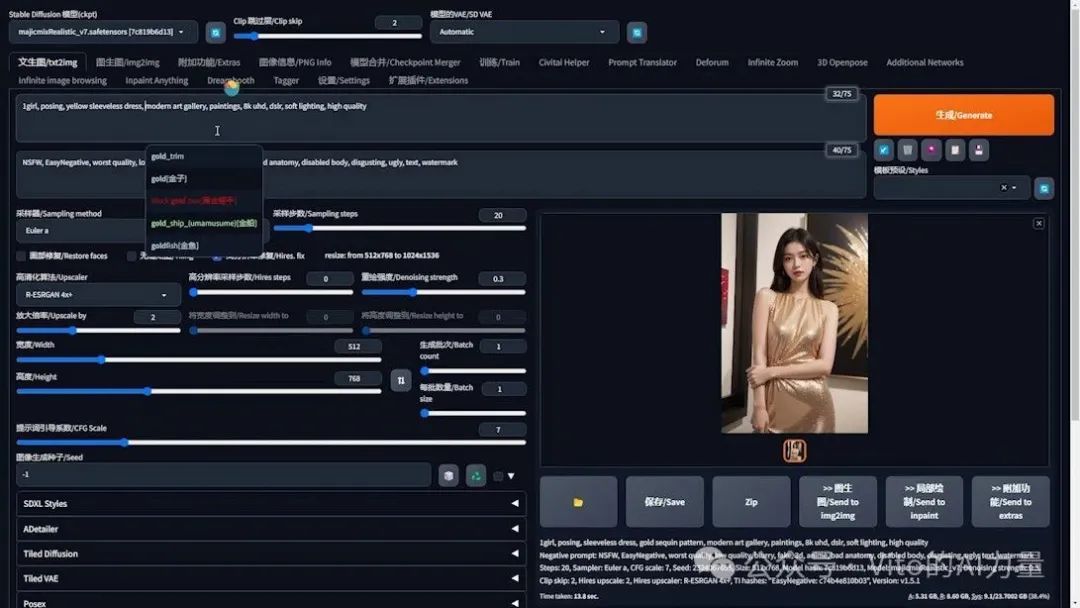
- 先不勾选Adetailer插件。
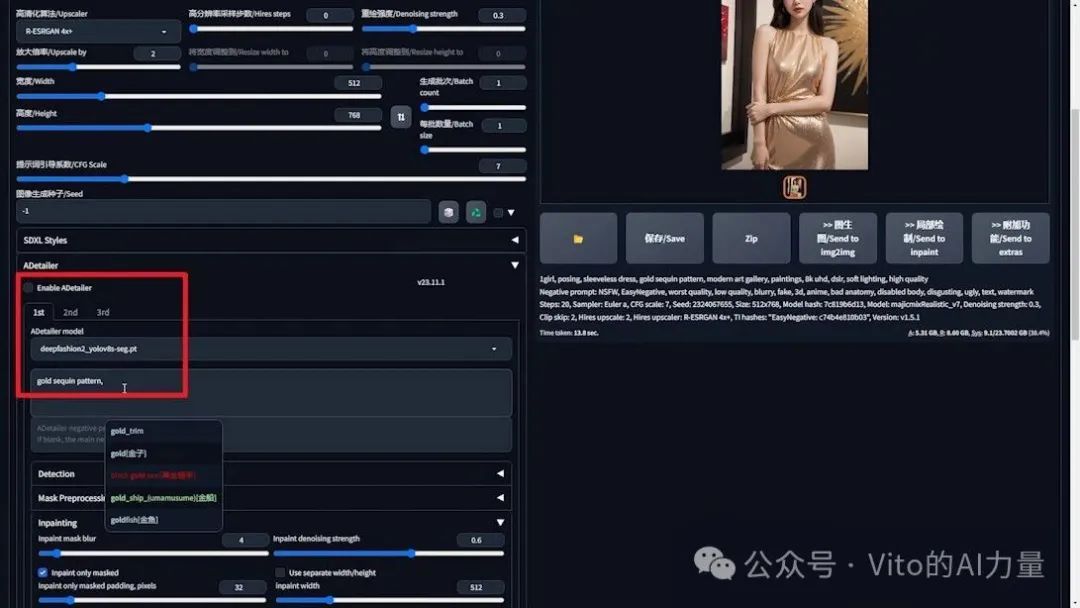
- 如遇提示词污染问题,将黄色添加到Cutoff插件中,确保背景不会出现金色亮片。
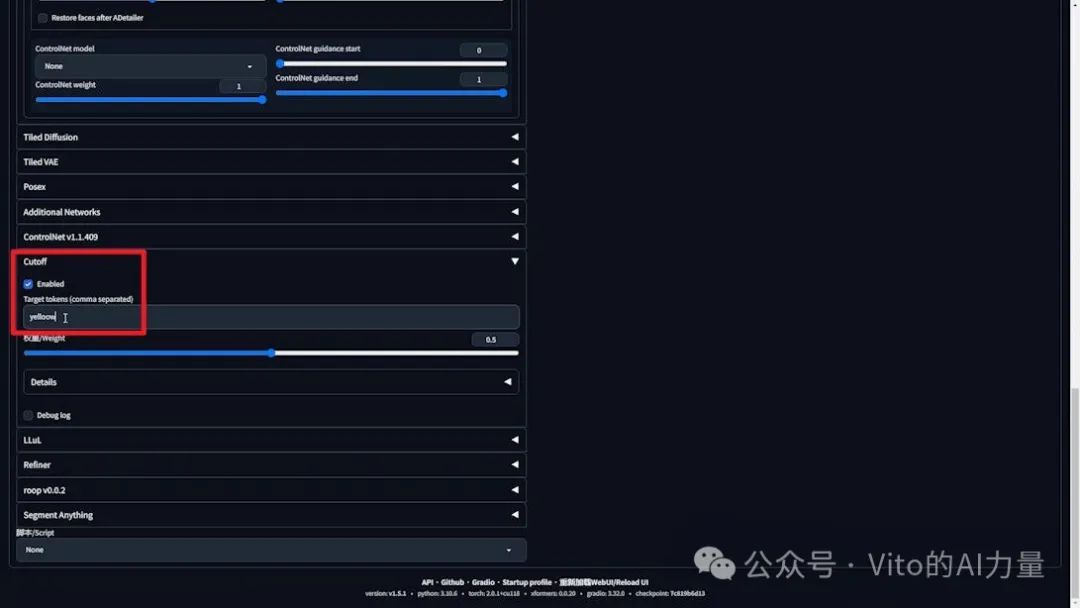
- 生成底图。

3️⃣ 添加亮片效果:
- 固定随机种子,勾选Adetailer插件。
- 在Adetailer的模型列表里选择DeepFashion。
- 使用刚才剪切的“gold sequin pattern”作为提示词。
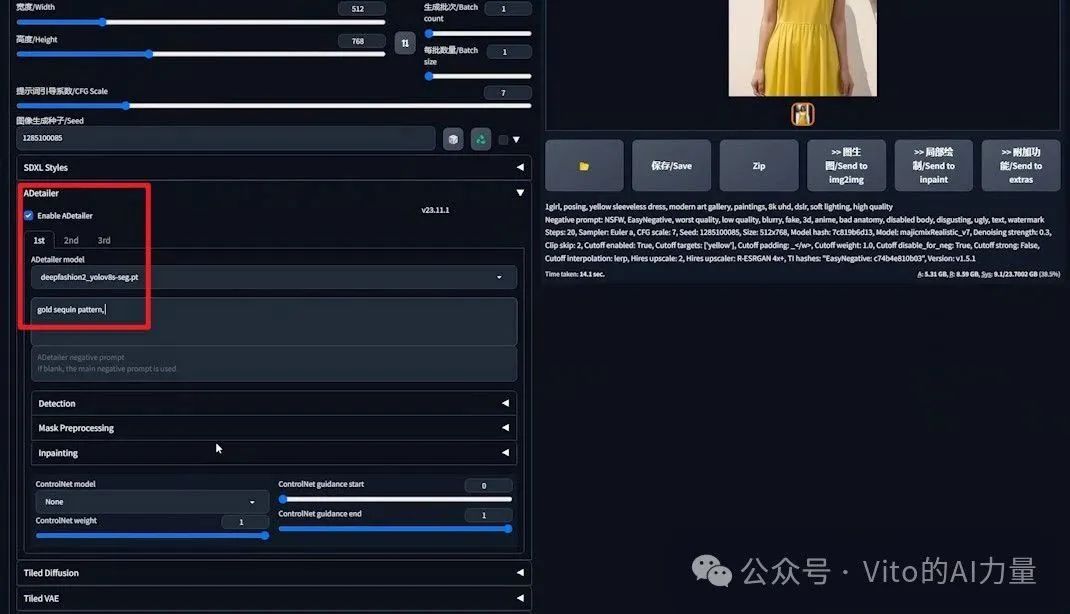
- 展开“Inpainting”设置,调整“Inpaint denoising strength”(重绘去噪强度)至0.6。
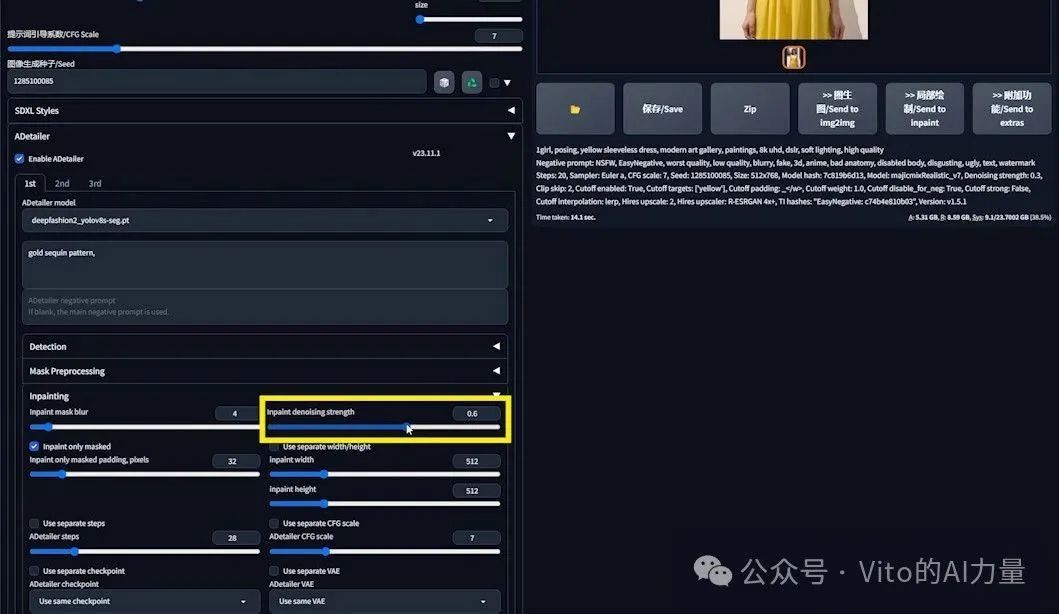
-
生成图片,并观察过程:
-
- Stable Diffusion首先根据随机种子生成底图。
- DeepFashion接管,识别裙子,并对其进行标注和处理。
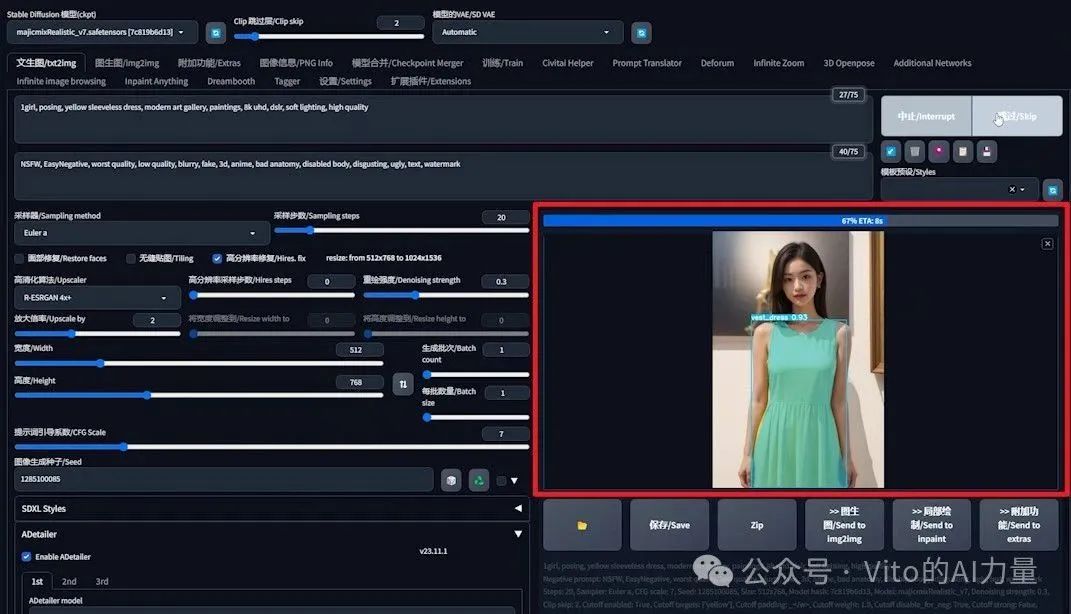
4️⃣ 调整去噪强度以改善效果:
- 如果亮片效果不足,可将去噪强度调至0.7再生成,观察效果。
- 如需更多亮片,继续将参数调至0.8。

案例总结
DeepFashion能够有效地将服装从图片中分离出来进行单独处理,解决了提示词污染问题。这种技术特别适用于那些Stable Diffusion可能无法准确理解和渲染的复杂场景。
例如,使用albedobaseXL模型生成的图片中,绿色的裙子和柠檬黄的背景被准确分离,没有出现混淆。

而使用dreamshaperXL-Turbo模型生成的图片就出现了问题,背景中的柠檬黄色错误地出现在了裙子上。

在这种情况下,DeepFashion就显现出了其优越性,能够准确地处理和优化图片中的服装元素。
通过这个案例,我们可以看到,DeepFashion不仅提高了Stable Diffusion生成图像的质量,也为我们在图像生成过程中提供了更多的控制和创造力。
# 案例二:优化SDXL模型中的颜色处理
在Stable Diffusion的应用中,尤其是使用SDXL模型时,我们经常遇到提示词污染问题,特别是在处理颜色时。让我们通过一个实际案例,探索如何使用DeepFashion来解决这一挑战。
1️⃣ 设置与生成初步图片:
- 模型选择:更换为SDXL模型。
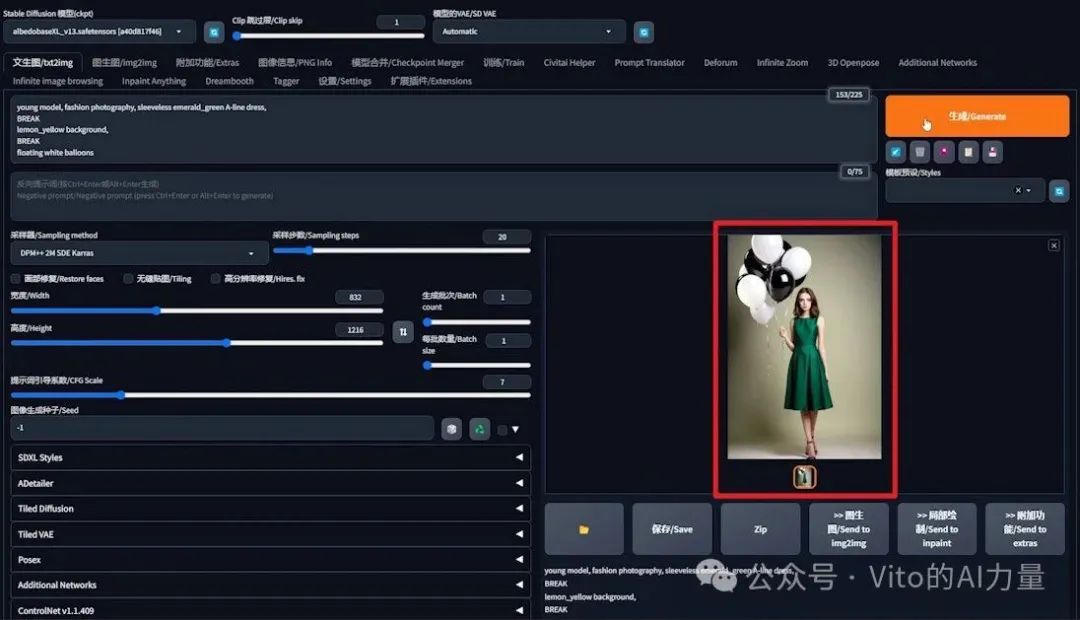
- 提示词设定:“年轻模特,时尚摄影,无袖祖母绿 A 字连衣裙,花朵蕾丝装饰,柠檬黄背景,漂浮的白色气球”。
- 分辨率:设为832x1216。
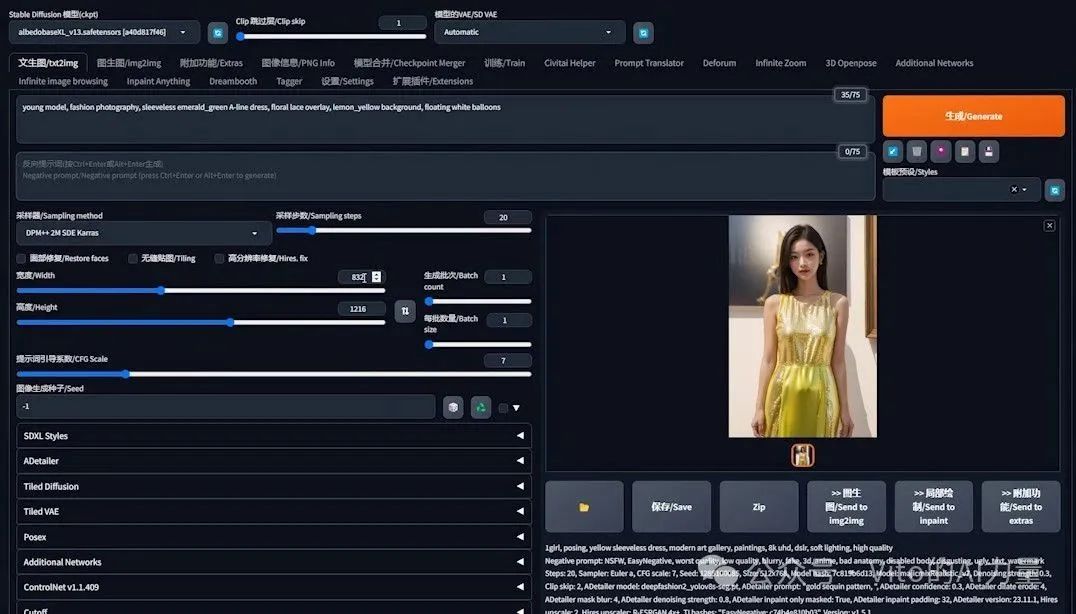
- 生成结果:希望得到的是白色气球,但图片中出现了黄色和绿色的气球。
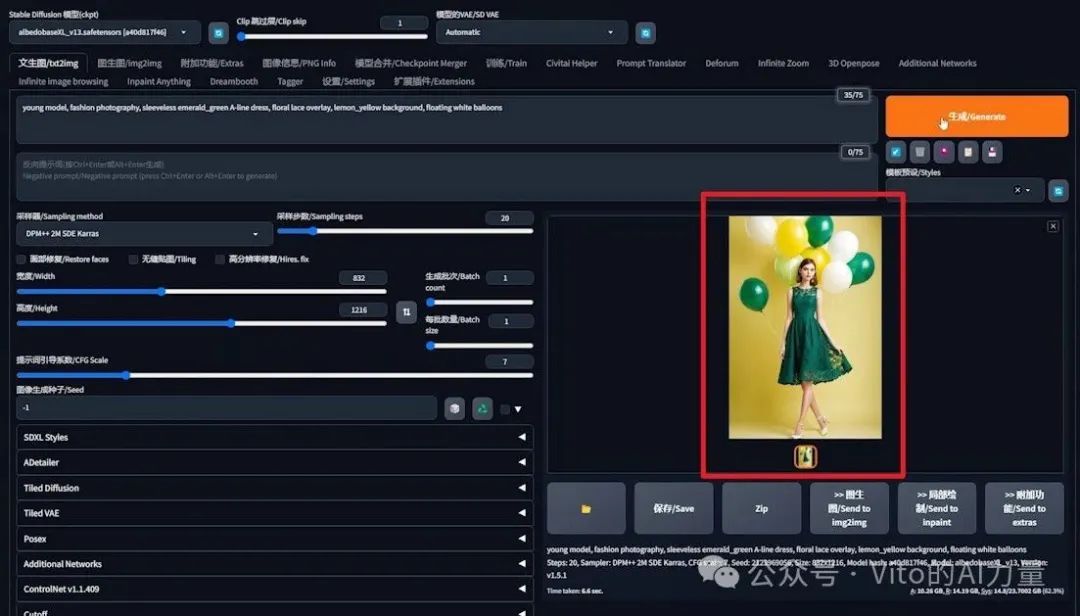
2️⃣ 重复生成以寻求改善:
- 第一次重新生成:去除了绿色气球,但仍有黄色气球。
- 第二次重新生成:问题更加夸张,裙子上出现了花朵。
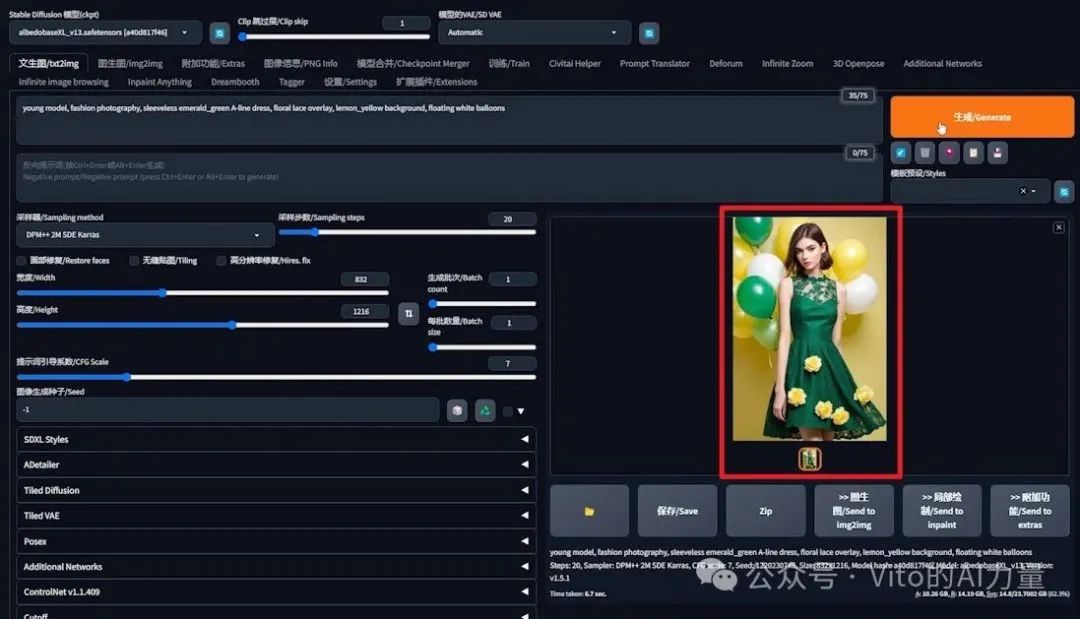
通过这个案例,我们看到了SDXL模型在处理特定颜色和元素时的挑战。虽然重复生成图片可能会带来一些改进,但结果仍然不稳定,且不符合我们的预期。为了解决这一问题,DeepFashion插件就显得尤为重要。
在接下来的内容中,我将展示如何使用DeepFashion来精确控制图像中的颜色元素,确保生成的图像更加符合我们的预期。
3️⃣ 尝试使用“BREAK”关键词:
- 简化提示词:去掉“蕾丝装饰”。
- 在“裙子”和“柠檬黄背景”之后加入“BREAK”关键词。
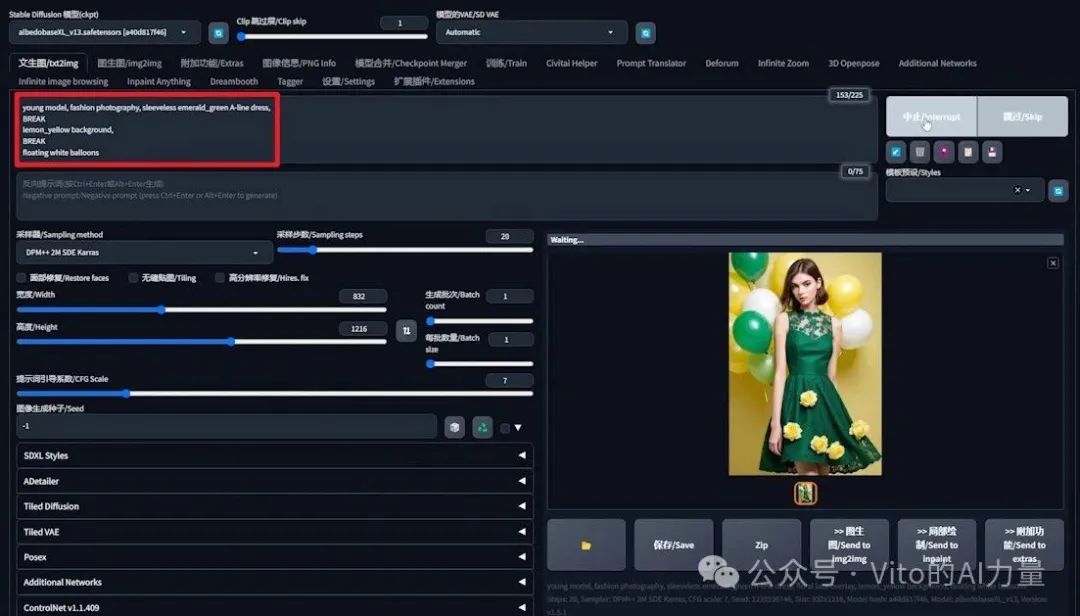
- 生成结果:出现了黑色气球,背景颜色错误。
2️⃣ 多次尝试改进:
- 再次生成:裙子和气球颜色正确,但背景色仍然不准确。
- 最后一次尝试:颜色终于正确,但方法不稳定,依赖运气。
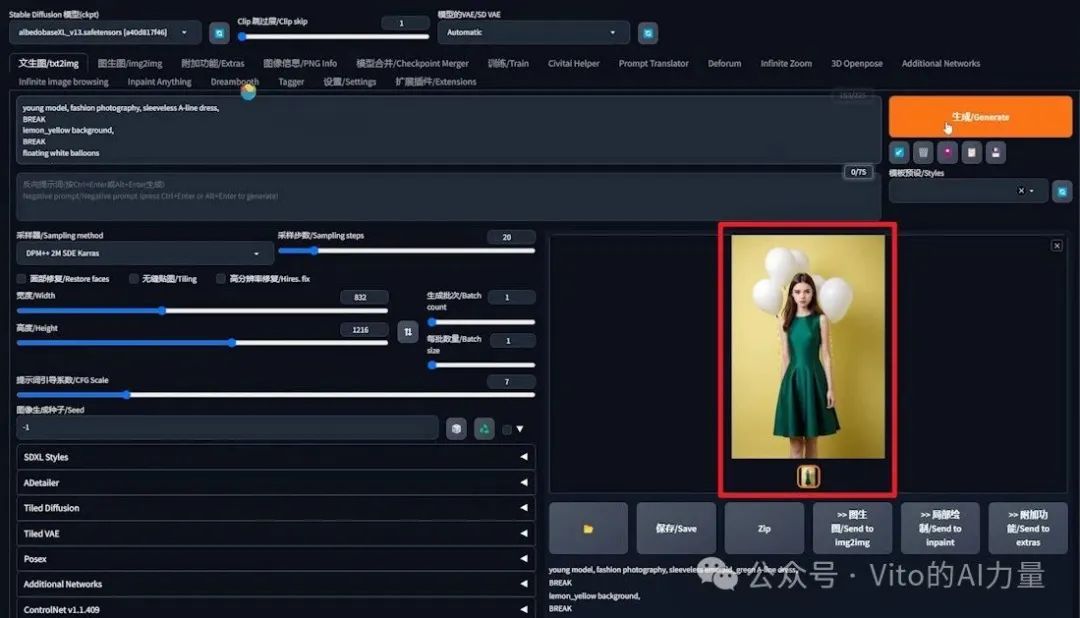
我们用抽卡的方式实现了想要的效果。但是可以看到,这种方法不稳定,得靠运气。接下来我们用DeepFashion实现更可控的效果。
1️⃣ 准备阶段:
- 删除提示词中的“祖母绿”,准备稍后通过DeepFashion进行调整。
- 生成图片,确保背景和气球颜色正确。

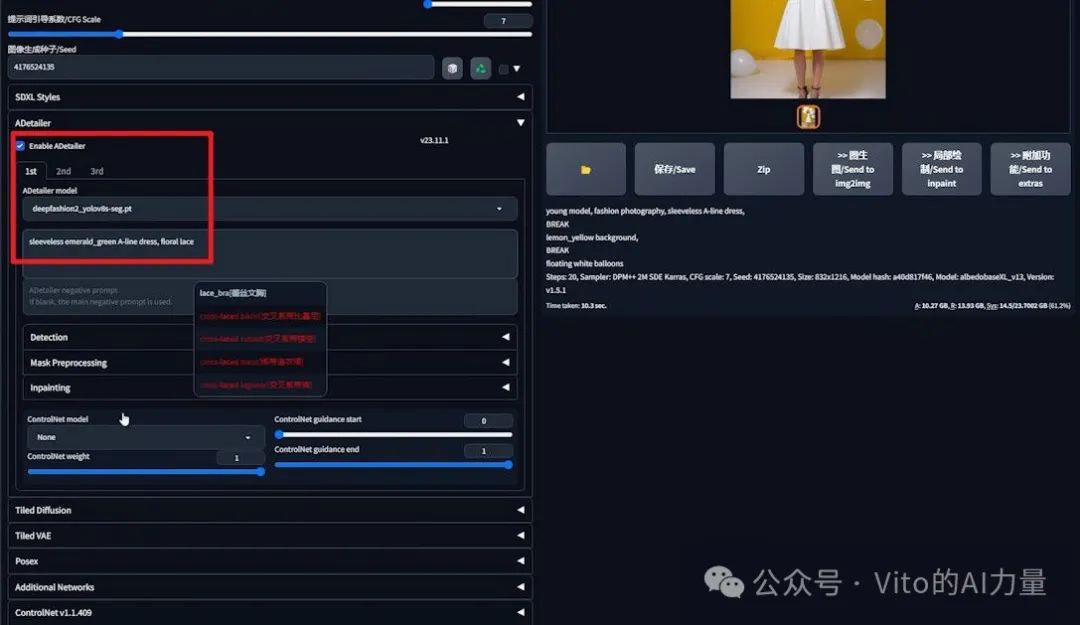
2️⃣ 应用DeepFashion处理衣服:
- 固定随机种子。
- 启用Adetailer插件,选择DeepFashion模型。
- 添加描述:“祖母绿无袖 A 字裙,花朵蕾丝”。
- 调整“Inpaint denoising strength”至0.7,然后生成。
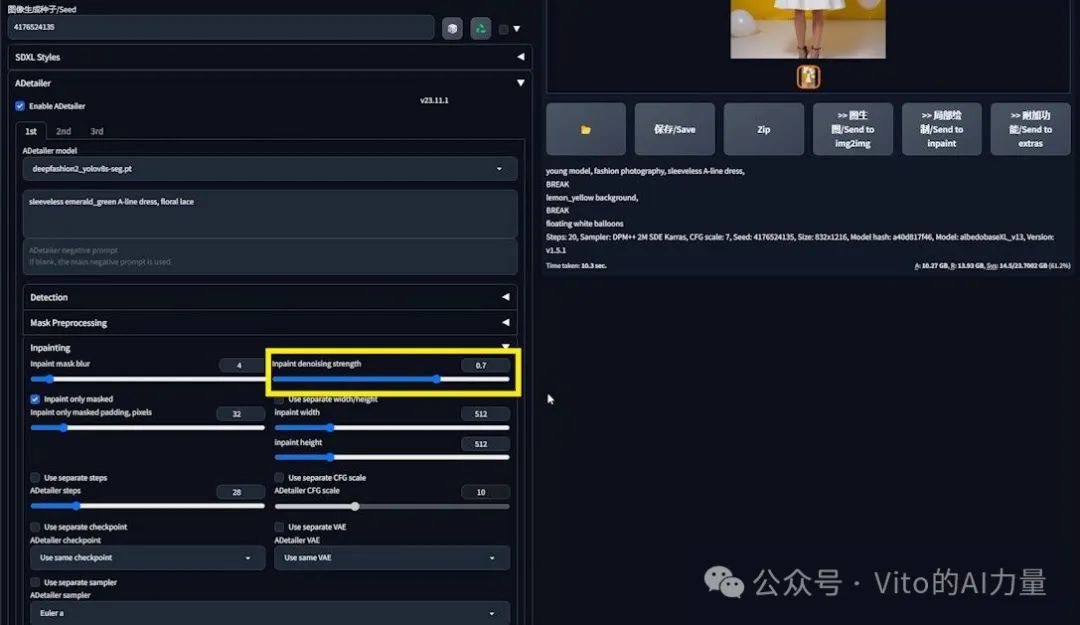
- 观察到裙子颜色主要仍是白色。

3️⃣ 增强效果:
- 提高“Inpaint denoising strength”至0.8,再生成。

- 尝试使用更高的0.9值,裙子变为祖母绿色,但边缘仍有白色残留。

4️⃣ 微调蒙版处理:
- 调整“Mask Preprocessing”中的“Mask erosion/dilation”参数。
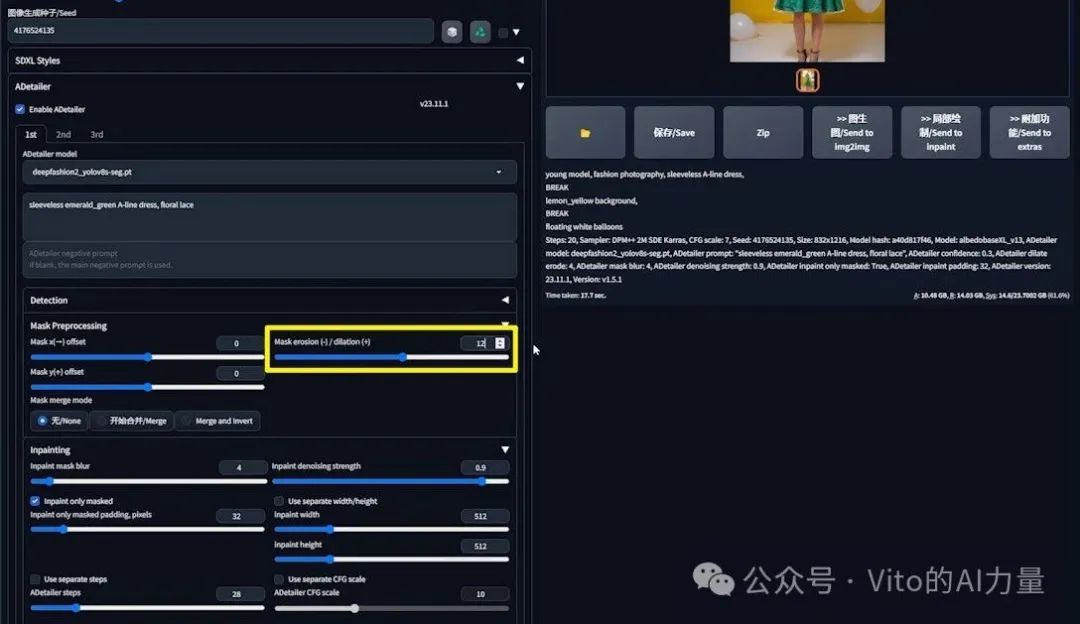
- 将蒙版扩张设为12,生成图片,白边减少。

- 进一步调整至16,几乎消除了所有白边。

# 结论与应用
DeepFashion作为Adetailer中的一个独特模型,可以独立处理服装,从而避免提示词污染问题,同时为服装增加细节。它不仅支持SD1.5模型,还支持SDXL模型。当你需要处理服装时,DeepFashion是一个值得考虑的选择。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2663
2663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









