







文章目录
简介
Transformer 模型中的 Encoder 层主要负责将输入序列进行编码,将输入序列中的每个词或标记转换为其对应的向量表示,并且捕获输入序列中的语义和关系。
具体来说,Transformer Encoder 层的作用包括:
-
词嵌入(Word Embedding):将输入序列中的每个词或标记映射为其对应的词嵌入向量。这些词嵌入向量包含了词语的语义信息,并且可以在模型中进行学习。
-
位置编码(Positional Encoding):因为 Transformer 模型不包含任何关于序列顺序的信息,为了将位置信息引入模型,需要添加位置编码。位置编码是一种特殊的向量,用于表示输入序列中每个词的位置信息,以便模型能够区分不同位置的词。
-
多头自注意力机制(Multi-Head Self-Attention):自注意力机制允许模型在处理每个词时,同时考虑到输入序列中所有其他词之间的关系。多头自注意力机制通过将输入进行多次线性变换并计算多组注意力分数,从而允许模型在不同的表示子空间中学习到不同的语义信息。
-
残差连接(Residual Connection):为了减轻梯度消失和加速训练,Transformer Encoder 层使用了残差连接。残差连接允许模型直接学习到输入序列的增量变换,而不是完全替代原始输入。
-
层归一化(Layer Normalization):在残差连接后应用层归一化,有助于提高模型的训练稳定性,加快训练速度。
Transformer Encoder 层的主要作用是将输入序列转换为其对应的向量表示,并且捕获输入序列中的语义和位置信息,以便后续的模型能够更好地理解和处理输入序列。
前面我们已经详解了三个点,词嵌入(Word Embedding),位置编码(Positional Encoding),多头自注意力机制(Multi-Head Self-Attention),这里详解Encoder结构的其他部分。
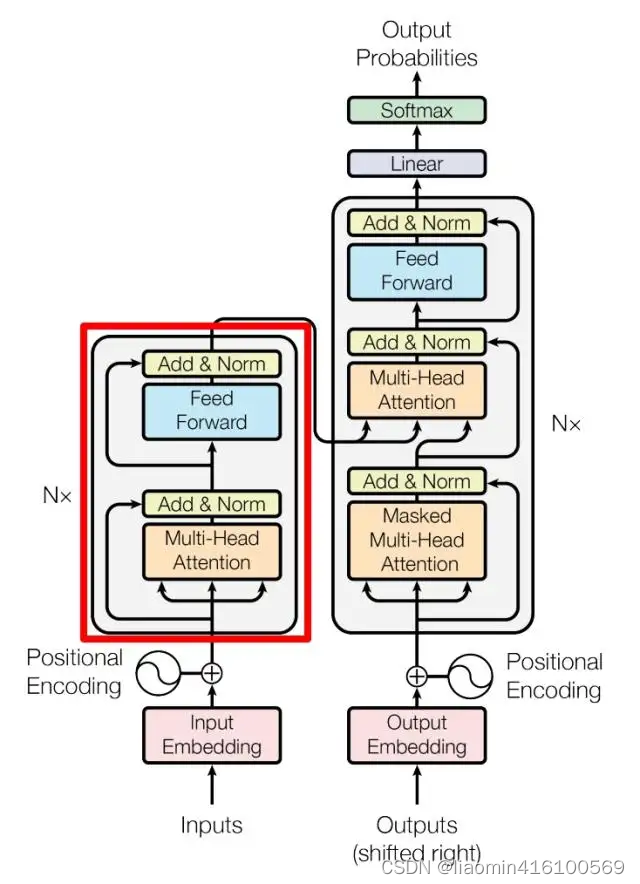
上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。之前了解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分。
基础知识
归一化
归一化是将数据转换为具有统一尺度的过程,常用于机器学习、数据挖掘和统计分析中。归一化可以确保不同特征或变量之间具有相似的数值范围,有助于提高模型的性能和收敛速度。
作用
让我用一个简单的例子来说明归一化的作用。
假设你有一个数据集,其中包含两个特征:年龄和收入。年龄的范围是 0 到 100 岁,而收入的范围是 1000 到 100000 美元。这两个特征的范围差异很大。
现在,你想要使用这些特征来训练一个机器学习模型,比如线性回归模型,来预测一个人是否会购买某种产品。由于特征的范围差异较大,这可能会导致某些问题:
收入的范围比年龄大得多,这可能会使得模型过度关注收入而忽略年龄,因为收入的变化可能会对预测产生更大的影响。
模型可能会受到数值范围的影响,而不是特征本身的重要性。
这时候,归一化就可以派上用场了。通过归一化,你可以将不同特征的值缩放到相似的范围内,从而消除数值范围差异带来的影响。比如,你可以将年龄和收入都缩放到 0 到 1 之间的范围内,或者使用其他归一化方法,如标准化 (standardization)。
通过归一化,你可以确保模型不会因为特征值的范围差异而偏向某个特定的特征,而是可以更平衡地利用所有的特征信息来进行预测。
常用归一化
下面是几种常用的归一化方式及其公式:
- Min-Max 归一化:
Min-Max 归一化将数据线性映射到一个指定的范围内,通常是 [0, 1] 或 [-1, 1]。其公式如下:
[ X norm = X − X min X max − X min ] [X_{\text{norm}} = \frac{ {X - X_{\text{min}}}}{ {X_{\text{max}} - X_{\text{min}}}}] [Xnorm=Xmax−XminX−Xmin]
其中, ( X norm ) (X_{\text{norm}}) (Xnorm) 是归一化后的数据,(X) 是原始数据, ( X min ) (X_{\text{min}}) (Xmin) 和 ( X max ) (X_{\text{max}}) (Xmax)分别是数据的最小值和最大值。
- Z-Score 标准化:
Z-Score 标准化将数据转换为均值为 0,标准差为 1 的正态分布。其公式如下:
[ X norm = X − μ σ ] [X_{\text{norm}} = \frac{ {X - \mu}}{ {\sigma}}]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









