



 HDFS是Hadoop的分布式文件系统,设计用于处理大规模数据,提供高容错性和高吞吐量。系统由NameNode和DataNode组成,采用主从架构,文件被分割成块并复制多份以确保可靠性。HDFS支持‘写一次读多次’的数据模型,并利用机架感知策略优化数据分布和容错性。
HDFS是Hadoop的分布式文件系统,设计用于处理大规模数据,提供高容错性和高吞吐量。系统由NameNode和DataNode组成,采用主从架构,文件被分割成块并复制多份以确保可靠性。HDFS支持‘写一次读多次’的数据模型,并利用机架感知策略优化数据分布和容错性。
HDFS简介
Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)具有高容错性,并能部署在商用服务器上,提供高吞吐量的数据访问,十分适用于大数据应用。HDFS的设计初衷和假设主要有以下几点:
高容错性:硬件故障是常态而不是异常。HDFS集群可以由成百上千台物理服务器组成,每一台都存储了文件系统的一部分数据。这意味着HDFS中的某一部分总有可能出现故障。因此,HDFS的设计目标就包括及时的检测故障并从中恢复。
高吞吐、高延时:HDFS更多用于数据批处理而不是交互式处理,即强调数据访问的高吞吐量,但响应速度较低。
大数据集:HDFS存储的通常为大数据集,从几个GB到几个TB不等,这样才能充分体现HDFS的优势。一个HDFS集群可以支持千万量级的文件数量。
“写一次读多次”的数据模型:一个文件一旦创建,只能在文件末尾追加或截断操作,但是不支持在文件任意位置做修改。这一简单的数据模型简化了数据一致性的问题,并且提升了数据处理的吞吐量。
计算本地化:使得数据处理发生在靠近数据存储的节点能够减小网络开销并提高系统吞吐量,而不是将数据迁移到某个应用再进行处理。
HDFS架构
HDFS采用主从架构,由一个命名节点(NameNode)和多个数据节点(DataNode)组成。命名节点用于管理文件系统的命名空间和文件的访问权限等等。数据节点用于管理它们所运行的节点的数据存储,通常每个节点运行一个数据节点进程。HDFS暴露给用户的接口只是一个文件的命名空间。就内部机制而言,一个文件会分割成多个文件块(block),每个文件块又会存储在多个数据节点。命名节点仅仅执行文件系统的命名空间操作,如打开、关闭和重命名文件和文件夹,并且决定文件块与数据节点的映射关系。而数据节点会接受命名节点的指令,真正响应客户端的文件读写请求,做文件块的创建、删除和拷贝。HDFS架构如下图所示:
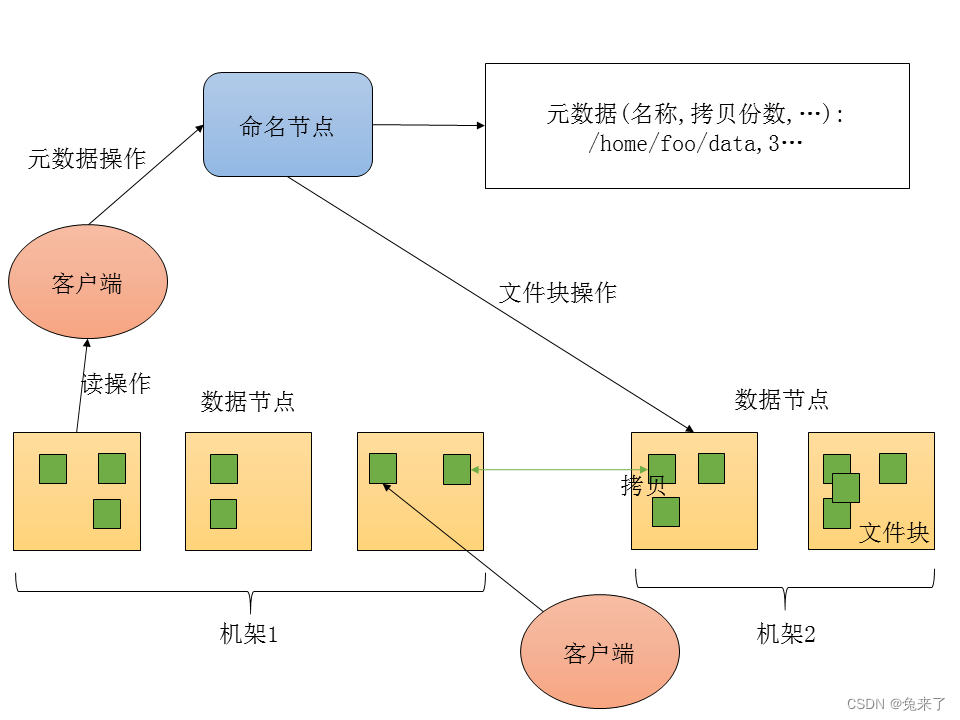
HDFS与传统文件系统的组织方式类似,都是层级式的,即可以在文件夹中创建子文件夹或存储文件。用户可以创建、删除、移动和重命名文件,但是暂时不支持软连接和硬连接。HDFS中可以限制用户占用空间和访问权限。
HDFS文件块
HDFS能够可靠的在集群中存储大数据集,每个文件存储成多个文件块,每个文件块拷贝多份以达到高容错性。文件块的大小和拷贝份数都可以配置。命名节点决定所有文件拷贝的映射。数据节点会周期性发送心跳和文件块报告给命名节点,心跳表明数据节点运行正常,文件块报告包含数据节点中的所有文件块列表。
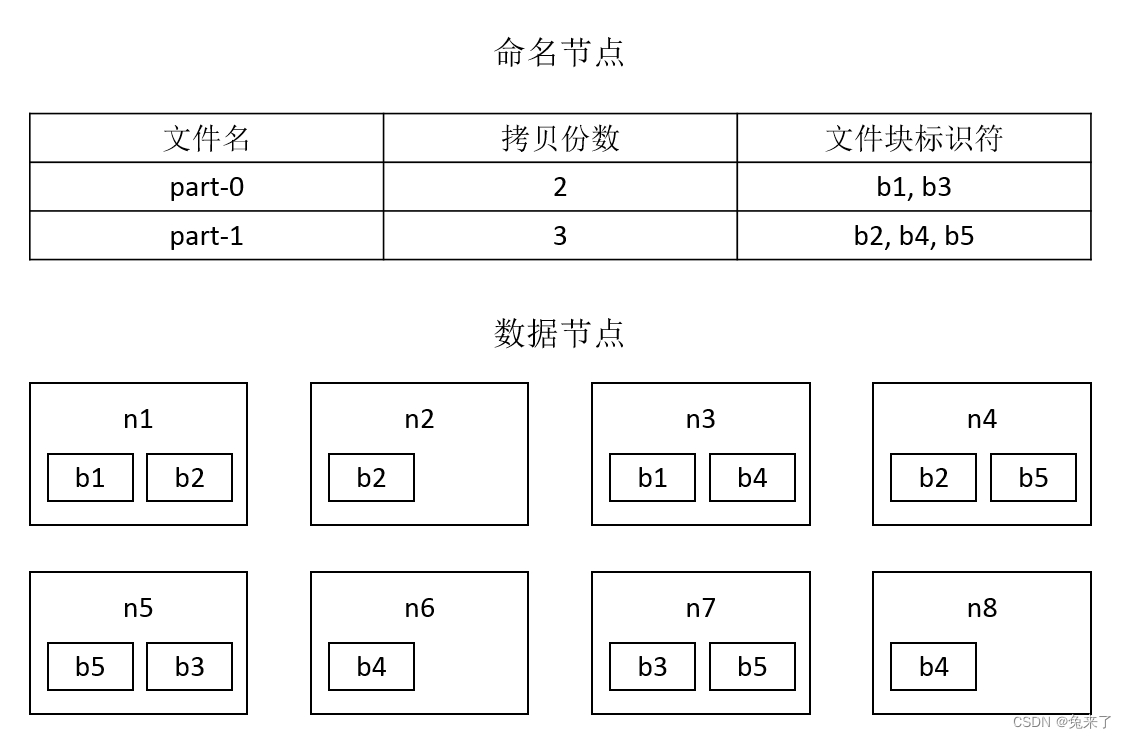
如下图所示,文件part-0设置为拷贝2份,有2个文件块,分别为b1和b3,其中
文件块b1分别存储在节点n1和n3上;
文件块b3分别存储在节点n5和n7上。
文件part-1设置为拷贝3份,有3个文件块,分别为b2、b4和b5,其中
文件块b2分别存储在节点n1、n2和n4上;
文件块b4分别存储在节点n3、n6和n8上;
文件块b5分别存储在节点n4、n5和n7上。
数据拷贝的放置位置对于HDFS的可靠性和性能至关重要。HDFS采用了一种叫做机架感知的策略。数据中心通常放置了多个机架(也称为机柜),每个机架中又放置了多台物理服务器,同一个机架中的服务器共享同一个交换机。通常情况下,同一个机架内的网络带宽远大于不同机架之间的网络带宽,意味着数据在同一个机架的不同服务器之间的传输速度要远远超过在不同机架的不同服务器之间。
命名节点能够检测每个数据节点所在的机架。一种简单但并非最佳的策略,是将数据拷贝放置在不同的机架上,这样可以放置整个机架故障导致的数据丢失,并能在读取数据时充分利用多个机架的网络带宽。对于拷贝份数为3的情况,HDFS采取的策略是,将2份拷贝放置在同一个机架的不同数据节点,第3份拷贝放置在另一个机架的数据节点。
命名节点不会将2份拷贝放置在同一个数据节点上,因此最大拷贝份数为集群中数据节点的数量。
HDFS文件块的大小和拷贝份数可以在配置文件hdfs-size.xml中设置,
dfs.blocksize表示文件块的大小,默认为128m,即128 MB;
dfs.replication表示文件块的拷贝份数,默认为3。
HDFS常用操作
HDFS提供类似Shell的命令操作文件,形如hdfs dfs -<子命令>,具体语法可以参考文档https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html。
HDFS中也可以使用相对路径,当前工作目录为HDFS上的家目录,即/user/<用户名>。
HDFS中常用子命令如下所示。
-appendToFile:追加写入文件;
-cat:显示文件内容;
-cp在HDFS中复制文件(夹);
-get从HDFS复制文件(夹)到本地文件系统;
-ls显示文件(夹)统计信息;
-mv在HDFS中移动文件(夹);
-mkdir创建文件夹;
-put从本地文件系统复制文件(夹)到HDFS;
-rm删除文件(夹)。
使用hdfs dfs -mkdir命令在HDFS上创建文件夹test,这里使用了相对路径,其绝对路径为/user/<用户名>/test。
hdfs dfs -mkdir test
使用hdfs dfs -put命令从本地文件系统复制文件(夹)到HDFS,其中
第1个参数表示本地源文件,文件名可以使用通配符;
第2个参数表示HDFS目标文件夹。
这里将/opt/data/novels本地文件夹中的所有文件复制到HDFS的test文件夹中。
hdfs dfs -put /opt/data/novels/* test
使用hdfs dfs -ls命令显示文件(夹)统计信息。
对于文件,显示的统计信息格式为
<权限> <拷贝份数> <用户名> <用户组名> <文件大小> <修改日期> <修改时间> <文件名>
对于文件夹,显示的统计信息格式为
<权限> <用户名> <用户组名> <修改日期> <修改时间> <文件夹名>
hdfs dfs -ls test
Found 3 items
-rw-r–r-- 1 root hadoop 389386 2018-09-28 11:52 test/Woolf_Lighthouse_1927.txt
-rw-r–r-- 1 root hadoop 952293 2018-09-28 11:52 test/Woolf_Night_1919.txt
-rw-r–r-- 1 root hadoop 730235 2018-09-28 11:52 test/Woolf_Years_1937.txt
使用hdfs dfs -cat命令显示文件内容。由于内容较多,在命令末尾添加管道和head命令仅显示前几行。
hdfs dfs -cat test/Woolf_Years_1937.txt | head
The Years
1880
It was an uncertain spring. The weather, perpetually changing,
sent clouds of blue and of purple flying over the land. In the
country farmers, looking at the fields, were apprehensive; in
London umbrellas were opened and then shut by people looking up at
the sky. But in April such weather was to be expected. Thousands
使用hdfs dfs -cp命令在HDFS中复制文件(夹),其中
第1个参数表示HDFS源文件(夹);
第2个参数表示HDFS目标文件(夹)。
hdfs dfs -cp test/Woolf_Years_1937.txt test/Woolf_Years_1937_copy.txt
使用hdfs dfs -get命令从HDFS复制文件(夹)到本地文件系统。
hdfs dfs -get test/Woolf_Years_1937_copy.txt
使用hdfs dfs -rm命令删除文件(夹),选项-r表示删除文件夹和文件夹下的所有文件。
hdfs dfs -rm test/Woolf_Years_1937_copy.txt
hdfs dfs -rm -r test

















 3470
3470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









